 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Unified Representation for Heterogeneous Recommendation
Jan 26, 2022
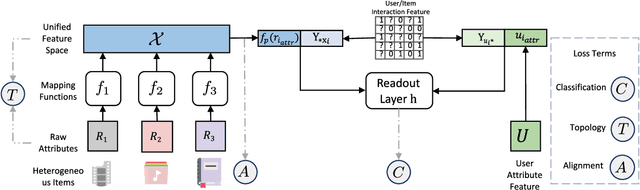
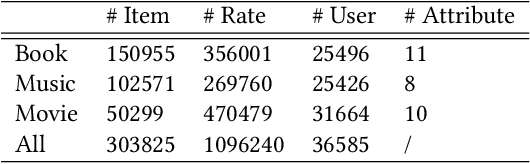
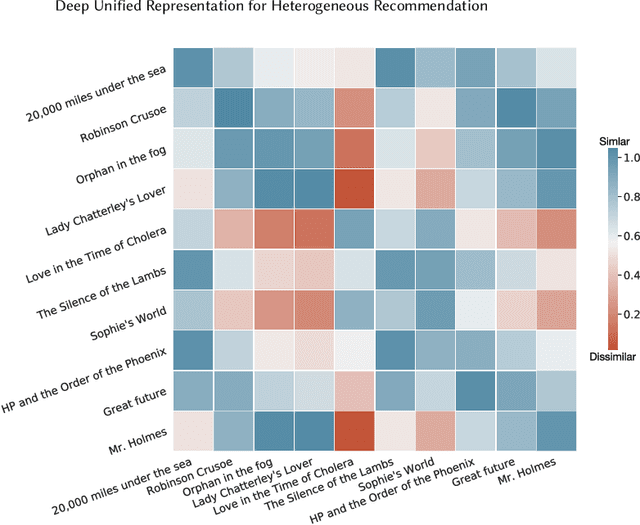
Recommendation system has been a widely studied task both in academia and industry. Previous works mainly focus on homogeneous recommendation and little progress has been made for heterogeneous recommender systems. However, heterogeneous recommendations, e.g., recommending different types of items including products, videos, celebrity shopping notes, among many others, are dominant nowadays. State-of-the-art methods are incapable of leveraging attributes from different types of items and thus suffer from data sparsity problems. And it is indeed quite challenging to represent items with different feature spaces jointly. To tackle this problem, we propose a kernel-based neural network, namely deep unified representation (or DURation) for heterogeneous recommendation, to jointly model unified representations of heterogeneous items while preserving their original feature space topology structures. Theoretically, we prove the representation ability of the proposed model. Besides, we conduct extensive experiments on real-world datasets. Experimental results demonstrate that with the unified representation, our model achieves remarkable improvement (e.g., 4.1% ~ 34.9% lift by AUC score and 3.7% lift by online CTR) over existing state-of-the-art models.
Linear-Time Self Attention with Codeword Histogram for Efficient Recommendation
May 28, 2021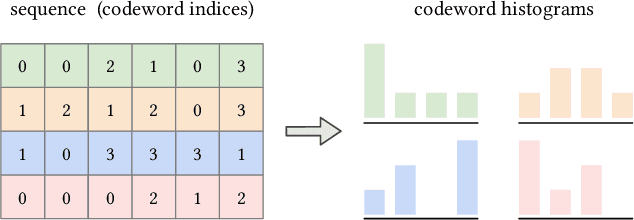

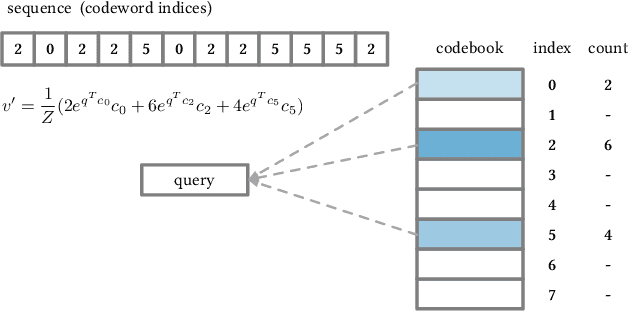

Self-attention has become increasingly popular in a variety of sequence modeling tasks from natural language processing to recommendation, due to its effectiveness. However, self-attention suffers from quadratic computational and memory complexities, prohibiting its applications on long sequences. Existing approaches that address this issue mainly rely on a sparse attention context, either using a local window, or a permuted bucket obtained by locality-sensitive hashing (LSH) or sorting, while crucial information may be lost. Inspired by the idea of vector quantization that uses cluster centroids to approximate items, we propose LISA (LInear-time Self Attention), which enjoys both the effectiveness of vanilla self-attention and the efficiency of sparse attention. LISA scales linearly with the sequence length, while enabling full contextual attention via computing differentiable histograms of codeword distributions. Meanwhile, unlike some efficient attention methods, our method poses no restriction on casual masking or sequence length. We evaluate our method on four real-world datasets for sequential recommendation. The results show that LISA outperforms the state-of-the-art efficient attention methods in both performance and speed; and it is up to 57x faster and 78x more memory efficient than vanilla self-attention.
Rethinking Lifelong Sequential Recommendation with Incremental Multi-Interest Attention
May 28, 2021
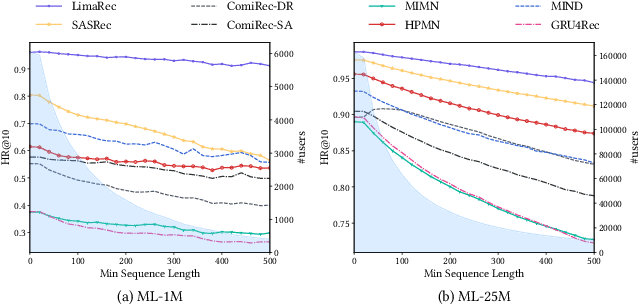

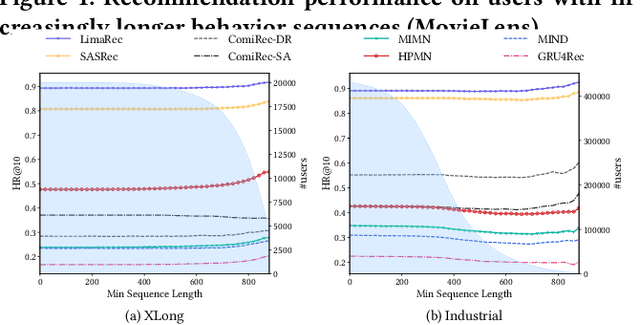
Sequential recommendation plays an increasingly important role in many e-commerce services such as display advertisement and online shopping. With the rapid development of these services in the last two decades, users have accumulated a massive amount of behavior data. Richer sequential behavior data has been proven to be of great value for sequential recommendation. However, traditional sequential models fail to handle users' lifelong sequences, as their linear computational and storage cost prohibits them from performing online inference. Recently, lifelong sequential modeling methods that borrow the idea of memory networks from NLP are proposed to address this issue. However, the RNN-based memory networks built upon intrinsically suffer from the inability to capture long-term dependencies and may instead be overwhelmed by the noise on extremely long behavior sequences. In addition, as the user's behavior sequence gets longer, more interests would be demonstrated in it. It is therefore crucial to model and capture the diverse interests of users. In order to tackle these issues, we propose a novel lifelong incremental multi-interest self attention based sequential recommendation model, namely LimaRec. Our proposed method benefits from the carefully designed self-attention to identify relevant information from users' behavior sequences with different interests. It is still able to incrementally update users' representations for online inference, similarly to memory network based approaches. We extensively evaluate our method on four real-world datasets and demonstrate its superior performances compared to the state-of-the-art baselines.
Federated Graph Learning -- A Position Paper
May 24, 2021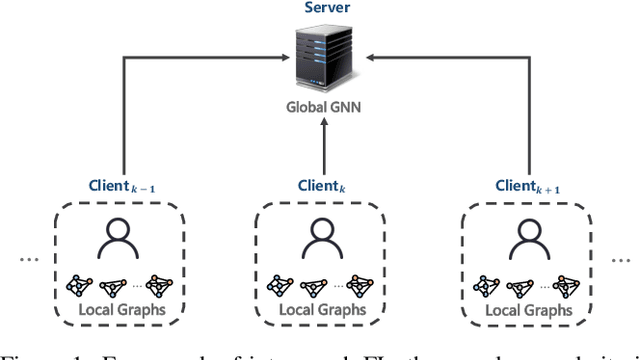

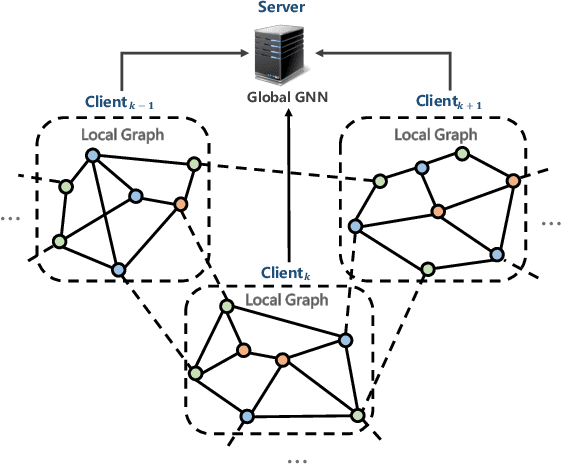

Graph neural networks (GNN) have been successful in many fields, and derived various researches and applications in real industries. However, in some privacy sensitive scenarios (like finance, healthcare), training a GNN model centrally faces challenges due to the distributed data silos. Federated learning (FL) is a an emerging technique that can collaboratively train a shared model while keeping the data decentralized, which is a rational solution for distributed GNN training. We term it as federated graph learning (FGL). Although FGL has received increasing attention recently, the definition and challenges of FGL is still up in the air. In this position paper, we present a categorization to clarify it. Considering how graph data are distributed among clients, we propose four types of FGL: inter-graph FL, intra-graph FL and graph-structured FL, where intra-graph is further divided into horizontal and vertical FGL. For each type of FGL, we make a detailed discussion about the formulation and applications, and propose some potential challenges.