 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Compression of Chain-of-Thought via Multi-Agent Reinforcement Learning
Jan 29, 2026The inference overhead induced by redundant reasoning undermines the interactive experience and severely bottlenecks the deployment of Large Reasoning Models. Existing reinforcement learning (RL)-based solutions tackle this problem by coupling a length penalty with outcome-based rewards. This simplistic reward weighting struggles to reconcile brevity with accuracy, as enforcing brevity may compromise critical reasoning logic. In this work, we address this limitation by proposing a multi-agent RL framework that selectively penalizes redundant chunks, while preserving essential reasoning logic. Our framework, Self-Compression via MARL (SCMA), instantiates redundancy detection and evaluation through two specialized agents: \textbf{a Segmentation Agent} for decomposing the reasoning process into logical chunks, and \textbf{a Scoring Agent} for quantifying the significance of each chunk. The Segmentation and Scoring agents collaboratively define an importance-weighted length penalty during training, incentivizing \textbf{a Reasoning Agent} to prioritize essential logic without introducing inference overhead during deployment. Empirical evaluations across model scales demonstrate that SCMA reduces response length by 11.1\% to 39.0\% while boosting accuracy by 4.33\% to 10.02\%. Furthermore, ablation studies and qualitative analysis validate that the synergistic optimization within the MARL framework fosters emergent behaviors, yielding more powerful LRMs compared to vanilla RL paradigms.
JADE: Bridging the Strategic-Operational Gap in Dynamic Agentic RAG
Jan 29, 2026The evolution of Retrieval-Augmented Generation (RAG) has shifted from static retrieval pipelines to dynamic, agentic workflows where a central planner orchestrates multi-turn reasoning. However, existing paradigms face a critical dichotomy: they either optimize modules jointly within rigid, fixed-graph architectures, or empower dynamic planning while treating executors as frozen, black-box tools. We identify that this \textit{decoupled optimization} creates a ``strategic-operational mismatch,'' where sophisticated planning strategies fail to materialize due to unadapted local executors, often leading to negative performance gains despite increased system complexity. In this paper, we propose \textbf{JADE} (\textbf{J}oint \textbf{A}gentic \textbf{D}ynamic \textbf{E}xecution), a unified framework for the joint optimization of planning and execution within dynamic, multi-turn workflows. By modeling the system as a cooperative multi-agent team unified under a single shared backbone, JADE enables end-to-end learning driven by outcome-based rewards. This approach facilitates \textit{co-adaptation}: the planner learns to operate within the capability boundaries of the executors, while the executors evolve to align with high-level strategic intent. Empirical results demonstrate that JADE transforms disjoint modules into a synergistic system, yielding remarkable performance improvements via joint optimization and enabling a flexible balance between efficiency and effectiveness through dynamic workflow orchestration.
Adaptive Inner Speech-Text Alignment for LLM-based Speech Translation
Mar 13, 2025Recent advancement of large language models (LLMs) has led to significant breakthroughs across various tasks, laying the foundation for the development of LLM-based speech translation systems. Existing methods primarily focus on aligning inputs and outputs across modalities while overlooking deeper semantic alignment within model representations. To address this limitation, we propose an Adaptive Inner Speech-Text Alignment (AI-STA) method to bridge the modality gap by explicitly aligning speech and text representations at selected layers within LLMs. To achieve this, we leverage the optimal transport (OT) theory to quantify fine-grained representation discrepancies between speech and text. Furthermore, we utilize the cross-modal retrieval technique to identify the layers that are best suited for alignment and perform joint training on these layers. Experimental results on speech translation (ST) tasks demonstrate that AI-STA significantly improves the translation performance of large speech-text models (LSMs), outperforming previous state-of-the-art approaches. Our findings highlight the importance of inner-layer speech-text alignment in LLMs and provide new insights into enhancing cross-modal learning.
ZigZagkv: Dynamic KV Cache Compression for Long-context Modeling based on Layer Uncertainty
Dec 12, 2024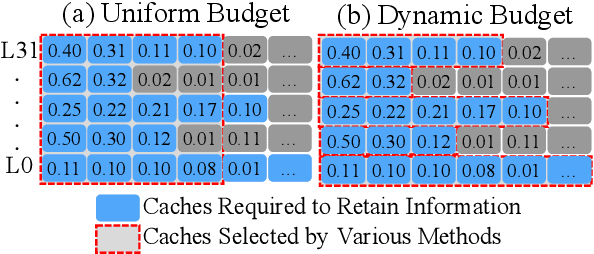



Large Language models (LLMs) have become a research hotspot. To accelerate the inference of LLMs, storing computed caches in memory has become the standard technique. However, as the inference length increases, growing KV caches might lead to out-of-memory issues. Many existing methods address this issue through KV cache compression, primarily by preserving key tokens throughout all layers to reduce information loss. Most of them allocate a uniform budget size for each layer to retain. However, we observe that the minimum budget sizes needed to retain essential information vary across layers and models based on the perspectives of attention and hidden state output. Building on this observation, this paper proposes a simple yet effective KV cache compression method that leverages layer uncertainty to allocate budget size for each layer. Experimental results show that the proposed method can reduce memory usage of the KV caches to only $\sim$20\% when compared to Full KV inference while achieving nearly lossless performance.
MoDification: Mixture of Depths Made Easy
Oct 18, 2024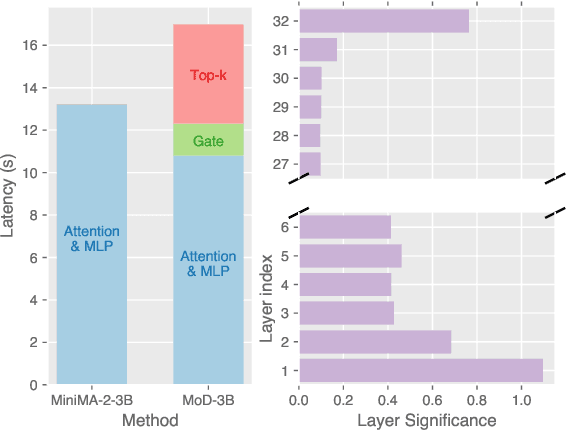
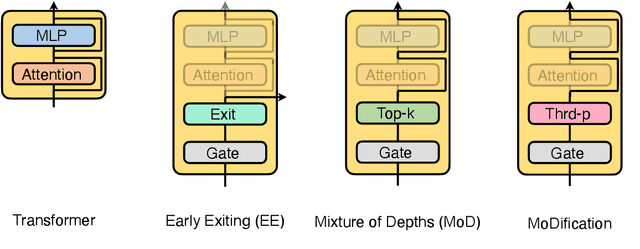
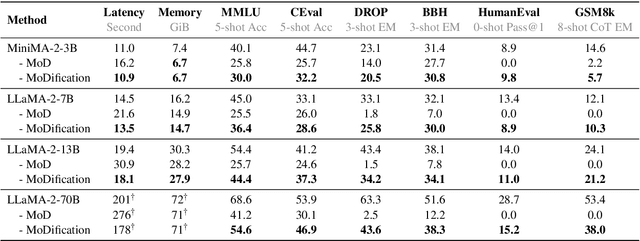
Long-context efficiency has recently become a trending topic in serving large language models (LLMs). And mixture of depths (MoD) is proposed as a perfect fit to bring down both latency and memory. In this paper, however, we discover that MoD can barely transform existing LLMs without costly training over an extensive number of tokens. To enable the transformations from any LLMs to MoD ones, we showcase top-k operator in MoD should be promoted to threshold-p operator, and refinement to architecture and data should also be crafted along. All these designs form our method termed MoDification. Through a comprehensive set of experiments covering model scales from 3B to 70B, we exhibit MoDification strikes an excellent balance between efficiency and effectiveness. MoDification can achieve up to ~1.2x speedup in latency and ~1.8x reduction in memory compared to original LLMs especially in long-context applications.
Understanding the RoPE Extensions of Long-Context LLMs: An Attention Perspective
Jun 19, 2024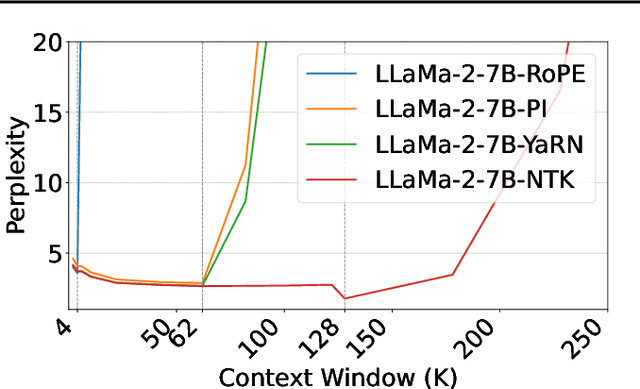
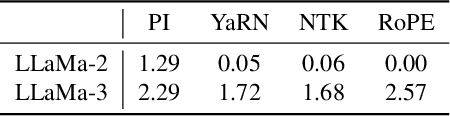

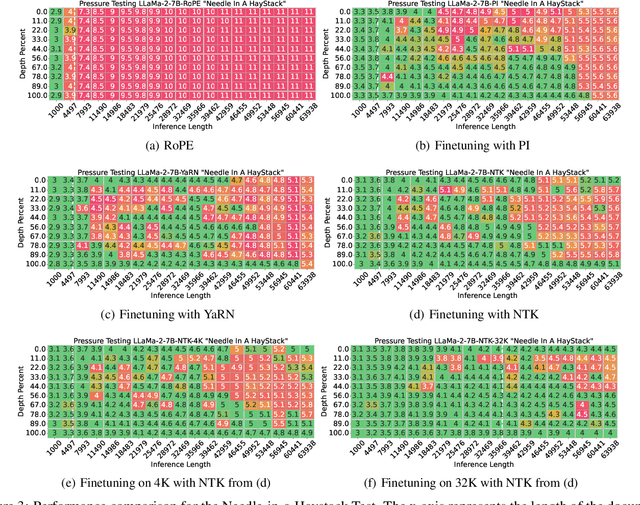
Enabling LLMs to handle lengthy context is currently a research hotspot. Most LLMs are built upon rotary position embedding (RoPE), a popular position encoding method. Therefore, a prominent path is to extrapolate the RoPE trained on comparably short texts to far longer texts. A heavy bunch of efforts have been dedicated to boosting the extrapolation via extending the formulations of the RoPE, however, few of them have attempted to showcase their inner workings comprehensively. In this paper, we are driven to offer a straightforward yet in-depth understanding of RoPE extensions from an attention perspective and on two benchmarking tasks. A broad array of experiments reveals several valuable findings: 1) Maintaining attention patterns to those at the pretrained length improves extrapolation; 2) Large attention uncertainty leads to retrieval errors; 3) Using longer continual pretraining lengths for RoPE extensions could reduce attention uncertainty and significantly enhance extrapolation.
On the Hallucination in Simultaneous Machine Translation
Jun 11, 2024It is widely known that hallucination is a critical issue in Simultaneous Machine Translation (SiMT) due to the absence of source-side information. While many efforts have been made to enhance performance for SiMT, few of them attempt to understand and analyze hallucination in SiMT. Therefore, we conduct a comprehensive analysis of hallucination in SiMT from two perspectives: understanding the distribution of hallucination words and the target-side context usage of them. Intensive experiments demonstrate some valuable findings and particularly show that it is possible to alleviate hallucination by decreasing the over usage of target-side information for SiMT.
Context Consistency between Training and Testing in Simultaneous Machine Translation
Nov 13, 2023Simultaneous Machine Translation (SiMT) aims to yield a real-time partial translation with a monotonically growing the source-side context. However, there is a counterintuitive phenomenon about the context usage between training and testing: e.g., the wait-k testing model consistently trained with wait-k is much worse than that model inconsistently trained with wait-k' (k' is not equal to k) in terms of translation quality. To this end, we first investigate the underlying reasons behind this phenomenon and uncover the following two factors: 1) the limited correlation between translation quality and training (cross-entropy) loss; 2) exposure bias between training and testing. Based on both reasons, we then propose an effective training approach called context consistency training accordingly, which makes consistent the context usage between training and testing by optimizing translation quality and latency as bi-objectives and exposing the predictions to the model during the training. The experiments on three language pairs demonstrate our intuition: our system encouraging context consistency outperforms that existing systems with context inconsistency for the first time, with the help of our context consistency training approach.