 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARD: Self-Paced Curriculum for RL Alignment via Integrating Reward Dynamics and Data Utility
Apr 09, 2026The evolution of Large Language Models (LLMs) is shifting the focus from single, verifiable tasks toward complex, open-ended real-world scenarios, imposing significant challenges on the post-training phase. In these settings, the scale and complexity of reward systems have grown significantly, transitioning toward multi-objective formulations that encompass a comprehensive spectrum of model capabilities and application contexts. However, traditional methods typically rely on fixed reward weights, ignoring non-stationary learning dynamics and struggling with data heterogeneity across dimensions. To address these issues, we propose SPARD, a framework that establishes an automated, self-paced curriculum by perceiving learning progress to dynamically adjust multi-objective reward weights and data importance, thereby synchronizing learning intent with data utility for optimal performance. Extensive experiments across multiple benchmarks demonstrate that SPARD significantly enhances model capabilities across all domains.
Aligning Large Language Models with Searcher Preferences
Mar 11, 2026The paradigm shift from item-centric ranking to answer-centric synthesis is redefining the role of search engines. While recent industrial progress has applied generative techniques to closed-set item ranking in e-commerce, research and deployment of open-ended generative search on large content platforms remain limited. This setting introduces challenges, including robustness to noisy retrieval, non-negotiable safety guarantees, and alignment with diverse user needs. In this work, we introduce SearchLLM, the first large language model (LLM) for open-ended generative search. We design a hierarchical, multi-dimensional reward system that separates bottom-line constraints, including factual grounding, basic answer quality and format compliance, from behavior optimization objectives that promote robustness to noisy retrieval and alignment with user needs. Concretely, our reward model evaluates responses conditioned on the user query, session history, and retrieved evidence set, combining rule-based checks with human-calibrated LLM judges to produce an interpretable score vector over these dimensions. We introduce a Gated Aggregation Strategy to derive the training reward for optimizing SearchLLM with Group Relative Policy Optimization (GRPO). We deploy SearchLLM in the AI search entry of RedNote. Offline evaluations and online A/B tests show improved generation quality and user engagement, increasing Valid Consumption Rate by 1.03% and reducing Re-search Rate by 2.81%, while upholding strict safety and reliability standards.
Anti-Length Shift: Dynamic Outlier Truncation for Training Efficient Reasoning Models
Jan 07, 2026Large reasoning models enhanced by reinforcement learning with verifiable rewards have achieved significant performance gains by extending their chain-of-thought. However, this paradigm incurs substantial deployment costs as models often exhibit excessive verbosity on simple queries. Existing efficient reasoning methods relying on explicit length penalties often introduce optimization conflicts and leave the generative mechanisms driving overthinking largely unexamined. In this paper, we identify a phenomenon termed length shift where models increasingly generate unnecessary reasoning on trivial inputs during training. To address this, we introduce Dynamic Outlier Truncation (DOT), a training-time intervention that selectively suppresses redundant tokens. This method targets only the extreme tail of response lengths within fully correct rollout groups while preserving long-horizon reasoning capabilities for complex problems. To complement this intervention and ensure stable convergence, we further incorporate auxiliary KL regularization and predictive dynamic sampling. Experimental results across multiple model scales demonstrate that our approach significantly pushes the efficiency-performance Pareto frontier outward. Notably, on the AIME-24, our method reduces inference token usage by 78% while simultaneously increasing accuracy compared to the initial policy and surpassing state-of-the-art efficient reasoning methods.
SelfAug: Mitigating Catastrophic Forgetting in Retrieval-Augmented Generation via Distribution Self-Alignment
Sep 04, 2025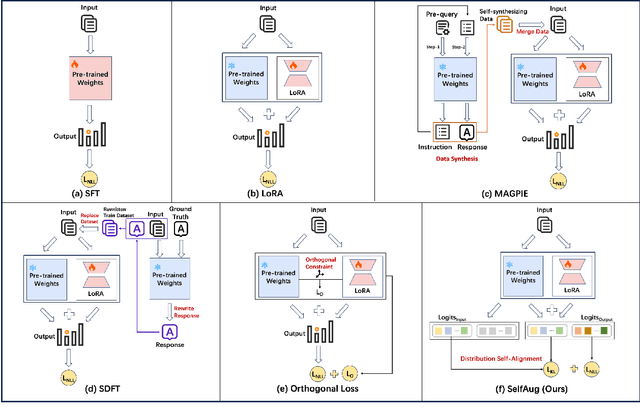
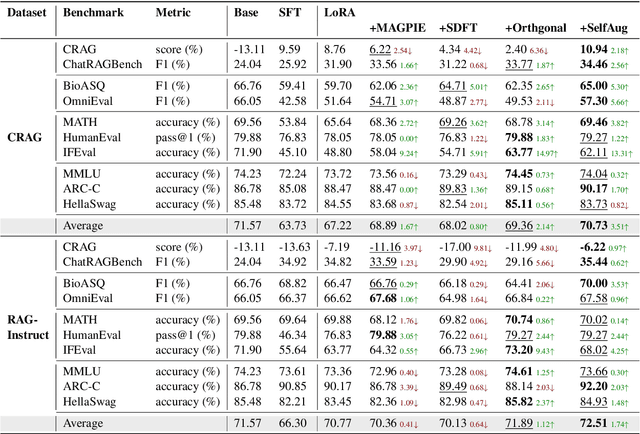
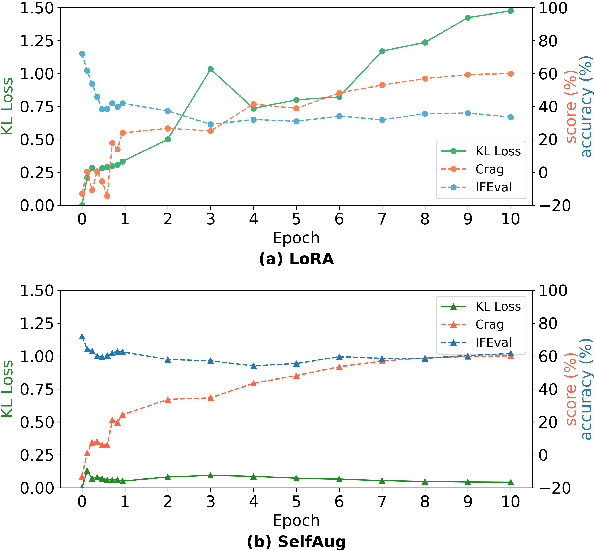
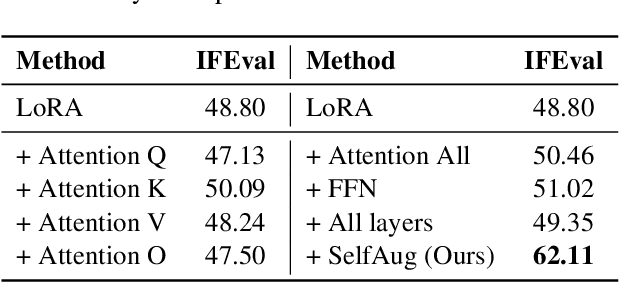
Recent advancements in large language models (LLMs) have revolutionized natural language processing through their remarkable capabilities in understanding and executing diverse tasks. While supervised fine-tuning, particularly in Retrieval-Augmented Generation (RAG) scenarios, effectively enhances task-specific performance, it often leads to catastrophic forgetting, where models lose their previously acquired knowledge and general capabilities. Existing solutions either require access to general instruction data or face limitations in preserving the model's original distribution. To overcome these limitations, we propose SelfAug, a self-distribution alignment method that aligns input sequence logits to preserve the model's semantic distribution, thereby mitigating catastrophic forgetting and improving downstream performance. Extensive experiments demonstrate that SelfAug achieves a superior balance between downstream learning and general capability retention. Our comprehensive empirical analysis reveals a direct correlation between distribution shifts and the severity of catastrophic forgetting in RAG scenarios, highlighting how the absence of RAG capabilities in general instruction tuning leads to significant distribution shifts during fine-tuning. Our findings not only advance the understanding of catastrophic forgetting in RAG contexts but also provide a practical solution applicable across diverse fine-tuning scenarios. Our code is publicly available at https://github.com/USTC-StarTeam/SelfAug.
Plan Your Travel and Travel with Your Plan: Wide-Horizon Planning and Evaluation via LLM
Jun 14, 2025Travel planning is a complex task requiring the integration of diverse real-world information and user preferences. While LLMs show promise, existing methods with long-horizon thinking struggle with handling multifaceted constraints and preferences in the context, leading to suboptimal itineraries. We formulate this as an $L^3$ planning problem, emphasizing long context, long instruction, and long output. To tackle this, we introduce Multiple Aspects of Planning (MAoP), enabling LLMs to conduct wide-horizon thinking to solve complex planning problems. Instead of direct planning, MAoP leverages the strategist to conduct pre-planning from various aspects and provide the planning blueprint for planning models, enabling strong inference-time scalability for better performance. In addition, current benchmarks overlook travel's dynamic nature, where past events impact subsequent journeys, failing to reflect real-world feasibility. To address this, we propose Travel-Sim, an agent-based benchmark assessing plans via real-world travel simulation. This work advances LLM capabilities in complex planning and offers novel insights for evaluating sophisticated scenarios through agent-based simulation.
MoDification: Mixture of Depths Made Easy
Oct 18, 2024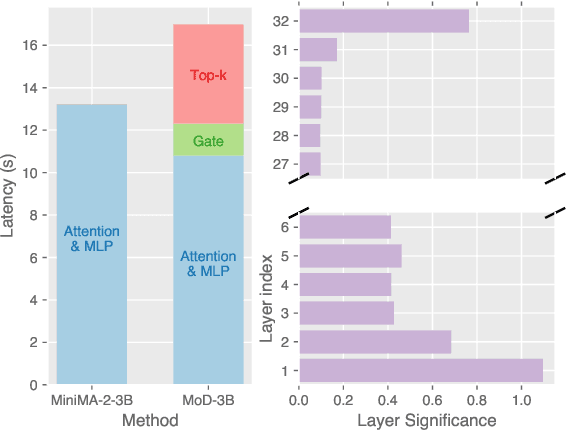
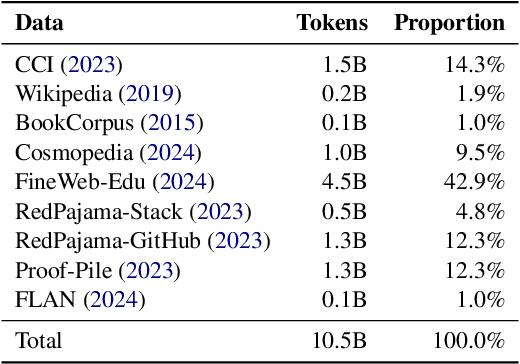
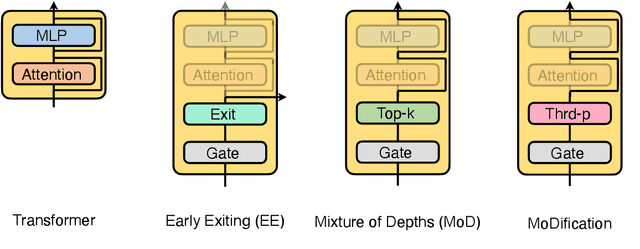
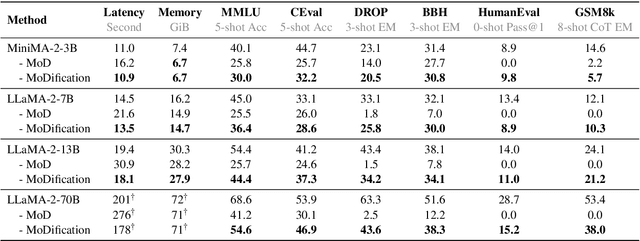
Long-context efficiency has recently become a trending topic in serving large language models (LLMs). And mixture of depths (MoD) is proposed as a perfect fit to bring down both latency and memory. In this paper, however, we discover that MoD can barely transform existing LLMs without costly training over an extensive number of tokens. To enable the transformations from any LLMs to MoD ones, we showcase top-k operator in MoD should be promoted to threshold-p operator, and refinement to architecture and data should also be crafted along. All these designs form our method termed MoDification. Through a comprehensive set of experiments covering model scales from 3B to 70B, we exhibit MoDification strikes an excellent balance between efficiency and effectiveness. MoDification can achieve up to ~1.2x speedup in latency and ~1.8x reduction in memory compared to original LLMs especially in long-context applications.
Vript: A Video Is Worth Thousands of Words
Jun 10, 2024
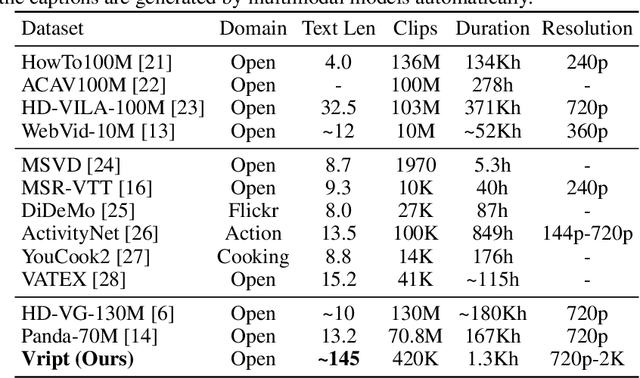
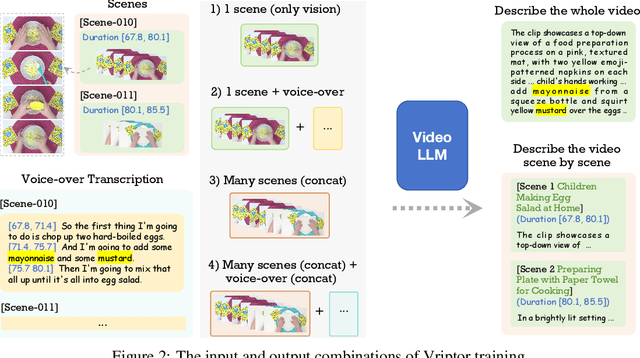
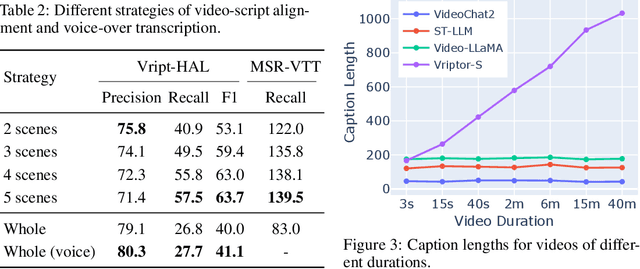
Advancements in multimodal learning, particularly in video understanding and generation, require high-quality video-text datasets for improved model performance. Vript addresses this issue with a meticulously annotated corpus of 12K high-resolution videos, offering detailed, dense, and script-like captions for over 420K clips. Each clip has a caption of ~145 words, which is over 10x longer than most video-text datasets. Unlike captions only documenting static content in previous datasets, we enhance video captioning to video scripting by documenting not just the content, but also the camera operations, which include the shot types (medium shot, close-up, etc) and camera movements (panning, tilting, etc). By utilizing the Vript, we explore three training paradigms of aligning more text with the video modality rather than clip-caption pairs. This results in Vriptor, a top-performing video captioning model among open-source models, comparable to GPT-4V in performance. Vriptor is also a powerful model capable of end-to-end generation of dense and detailed captions for long videos. Moreover, we introduce Vript-Hard, a benchmark consisting of three video understanding tasks that are more challenging than existing benchmarks: Vript-HAL is the first benchmark evaluating action and object hallucinations in video LLMs, Vript-RR combines reasoning with retrieval resolving question ambiguity in long-video QAs, and Vript-ERO is a new task to evaluate the temporal understanding of events in long videos rather than actions in short videos in previous works. All code, models, and datasets are available in https://github.com/mutonix/Vript.
Learning to Reweight for Graph Neural Network
Dec 19, 2023



Graph Neural Networks (GNNs) show promising results for graph tasks. However, existing GNNs' generalization ability will degrade when there exist distribution shifts between testing and training graph data. The cardinal impetus underlying the severe degeneration is that the GNNs are architected predicated upon the I.I.D assumptions. In such a setting, GNNs are inclined to leverage imperceptible statistical correlations subsisting in the training set to predict, albeit it is a spurious correlation. In this paper, we study the problem of the generalization ability of GNNs in Out-Of-Distribution (OOD) settings. To solve this problem, we propose the Learning to Reweight for Generalizable Graph Neural Network (L2R-GNN) to enhance the generalization ability for achieving satisfactory performance on unseen testing graphs that have different distributions with training graphs. We propose a novel nonlinear graph decorrelation method, which can substantially improve the out-of-distribution generalization ability and compares favorably to previous methods in restraining the over-reduced sample size. The variables of the graph representation are clustered based on the stability of the correlation, and the graph decorrelation method learns weights to remove correlations between the variables of different clusters rather than any two variables. Besides, we interpose an efficacious stochastic algorithm upon bi-level optimization for the L2R-GNN framework, which facilitates simultaneously learning the optimal weights and GNN parameters, and avoids the overfitting problem. Experimental results show that L2R-GNN greatly outperforms baselines on various graph prediction benchmarks under distribution shifts.
Qwen Technical Report
Sep 28, 2023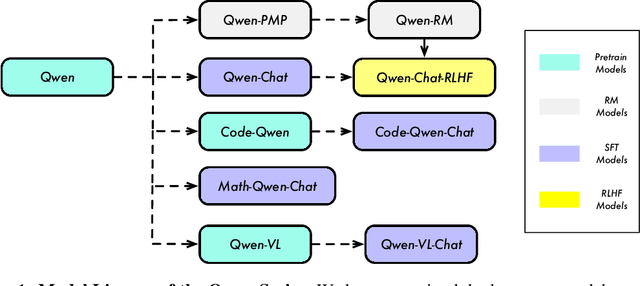

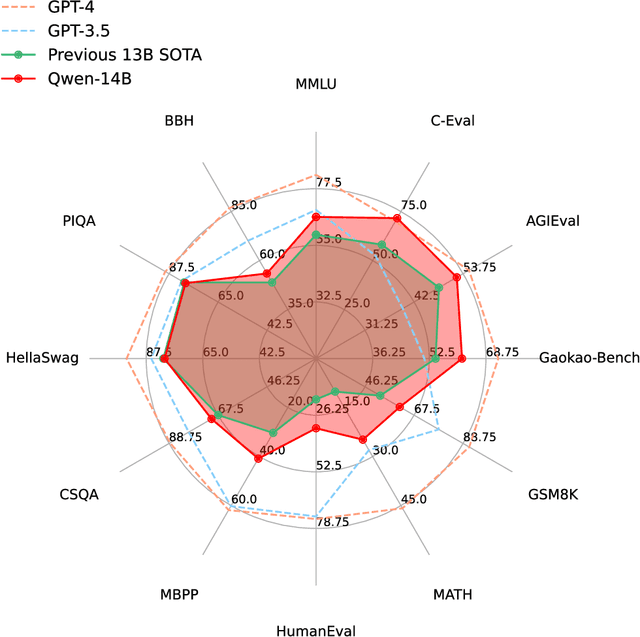
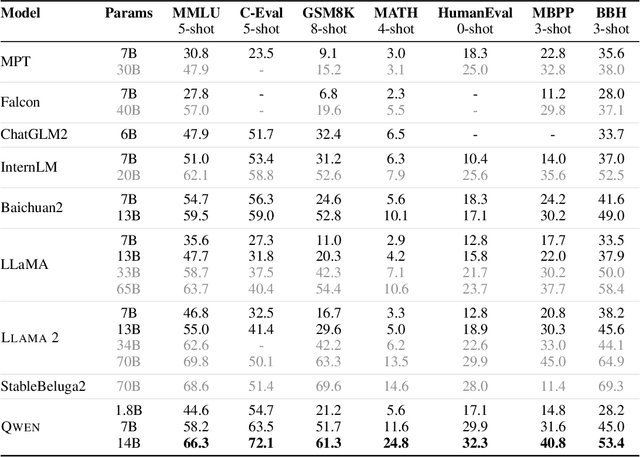
Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling natural language processing tasks that were previously thought to be exclusive to humans. In this work, we introduce Qwen, the first installment of our large language model series. Qwen is a comprehensive language model series that encompasses distinct models with varying parameter counts. It includes Qwen, the base pretrained language models, and Qwen-Chat, the chat models finetuned with human alignment techniques. The base language models consistently demonstrate superior performance across a multitude of downstream tasks, and the chat models, particularly those trained using Reinforcement Learning from Human Feedback (RLHF), are highly competitive. The chat models possess advanced tool-use and planning capabilities for creating agent applications, showcasing impressive performance even when compared to bigger models on complex tasks like utilizing a code interpreter. Furthermore, we have developed coding-specialized models, Code-Qwen and Code-Qwen-Chat, as well as mathematics-focused models, Math-Qwen-Chat, which are built upon base language models. These models demonstrate significantly improved performance in comparison with open-source models, and slightly fall behind the proprietary models.
Multi-task Bioassay Pre-training for Protein-ligand Binding Affinity Prediction
Jun 08, 2023



Protein-ligand binding affinity (PLBA) prediction is the fundamental task in drug discovery. Recently, various deep learning-based models predict binding affinity by incorporating the three-dimensional structure of protein-ligand complexes as input and achieving astounding progress. However, due to the scarcity of high-quality training data, the generalization ability of current models is still limited. In addition, different bioassays use varying affinity measurement labels (i.e., IC50, Ki, Kd), and different experimental conditions inevitably introduce systematic noise, which poses a significant challenge to constructing high-precision affinity prediction models. To address these issues, we (1) propose Multi-task Bioassay Pre-training (MBP), a pre-training framework for structure-based PLBA prediction; (2) construct a pre-training dataset called ChEMBL-Dock with more than 300k experimentally measured affinity labels and about 2.8M docked three-dimensional structures. By introducing multi-task pre-training to treat the prediction of different affinity labels as different tasks and classifying relative rankings between samples from the same bioassay, MBP learns robust and transferrable structural knowledge from our new ChEMBL-Dock dataset with varied and noisy labels. Experiments substantiate the capability of MBP as a general framework that can improve and be tailored to mainstream structure-based PLBA prediction tasks. To the best of our knowledge, MBP is the first affinity pre-training model and shows great potential for future development.