 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
Nov 13, 2025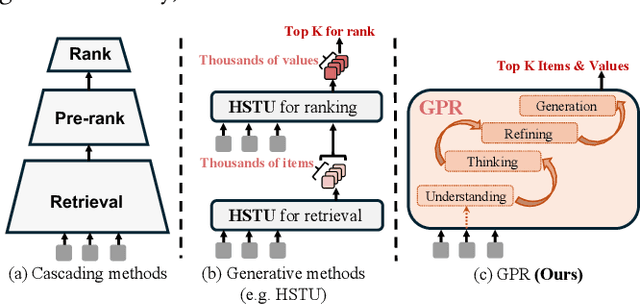
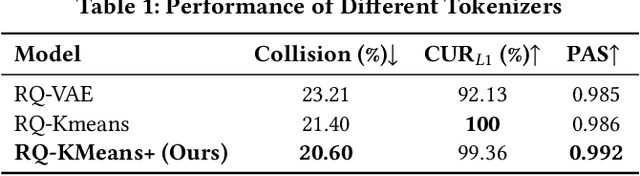
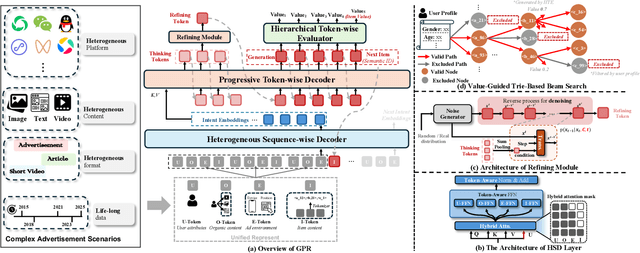
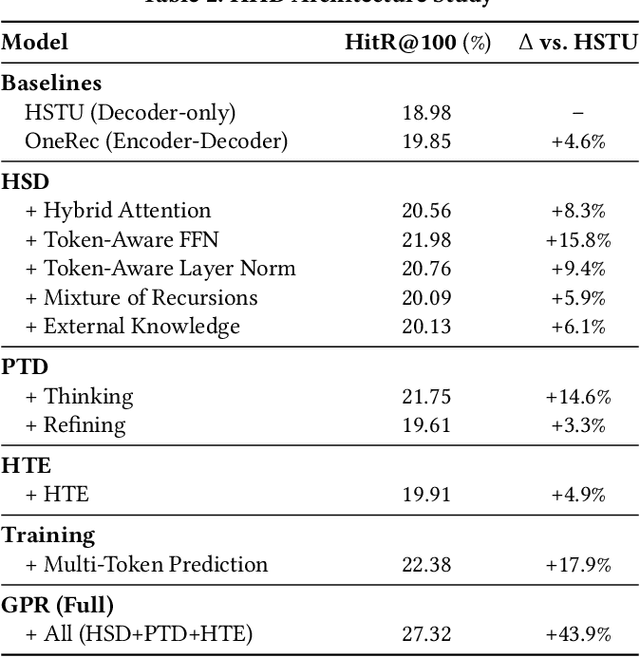
As an intelligent infrastructure connecting users with commercial content, advertising recommendation systems play a central role in information flow and value creation within the digital economy. However, existing multi-stage advertising recommendation systems suffer from objective misalignment and error propagation, making it difficult to achieve global optimality, while unified generative recommendation models still struggle to meet the demands of practical industrial applications. To address these issues, we propose GPR (Generative Pre-trained Recommender), the first one-model framework that redefines advertising recommendation as an end-to-end generative task, replacing the traditional cascading paradigm with a unified generative approach. To realize GPR, we introduce three key innovations spanning unified representation, network architecture, and training strategy. First, we design a unified input schema and tokenization method tailored to advertising scenarios, mapping both ads and organic content into a shared multi-level semantic ID space, thereby enhancing semantic alignment and modeling consistency across heterogeneous data. Second, we develop the Heterogeneous Hierarchical Decoder (HHD), a dual-decoder architecture that decouples user intent modeling from ad generation, achieving a balance between training efficiency and inference flexibility while maintaining strong modeling capacity. Finally, we propose a multi-stage joint training strategy that integrates Multi-Token Prediction (MTP), Value-Aware Fine-Tuning and the Hierarchy Enhanced Policy Optimization (HEPO) algorithm, forming a complete generative recommendation pipeline that unifies interest modeling, value alignment, and policy optimization. GPR has been fully deployed in the Tencent Weixin Channels advertising system, delivering significant improvements in key business metrics including GMV and CTCVR.
S2FGL: Spatial Spectral Federated Graph Learning
Jul 03, 2025



Federated Graph Learning (FGL) combines the privacy-preserving capabilities of federated learning (FL) with the strong graph modeling capability of Graph Neural Networks (GNNs). Current research addresses subgraph-FL only from the structural perspective, neglecting the propagation of graph signals on spatial and spectral domains of the structure. From a spatial perspective, subgraph-FL introduces edge disconnections between clients, leading to disruptions in label signals and a degradation in the class knowledge of the global GNN. From a spectral perspective, spectral heterogeneity causes inconsistencies in signal frequencies across subgraphs, which makes local GNNs overfit the local signal propagation schemes. As a result, spectral client drifts occur, undermining global generalizability. To tackle the challenges, we propose a global knowledge repository to mitigate label signal disruption and a frequency alignment to address spectral client drifts. The combination of spatial and spectral strategies forms our framework S2FGL. Extensive experiments on multiple datasets demonstrate the superiority of S2FGL. The code is available at https://github.com/Wonder7racer/S2FGL.git.
ScalingNote: Scaling up Retrievers with Large Language Models for Real-World Dense Retrieval
Nov 24, 2024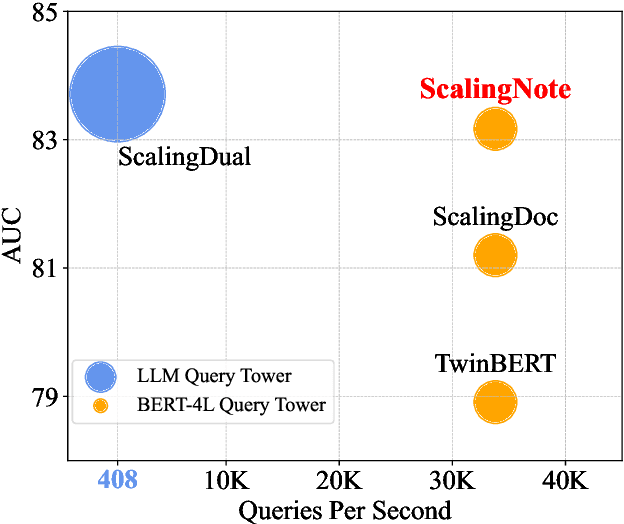
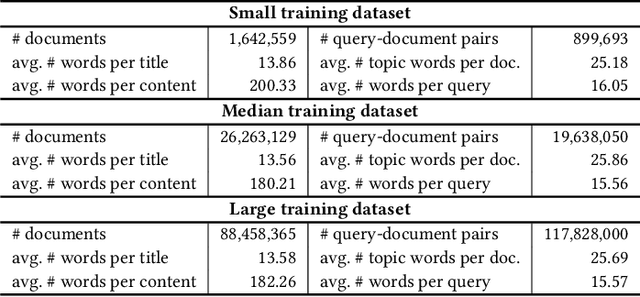
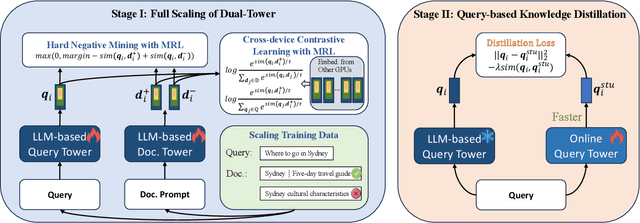
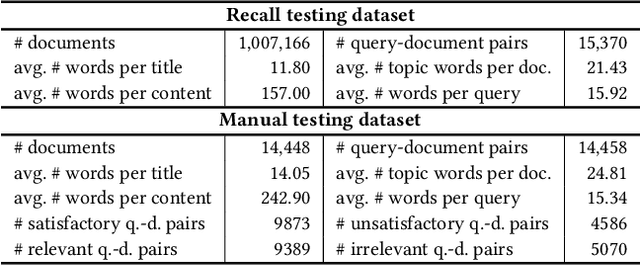
Dense retrieval in most industries employs dual-tower architectures to retrieve query-relevant documents. Due to online deployment requirements, existing real-world dense retrieval systems mainly enhance performance by designing negative sampling strategies, overlooking the advantages of scaling up. Recently, Large Language Models (LLMs) have exhibited superior performance that can be leveraged for scaling up dense retrieval. However, scaling up retrieval models significantly increases online query latency. To address this challenge, we propose ScalingNote, a two-stage method to exploit the scaling potential of LLMs for retrieval while maintaining online query latency. The first stage is training dual towers, both initialized from the same LLM, to unlock the potential of LLMs for dense retrieval. Then, we distill only the query tower using mean squared error loss and cosine similarity to reduce online costs. Through theoretical analysis and comprehensive offline and online experiments, we show the effectiveness and efficiency of ScalingNote. Our two-stage scaling method outperforms end-to-end models and verifies the scaling law of dense retrieval with LLMs in industrial scenarios, enabling cost-effective scaling of dense retrieval systems. Our online method incorporating ScalingNote significantly enhances the relevance between retrieved documents and queries.
Vript: A Video Is Worth Thousands of Words
Jun 10, 2024
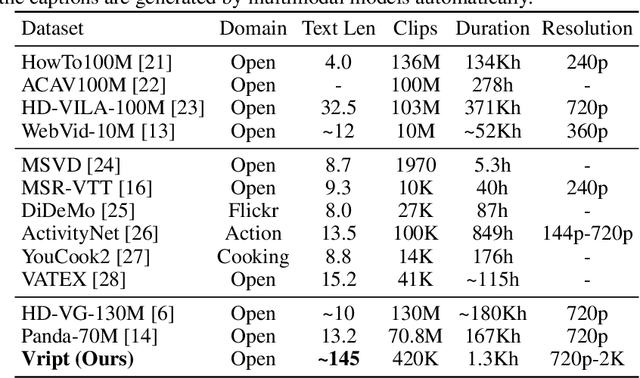
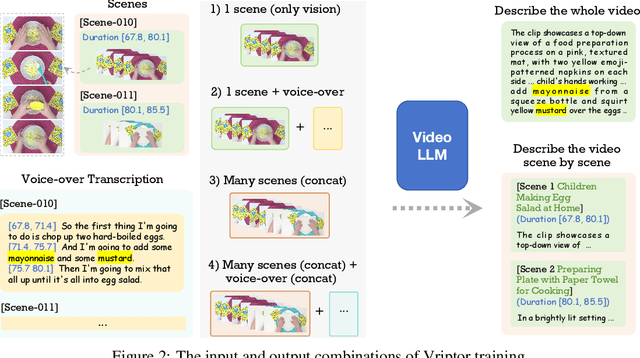
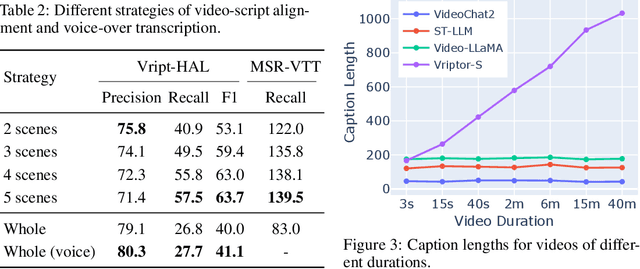
Advancements in multimodal learning, particularly in video understanding and generation, require high-quality video-text datasets for improved model performance. Vript addresses this issue with a meticulously annotated corpus of 12K high-resolution videos, offering detailed, dense, and script-like captions for over 420K clips. Each clip has a caption of ~145 words, which is over 10x longer than most video-text datasets. Unlike captions only documenting static content in previous datasets, we enhance video captioning to video scripting by documenting not just the content, but also the camera operations, which include the shot types (medium shot, close-up, etc) and camera movements (panning, tilting, etc). By utilizing the Vript, we explore three training paradigms of aligning more text with the video modality rather than clip-caption pairs. This results in Vriptor, a top-performing video captioning model among open-source models, comparable to GPT-4V in performance. Vriptor is also a powerful model capable of end-to-end generation of dense and detailed captions for long videos. Moreover, we introduce Vript-Hard, a benchmark consisting of three video understanding tasks that are more challenging than existing benchmarks: Vript-HAL is the first benchmark evaluating action and object hallucinations in video LLMs, Vript-RR combines reasoning with retrieval resolving question ambiguity in long-video QAs, and Vript-ERO is a new task to evaluate the temporal understanding of events in long videos rather than actions in short videos in previous works. All code, models, and datasets are available in https://github.com/mutonix/Vript.
From Image to Video, what do we need in multimodal LLMs?
Apr 18, 2024Multimodal Large Language Models (MLLMs) have demonstrated profound capabilities in understanding multimodal information, covering from Image LLMs to the more complex Video LLMs. Numerous studies have illustrated their exceptional cross-modal comprehension. Recently, integrating video foundation models with large language models to build a comprehensive video understanding system has been proposed to overcome the limitations of specific pre-defined vision tasks. However, the current advancements in Video LLMs tend to overlook the foundational contributions of Image LLMs, often opting for more complicated structures and a wide variety of multimodal data for pre-training. This approach significantly increases the costs associated with these methods.In response to these challenges, this work introduces an efficient method that strategically leverages the priors of Image LLMs, facilitating a resource-efficient transition from Image to Video LLMs. We propose RED-VILLM, a Resource-Efficient Development pipeline for Video LLMs from Image LLMs, which utilizes a temporal adaptation plug-and-play structure within the image fusion module of Image LLMs. This adaptation extends their understanding capabilities to include temporal information, enabling the development of Video LLMs that not only surpass baseline performances but also do so with minimal instructional data and training resources. Our approach highlights the potential for a more cost-effective and scalable advancement in multimodal models, effectively building upon the foundational work of Image LLMs.