 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-Length Shift: Dynamic Outlier Truncation for Training Efficient Reasoning Models
Jan 07, 2026Large reasoning models enhanced by reinforcement learning with verifiable rewards have achieved significant performance gains by extending their chain-of-thought. However, this paradigm incurs substantial deployment costs as models often exhibit excessive verbosity on simple queries. Existing efficient reasoning methods relying on explicit length penalties often introduce optimization conflicts and leave the generative mechanisms driving overthinking largely unexamined. In this paper, we identify a phenomenon termed length shift where models increasingly generate unnecessary reasoning on trivial inputs during training. To address this, we introduce Dynamic Outlier Truncation (DOT), a training-time intervention that selectively suppresses redundant tokens. This method targets only the extreme tail of response lengths within fully correct rollout groups while preserving long-horizon reasoning capabilities for complex problems. To complement this intervention and ensure stable convergence, we further incorporate auxiliary KL regularization and predictive dynamic sampling. Experimental results across multiple model scales demonstrate that our approach significantly pushes the efficiency-performance Pareto frontier outward. Notably, on the AIME-24, our method reduces inference token usage by 78% while simultaneously increasing accuracy compared to the initial policy and surpassing state-of-the-art efficient reasoning methods.
SelfAug: Mitigating Catastrophic Forgetting in Retrieval-Augmented Generation via Distribution Self-Alignment
Sep 04, 2025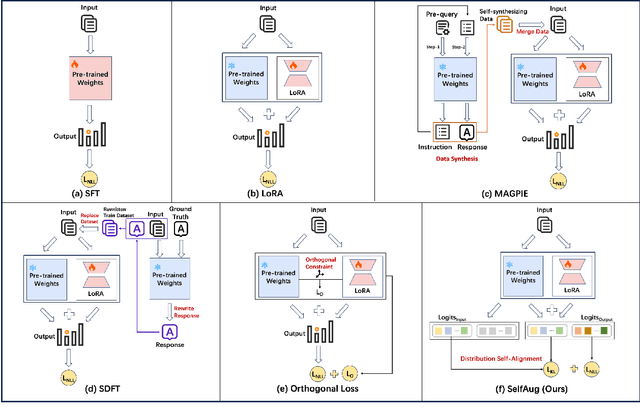
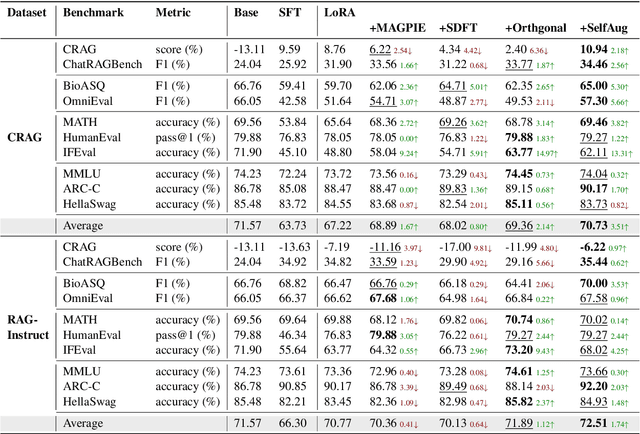
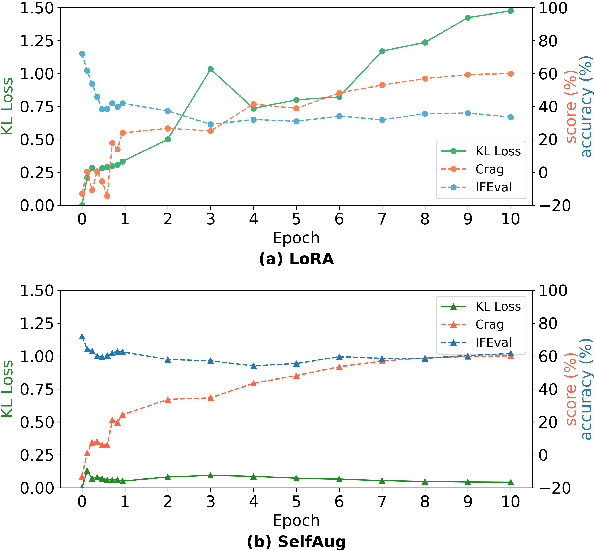
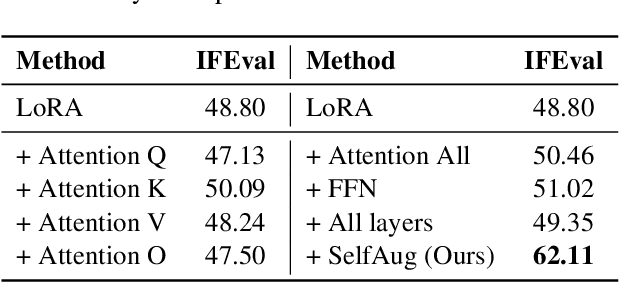
Recent advancements in large language models (LLMs) have revolutionized natural language processing through their remarkable capabilities in understanding and executing diverse tasks. While supervised fine-tuning, particularly in Retrieval-Augmented Generation (RAG) scenarios, effectively enhances task-specific performance, it often leads to catastrophic forgetting, where models lose their previously acquired knowledge and general capabilities. Existing solutions either require access to general instruction data or face limitations in preserving the model's original distribution. To overcome these limitations, we propose SelfAug, a self-distribution alignment method that aligns input sequence logits to preserve the model's semantic distribution, thereby mitigating catastrophic forgetting and improving downstream performance. Extensive experiments demonstrate that SelfAug achieves a superior balance between downstream learning and general capability retention. Our comprehensive empirical analysis reveals a direct correlation between distribution shifts and the severity of catastrophic forgetting in RAG scenarios, highlighting how the absence of RAG capabilities in general instruction tuning leads to significant distribution shifts during fine-tuning. Our findings not only advance the understanding of catastrophic forgetting in RAG contexts but also provide a practical solution applicable across diverse fine-tuning scenarios. Our code is publicly available at https://github.com/USTC-StarTeam/SelfAug.
Plan Your Travel and Travel with Your Plan: Wide-Horizon Planning and Evaluation via LLM
Jun 14, 2025Travel planning is a complex task requiring the integration of diverse real-world information and user preferences. While LLMs show promise, existing methods with long-horizon thinking struggle with handling multifaceted constraints and preferences in the context, leading to suboptimal itineraries. We formulate this as an $L^3$ planning problem, emphasizing long context, long instruction, and long output. To tackle this, we introduce Multiple Aspects of Planning (MAoP), enabling LLMs to conduct wide-horizon thinking to solve complex planning problems. Instead of direct planning, MAoP leverages the strategist to conduct pre-planning from various aspects and provide the planning blueprint for planning models, enabling strong inference-time scalability for better performance. In addition, current benchmarks overlook travel's dynamic nature, where past events impact subsequent journeys, failing to reflect real-world feasibility. To address this, we propose Travel-Sim, an agent-based benchmark assessing plans via real-world travel simulation. This work advances LLM capabilities in complex planning and offers novel insights for evaluating sophisticated scenarios through agent-based simulation.
Aneumo: A Large-Scale Comprehensive Synthetic Dataset of Aneurysm Hemodynamics
Jan 17, 2025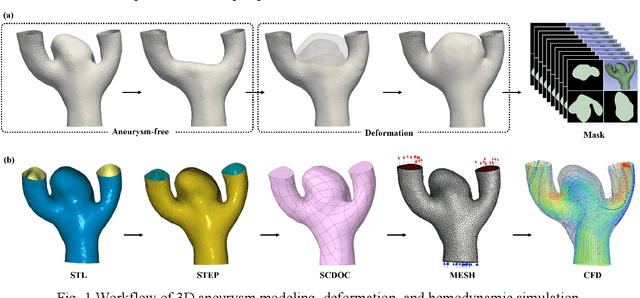
Intracranial aneurysm (IA) is a common cerebrovascular disease that is usually asymptomatic but may cause severe subarachnoid hemorrhage (SAH) if ruptured. Although clinical practice is usually based on individual factors and morphological features of the aneurysm, its pathophysiology and hemodynamic mechanisms remain controversial. To address the limitations of current research, this study constructed a comprehensive hemodynamic dataset of intracranial aneurysms. The dataset is based on 466 real aneurysm models, and 10,000 synthetic models were generated by resection and deformation operations, including 466 aneurysm-free models and 9,534 deformed aneurysm models. The dataset also provides medical image-like segmentation mask files to support insightful analysis. In addition, the dataset contains hemodynamic data measured at eight steady-state flow rates (0.001 to 0.004 kg/s), including critical parameters such as flow velocity, pressure, and wall shear stress, providing a valuable resource for investigating aneurysm pathogenesis and clinical prediction. This dataset will help advance the understanding of the pathologic features and hemodynamic mechanisms of intracranial aneurysms and support in-depth research in related fields. Dataset hosted at https://github.com/Xigui-Li/Aneumo.
MoDification: Mixture of Depths Made Easy
Oct 18, 2024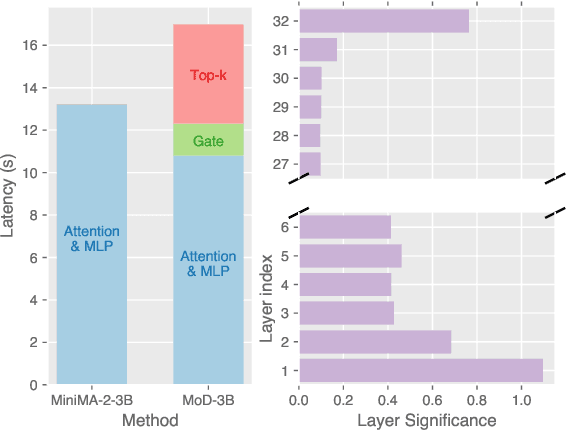
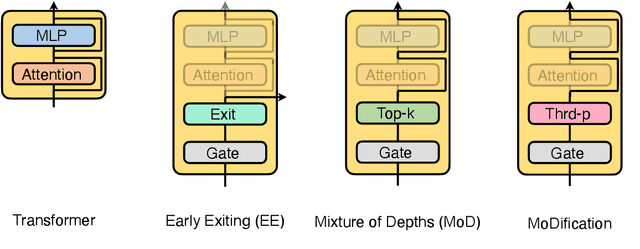
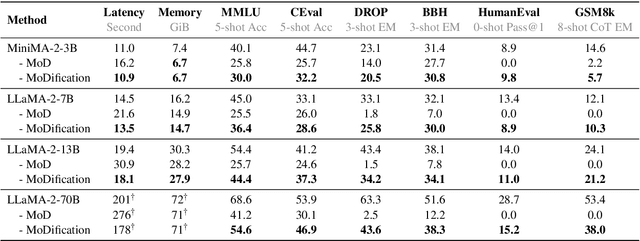
Long-context efficiency has recently become a trending topic in serving large language models (LLMs). And mixture of depths (MoD) is proposed as a perfect fit to bring down both latency and memory. In this paper, however, we discover that MoD can barely transform existing LLMs without costly training over an extensive number of tokens. To enable the transformations from any LLMs to MoD ones, we showcase top-k operator in MoD should be promoted to threshold-p operator, and refinement to architecture and data should also be crafted along. All these designs form our method termed MoDification. Through a comprehensive set of experiments covering model scales from 3B to 70B, we exhibit MoDification strikes an excellent balance between efficiency and effectiveness. MoDification can achieve up to ~1.2x speedup in latency and ~1.8x reduction in memory compared to original LLMs especially in long-context applications.
VideoLLM-MoD: Efficient Video-Language Streaming with Mixture-of-Depths Vision Computation
Aug 29, 2024



A well-known dilemma in large vision-language models (e.g., GPT-4, LLaVA) is that while increasing the number of vision tokens generally enhances visual understanding, it also significantly raises memory and computational costs, especially in long-term, dense video frame streaming scenarios. Although learnable approaches like Q-Former and Perceiver Resampler have been developed to reduce the vision token burden, they overlook the context causally modeled by LLMs (i.e., key-value cache), potentially leading to missed visual cues when addressing user queries. In this paper, we introduce a novel approach to reduce vision compute by leveraging redundant vision tokens "skipping layers" rather than decreasing the number of vision tokens. Our method, VideoLLM-MoD, is inspired by mixture-of-depths LLMs and addresses the challenge of numerous vision tokens in long-term or streaming video. Specifically, for each transformer layer, we learn to skip the computation for a high proportion (e.g., 80\%) of vision tokens, passing them directly to the next layer. This approach significantly enhances model efficiency, achieving approximately \textasciitilde42\% time and \textasciitilde30\% memory savings for the entire training. Moreover, our method reduces the computation in the context and avoid decreasing the vision tokens, thus preserving or even improving performance compared to the vanilla model. We conduct extensive experiments to demonstrate the effectiveness of VideoLLM-MoD, showing its state-of-the-art results on multiple benchmarks, including narration, forecasting, and summarization tasks in COIN, Ego4D, and Ego-Exo4D datasets.
MVP-SEG: Multi-View Prompt Learning for Open-Vocabulary Semantic Segmentation
Apr 14, 2023



CLIP (Contrastive Language-Image Pretraining) is well-developed for open-vocabulary zero-shot image-level recognition, while its applications in pixel-level tasks are less investigated, where most efforts directly adopt CLIP features without deliberative adaptations. In this work, we first demonstrate the necessity of image-pixel CLIP feature adaption, then provide Multi-View Prompt learning (MVP-SEG) as an effective solution to achieve image-pixel adaptation and to solve open-vocabulary semantic segmentation. Concretely, MVP-SEG deliberately learns multiple prompts trained by our Orthogonal Constraint Loss (OCLoss), by which each prompt is supervised to exploit CLIP feature on different object parts, and collaborative segmentation masks generated by all prompts promote better segmentation. Moreover, MVP-SEG introduces Global Prompt Refining (GPR) to further eliminate class-wise segmentation noise. Experiments show that the multi-view prompts learned from seen categories have strong generalization to unseen categories, and MVP-SEG+ which combines the knowledge transfer stage significantly outperforms previous methods on several benchmarks. Moreover, qualitative results justify that MVP-SEG does lead to better focus on different local parts.
Decoupled IoU Regression for Object Detection
Feb 02, 2022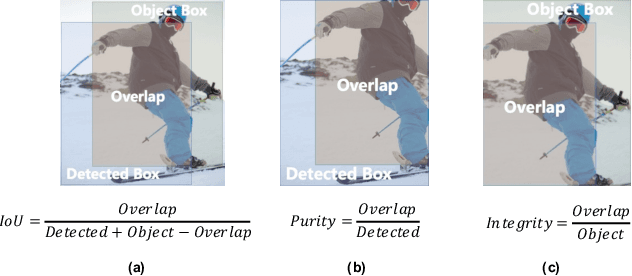

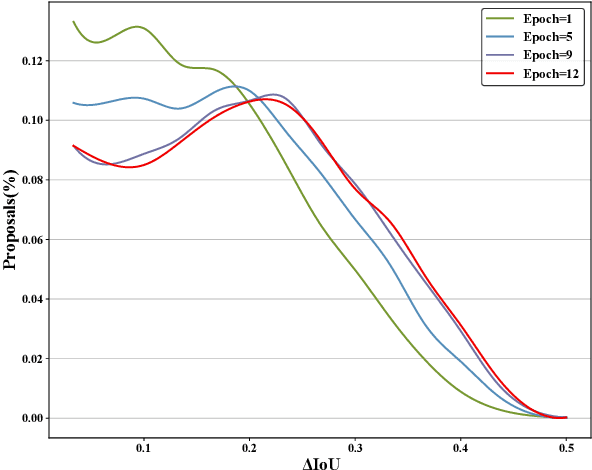
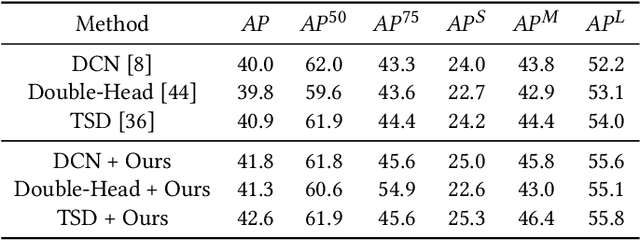
Non-maximum suppression (NMS) is widely used in object detection pipelines for removing duplicated bounding boxes. The inconsistency between the confidence for NMS and the real localization confidence seriously affects detection performance. Prior works propose to predict Intersection-over-Union (IoU) between bounding boxes and corresponding ground-truths to improve NMS, while accurately predicting IoU is still a challenging problem. We argue that the complex definition of IoU and feature misalignment make it difficult to predict IoU accurately. In this paper, we propose a novel Decoupled IoU Regression (DIR) model to handle these problems. The proposed DIR decouples the traditional localization confidence metric IoU into two new metrics, Purity and Integrity. Purity reflects the proportion of the object area in the detected bounding box, and Integrity refers to the completeness of the detected object area. Separately predicting Purity and Integrity can divide the complex mapping between the bounding box and its IoU into two clearer mappings and model them independently. In addition, a simple but effective feature realignment approach is also introduced to make the IoU regressor work in a hindsight manner, which can make the target mapping more stable. The proposed DIR can be conveniently integrated with existing two-stage detectors and significantly improve their performance. Through a simple implementation of DIR with HTC, we obtain 51.3% AP on MS COCO benchmark, which outperforms previous methods and achieves state-of-the-art.
End-to-end Temporal Action Detection with Transformer
Jul 14, 2021
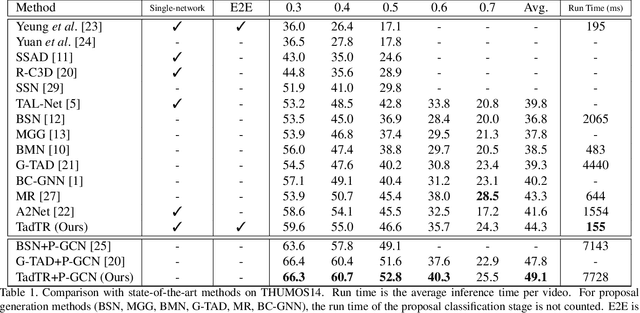

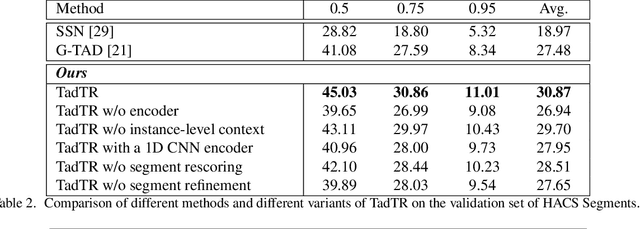
Temporal action detection (TAD) aims to determine the semantic label and the boundaries of every action instance in an untrimmed video. It is a fundamental and challenging task in video understanding and significant progress has been made. Previous methods involve multiple stages or networks and hand-designed rules or operations, which fall short in efficiency and flexibility. In this paper, we propose an end-to-end framework for TAD upon Transformer, termed \textit{TadTR}, which maps a set of learnable embeddings to action instances in parallel. TadTR is able to adaptively extract temporal context information required for making action predictions, by selectively attending to a sparse set of snippets in a video. As a result, it simplifies the pipeline of TAD and requires lower computation cost than previous detectors, while preserving remarkable detection performance. TadTR achieves state-of-the-art performance on HACS Segments (+3.35% average mAP). As a single-network detector, TadTR runs 10$\times$ faster than its comparable competitor. It outperforms existing single-network detectors by a large margin on THUMOS14 (+5.0% average mAP) and ActivityNet (+7.53% average mAP). When combined with other detectors, it reports 54.1% mAP at IoU=0.5 on THUMOS14, and 34.55% average mAP on ActivityNet-1.3. Our code will be released at \url{https://github.com/xlliu7/TadTR}.
Gliding vertex on the horizontal bounding box for multi-oriented object detection
Nov 21, 2019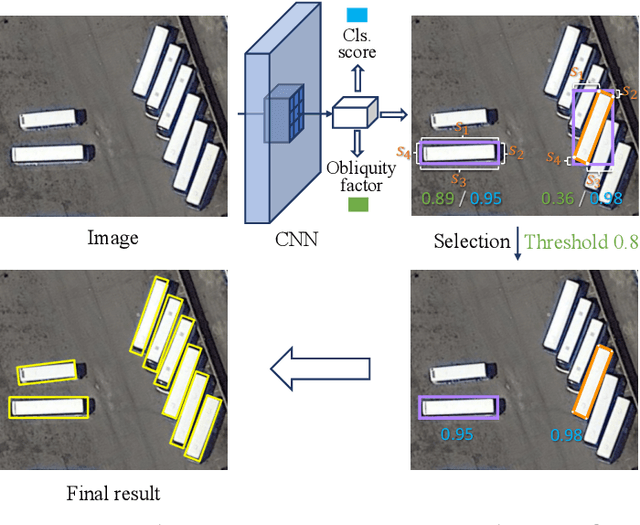
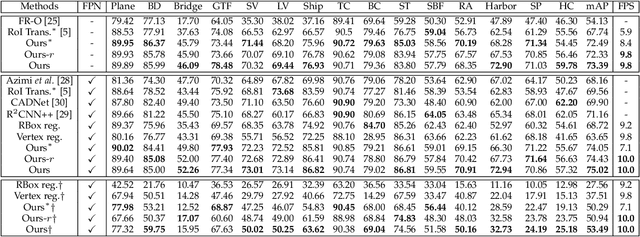
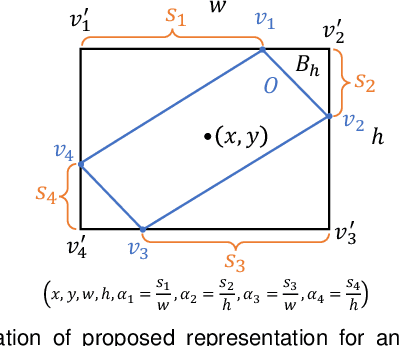
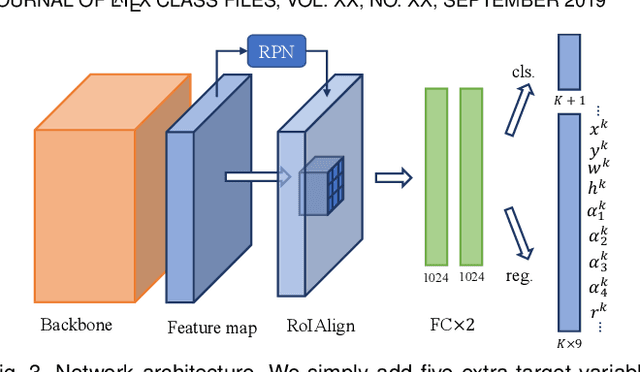
Object detection has recently experienced substantial progress. Yet, the widely adopted horizontal bounding box representation is not appropriate for ubiquitous oriented objects such as objects in aerial images and scene texts. In this paper, we propose a simple yet effective framework to detect multi-oriented objects. Instead of directly regressing the four vertices, we glide the vertex of the horizontal bounding box on each corresponding side to accurately describe a multi-oriented object. Specifically, We regress four length ratios characterizing the relative gliding offset on each corresponding side. This may facilitate the offset learning and avoid the confusion issue of sequential label points for oriented objects. To further remedy the confusion issue for nearly horizontal objects, we also introduce an obliquity factor based on area ratio between the object and its horizontal bounding box, guiding the selection of horizontal or oriented detection for each object. We add these five extra target variables to the regression head of fast R-CNN, which requires ignorable extra computation time. Extensive experimental results demonstrate that without bells and whistles, the proposed method achieves superior performances on multiple multi-oriented object detection benchmarks including object detection in aerial images, scene text detection, pedestrian detection in fisheye images.