 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
Vript: A Video Is Worth Thousands of Words
Jun 10, 2024
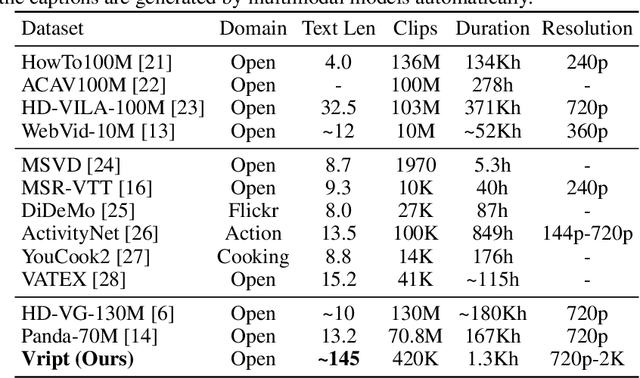
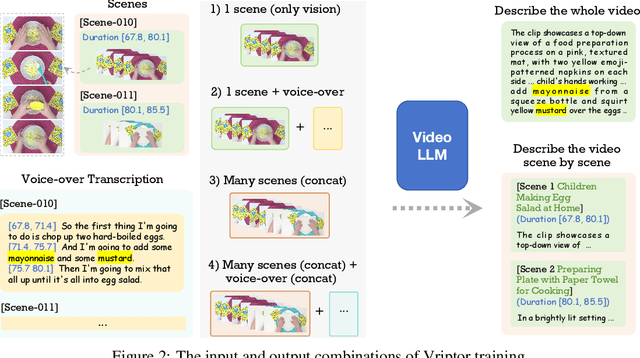
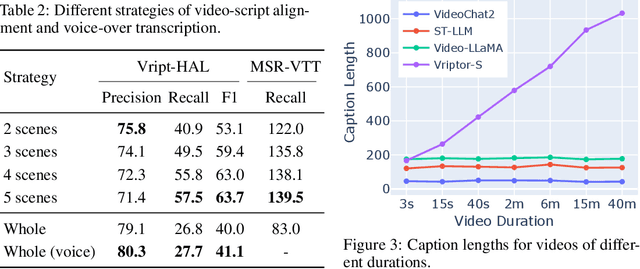
Advancements in multimodal learning, particularly in video understanding and generation, require high-quality video-text datasets for improved model performance. Vript addresses this issue with a meticulously annotated corpus of 12K high-resolution videos, offering detailed, dense, and script-like captions for over 420K clips. Each clip has a caption of ~145 words, which is over 10x longer than most video-text datasets. Unlike captions only documenting static content in previous datasets, we enhance video captioning to video scripting by documenting not just the content, but also the camera operations, which include the shot types (medium shot, close-up, etc) and camera movements (panning, tilting, etc). By utilizing the Vript, we explore three training paradigms of aligning more text with the video modality rather than clip-caption pairs. This results in Vriptor, a top-performing video captioning model among open-source models, comparable to GPT-4V in performance. Vriptor is also a powerful model capable of end-to-end generation of dense and detailed captions for long videos. Moreover, we introduce Vript-Hard, a benchmark consisting of three video understanding tasks that are more challenging than existing benchmarks: Vript-HAL is the first benchmark evaluating action and object hallucinations in video LLMs, Vript-RR combines reasoning with retrieval resolving question ambiguity in long-video QAs, and Vript-ERO is a new task to evaluate the temporal understanding of events in long videos rather than actions in short videos in previous works. All code, models, and datasets are available in https://github.com/mutonix/Vript.
Improving Audio-Visual Segmentation with Bidirectional Generation
Aug 16, 2023The aim of audio-visual segmentation (AVS) is to precisely differentiate audible objects within videos down to the pixel level. Traditional approaches often tackle this challenge by combining information from various modalities, where the contribution of each modality is implicitly or explicitly modeled. Nevertheless, the interconnections between different modalities tend to be overlooked in audio-visual modeling. In this paper, inspired by the human ability to mentally simulate the sound of an object and its visual appearance, we introduce a bidirectional generation framework. This framework establishes robust correlations between an object's visual characteristics and its associated sound, thereby enhancing the performance of AVS. To achieve this, we employ a visual-to-audio projection component that reconstructs audio features from object segmentation masks and minimizes reconstruction errors. Moreover, recognizing that many sounds are linked to object movements, we introduce an implicit volumetric motion estimation module to handle temporal dynamics that may be challenging to capture using conventional optical flow methods. To showcase the effectiveness of our approach, we conduct comprehensive experiments and analyses on the widely recognized AVSBench benchmark. As a result, we establish a new state-of-the-art performance level in the AVS benchmark, particularly excelling in the challenging MS3 subset which involves segmenting multiple sound sources. To facilitate reproducibility, we plan to release both the source code and the pre-trained model.
Scaling TransNormer to 175 Billion Parameters
Jul 27, 2023We present TransNormerLLM, the first linear attention-based Large Language Model (LLM) that outperforms conventional softmax attention-based models in terms of both accuracy and efficiency. TransNormerLLM evolves from the previous linear attention architecture TransNormer by making advanced modifications that include positional embedding, linear attention acceleration, gating mechanism, tensor normalization, inference acceleration and stabilization. Specifically, we use LRPE together with an exponential decay to avoid attention dilution issues while allowing the model to retain global interactions between tokens. Additionally, we propose Lightning Attention, a cutting-edge technique that accelerates linear attention by more than twice in runtime and reduces memory usage by a remarkable four times. To further enhance the performance of TransNormer, we leverage a gating mechanism to smooth training and a new tensor normalization scheme to accelerate the model, resulting in an impressive acceleration of over 20%. Furthermore, we have developed a robust inference algorithm that ensures numerical stability and consistent inference speed, regardless of the sequence length, showcasing superior efficiency during both training and inference stages. Scalability is at the heart of our model's design, enabling seamless deployment on large-scale clusters and facilitating expansion to even more extensive models, all while maintaining outstanding performance metrics. Rigorous validation of our model design is achieved through a series of comprehensive experiments on our self-collected corpus, boasting a size exceeding 6TB and containing over 2 trillion tokens. To ensure data quality and relevance, we implement a new self-cleaning strategy to filter our collected data. Our pre-trained models will be released to foster community advancements in efficient LLMs.
Linearized Relative Positional Encoding
Jul 18, 2023Relative positional encoding is widely used in vanilla and linear transformers to represent positional information. However, existing encoding methods of a vanilla transformer are not always directly applicable to a linear transformer, because the latter requires a decomposition of the query and key representations into separate kernel functions. Nevertheless, principles for designing encoding methods suitable for linear transformers remain understudied. In this work, we put together a variety of existing linear relative positional encoding approaches under a canonical form and further propose a family of linear relative positional encoding algorithms via unitary transformation. Our formulation leads to a principled framework that can be used to develop new relative positional encoding methods that preserve linear space-time complexity. Equipped with different models, the proposed linearized relative positional encoding (LRPE) family derives effective encoding for various applications. Experiments show that compared with existing methods, LRPE achieves state-of-the-art performance in language modeling, text classification, and image classification. Meanwhile, it emphasizes a general paradigm for designing broadly more relative positional encoding methods that are applicable to linear transformers. The code is available at https://github.com/OpenNLPLab/Lrpe.
Toeplitz Neural Network for Sequence Modeling
May 08, 2023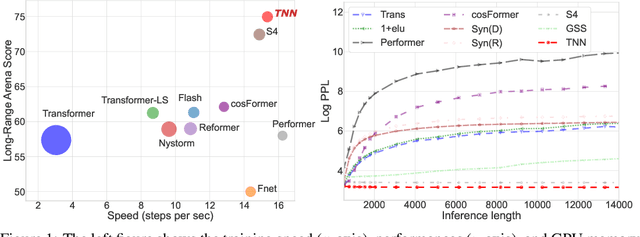

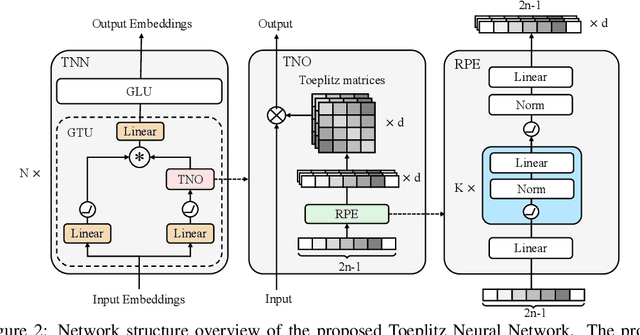
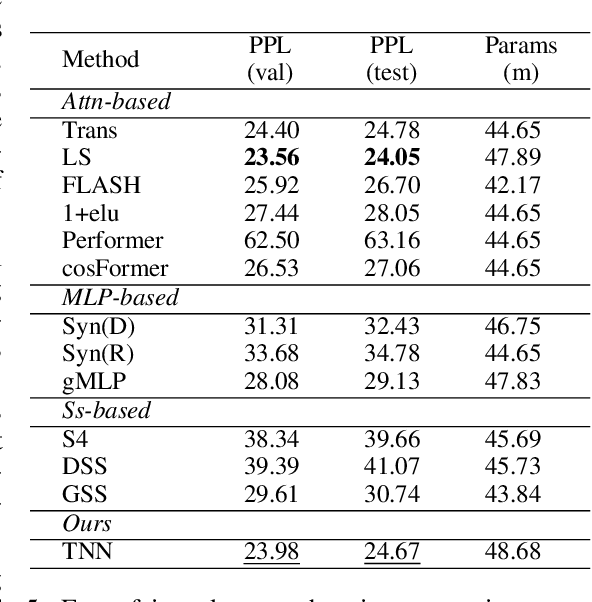
Sequence modeling has important applications in natural language processing and computer vision. Recently, the transformer-based models have shown strong performance on various sequence modeling tasks, which rely on attention to capture pairwise token relations, and position embedding to inject positional information. While showing good performance, the transformer models are inefficient to scale to long input sequences, mainly due to the quadratic space-time complexity of attention. To overcome this inefficiency, we propose to model sequences with a relative position encoded Toeplitz matrix and use a Toeplitz matrix-vector production trick to reduce the space-time complexity of the sequence modeling to log linear. A lightweight sub-network called relative position encoder is proposed to generate relative position coefficients with a fixed budget of parameters, enabling the proposed Toeplitz neural network to deal with varying sequence lengths. In addition, despite being trained on 512-token sequences, our model can extrapolate input sequence length up to 14K tokens in inference with consistent performance. Extensive experiments on autoregressive and bidirectional language modeling, image modeling, and the challenging Long-Range Arena benchmark show that our method achieves better performance than its competitors in most downstream tasks while being significantly faster. The code is available at https://github.com/OpenNLPLab/Tnn.
Fine-grained Audible Video Description
Mar 27, 2023
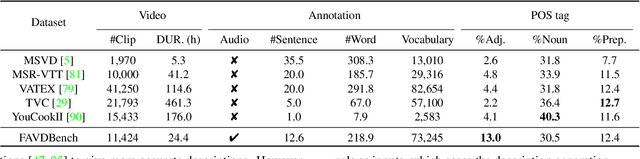
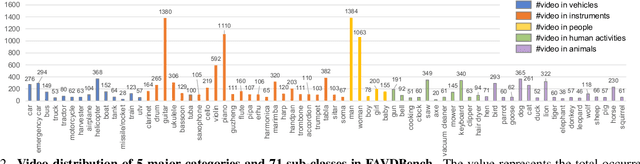
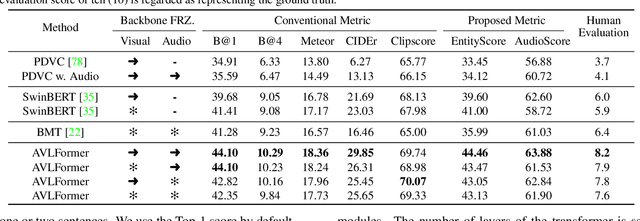
We explore a new task for audio-visual-language modeling called fine-grained audible video description (FAVD). It aims to provide detailed textual descriptions for the given audible videos, including the appearance and spatial locations of each object, the actions of moving objects, and the sounds in videos. Existing visual-language modeling tasks often concentrate on visual cues in videos while undervaluing the language and audio modalities. On the other hand, FAVD requires not only audio-visual-language modeling skills but also paragraph-level language generation abilities. We construct the first fine-grained audible video description benchmark (FAVDBench) to facilitate this research. For each video clip, we first provide a one-sentence summary of the video, ie, the caption, followed by 4-6 sentences describing the visual details and 1-2 audio-related descriptions at the end. The descriptions are provided in both English and Chinese. We create two new metrics for this task: an EntityScore to gauge the completeness of entities in the visual descriptions, and an AudioScore to assess the audio descriptions. As a preliminary approach to this task, we propose an audio-visual-language transformer that extends existing video captioning model with an additional audio branch. We combine the masked language modeling and auto-regressive language modeling losses to optimize our model so that it can produce paragraph-level descriptions. We illustrate the efficiency of our model in audio-visual-language modeling by evaluating it against the proposed benchmark using both conventional captioning metrics and our proposed metrics. We further put our benchmark to the test in video generation models, demonstrating that employing fine-grained video descriptions can create more intricate videos than using captions.
Linear Video Transformer with Feature Fixation
Oct 15, 2022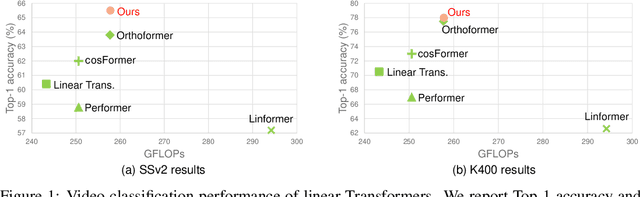
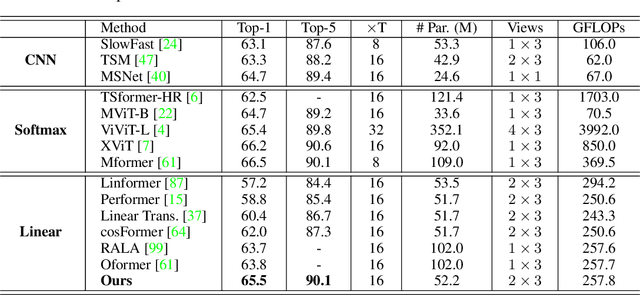

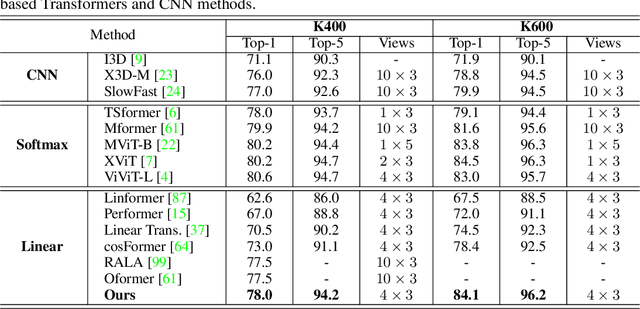
Vision Transformers have achieved impressive performance in video classification, while suffering from the quadratic complexity caused by the Softmax attention mechanism. Some studies alleviate the computational costs by reducing the number of tokens in attention calculation, but the complexity is still quadratic. Another promising way is to replace Softmax attention with linear attention, which owns linear complexity but presents a clear performance drop. We find that such a drop in linear attention results from the lack of attention concentration on critical features. Therefore, we propose a feature fixation module to reweight the feature importance of the query and key before computing linear attention. Specifically, we regard the query, key, and value as various latent representations of the input token, and learn the feature fixation ratio by aggregating Query-Key-Value information. This is beneficial for measuring the feature importance comprehensively. Furthermore, we enhance the feature fixation by neighborhood association, which leverages additional guidance from spatial and temporal neighbouring tokens. The proposed method significantly improves the linear attention baseline and achieves state-of-the-art performance among linear video Transformers on three popular video classification benchmarks. With fewer parameters and higher efficiency, our performance is even comparable to some Softmax-based quadratic Transformers.