 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation of Transformer-based Language Models Revisited
Paper and Code
Jun 30, 2022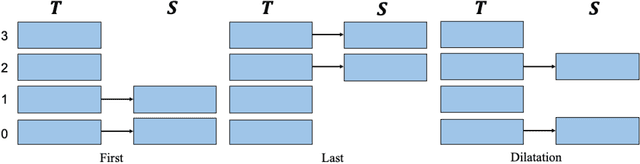
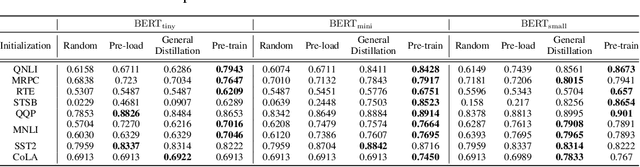
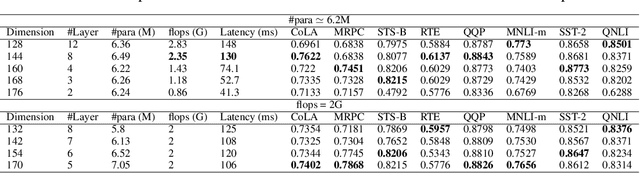
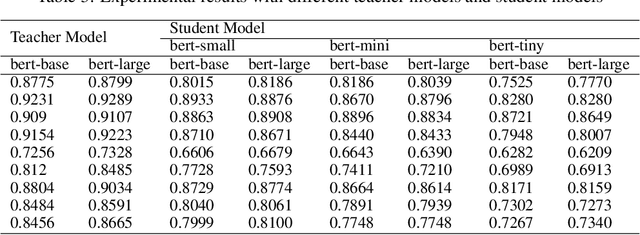
In the past few years, transformer-based pre-trained language models have achieved astounding success in both industry and academia. However, the large model size and high run-time latency are serious impediments to applying them in practice, especially on mobile phones and Internet of Things (IoT) devices. To compress the model, considerable literature has grown up around the theme of knowledge distillation (KD) recently. Nevertheless, how KD works in transformer-based models is still unclear. We tease apart the components of KD and propose a unified KD framework. Through the framework, systematic and extensive experiments that spent over 23,000 GPU hours render a comprehensive analysis from the perspectives of knowledge types, matching strategies, width-depth trade-off, initialization, model size, etc. Our empirical results shed light on the distillation in the pre-train language model and with relative significant improvement over previous state-of-the-arts(SOTA). Finally, we provide a best-practice guideline for the KD in transformer-based models.