 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Normal Estimation via Shading Sequence Estimation
Feb 11, 2026Monocular normal estimation aims to estimate the normal map from a single RGB image of an object under arbitrary lights. Existing methods rely on deep models to directly predict normal maps. However, they often suffer from 3D misalignment: while the estimated normal maps may appear to have a correct appearance, the reconstructed surfaces often fail to align with the geometric details. We argue that this misalignment stems from the current paradigm: the model struggles to distinguish and reconstruct varying geometry represented in normal maps, as the differences in underlying geometry are reflected only through relatively subtle color variations. To address this issue, we propose a new paradigm that reformulates normal estimation as shading sequence estimation, where shading sequences are more sensitive to various geometric information. Building on this paradigm, we present RoSE, a method that leverages image-to-video generative models to predict shading sequences. The predicted shading sequences are then converted into normal maps by solving a simple ordinary least-squares problem. To enhance robustness and better handle complex objects, RoSE is trained on a synthetic dataset, MultiShade, with diverse shapes, materials, and light conditions. Experiments demonstrate that RoSE achieves state-of-the-art performance on real-world benchmark datasets for object-based monocular normal estimation.
CodeDance: A Dynamic Tool-integrated MLLM for Executable Visual Reasoning
Dec 19, 2025Recent releases such as o3 highlight human-like "thinking with images" reasoning that combines structured tool use with stepwise verification, yet most open-source approaches still rely on text-only chains, rigid visual schemas, or single-step pipelines, limiting flexibility, interpretability, and transferability on complex tasks. We introduce CodeDance, which explores executable code as a general solver for visual reasoning. Unlike fixed-schema calls (e.g., only predicting bounding-box coordinates), CodeDance defines, composes, and executes code to orchestrate multiple tools, compute intermediate results, and render visual artifacts (e.g., boxes, lines, plots) that support transparent, self-checkable reasoning. To guide this process, we introduce a reward for balanced and adaptive tool-call, which balances exploration with efficiency and mitigates tool overuse. Interestingly, beyond the expected capabilities taught by atomic supervision, we empirically observe novel emergent behaviors during RL training: CodeDance demonstrates novel tool invocations, unseen compositions, and cross-task transfer. These behaviors arise without task-specific fine-tuning, suggesting a general and scalable mechanism of executable visual reasoning. Extensive experiments across reasoning benchmarks (e.g., visual search, math, chart QA) show that CodeDance not only consistently outperforms schema-driven and text-only baselines, but also surpasses advanced closed models such as GPT-4o and larger open-source models.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
MOSEv2: A More Challenging Dataset for Video Object Segmentation in Complex Scenes
Aug 07, 2025Video object segmentation (VOS) aims to segment specified target objects throughout a video. Although state-of-the-art methods have achieved impressive performance (e.g., 90+% J&F) on existing benchmarks such as DAVIS and YouTube-VOS, these datasets primarily contain salient, dominant, and isolated objects, limiting their generalization to real-world scenarios. To advance VOS toward more realistic environments, coMplex video Object SEgmentation (MOSEv1) was introduced to facilitate VOS research in complex scenes. Building on the strengths and limitations of MOSEv1, we present MOSEv2, a significantly more challenging dataset designed to further advance VOS methods under real-world conditions. MOSEv2 consists of 5,024 videos and over 701,976 high-quality masks for 10,074 objects across 200 categories. Compared to its predecessor, MOSEv2 introduces significantly greater scene complexity, including more frequent object disappearance and reappearance, severe occlusions and crowding, smaller objects, as well as a range of new challenges such as adverse weather (e.g., rain, snow, fog), low-light scenes (e.g., nighttime, underwater), multi-shot sequences, camouflaged objects, non-physical targets (e.g., shadows, reflections), scenarios requiring external knowledge, etc. We benchmark 20 representative VOS methods under 5 different settings and observe consistent performance drops. For example, SAM2 drops from 76.4% on MOSEv1 to only 50.9% on MOSEv2. We further evaluate 9 video object tracking methods and find similar declines, demonstrating that MOSEv2 presents challenges across tasks. These results highlight that despite high accuracy on existing datasets, current VOS methods still struggle under real-world complexities. MOSEv2 is publicly available at https://MOSE.video.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025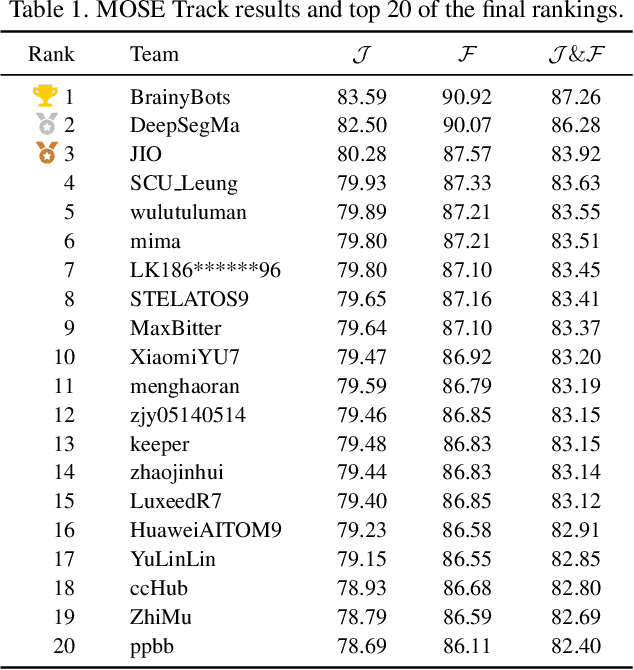
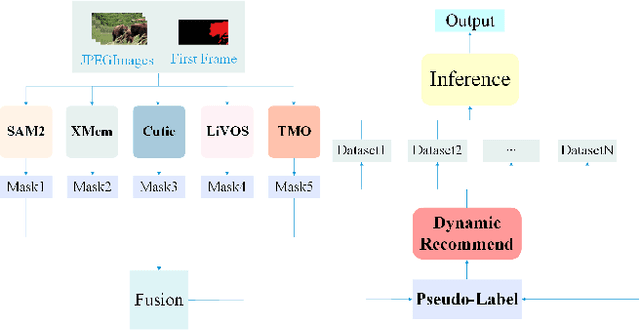
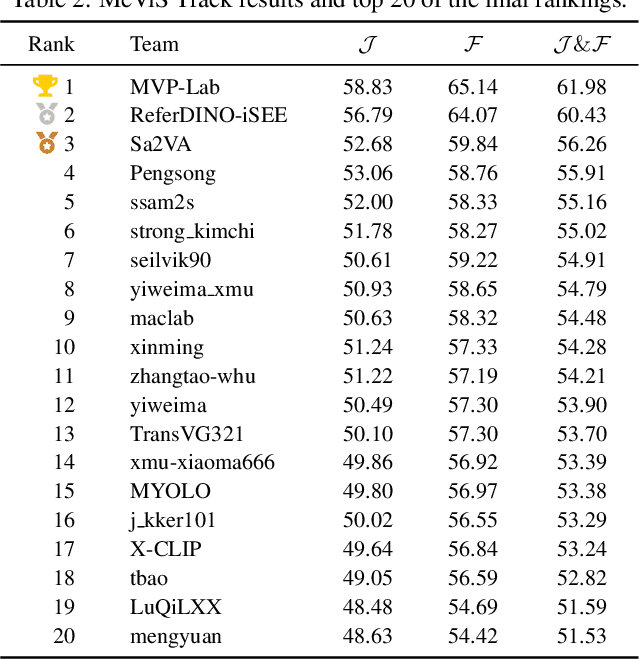
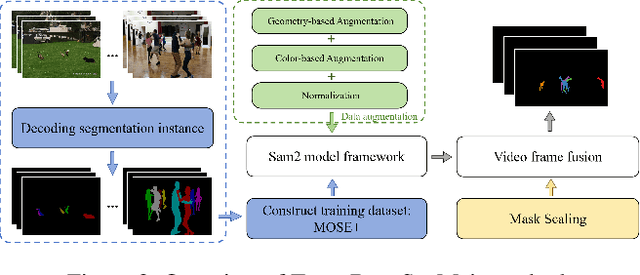
This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.
Liquid: Language Models are Scalable Multi-modal Generators
Dec 05, 2024
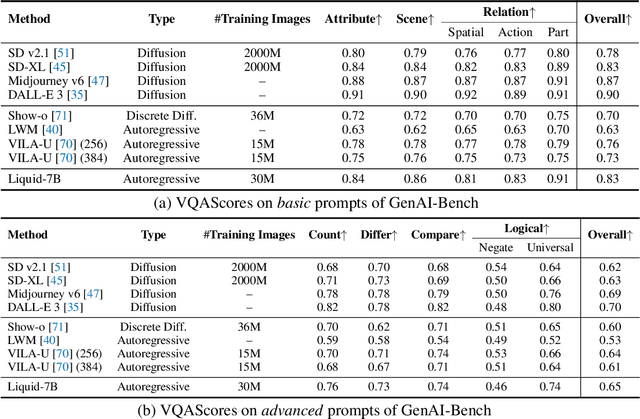

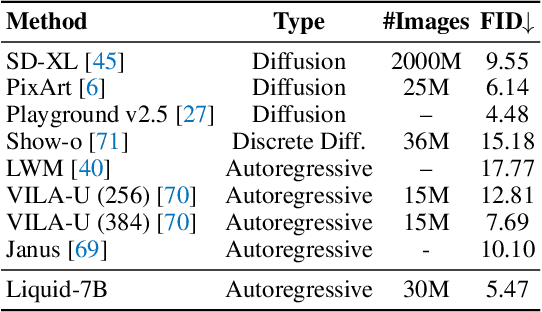
We present Liquid, an auto-regressive generation paradigm that seamlessly integrates visual comprehension and generation by tokenizing images into discrete codes and learning these code embeddings alongside text tokens within a shared feature space for both vision and language. Unlike previous multimodal large language model (MLLM), Liquid achieves this integration using a single large language model (LLM), eliminating the need for external pretrained visual embeddings such as CLIP. For the first time, Liquid uncovers a scaling law that performance drop unavoidably brought by the unified training of visual and language tasks diminishes as the model size increases. Furthermore, the unified token space enables visual generation and comprehension tasks to mutually enhance each other, effectively removing the typical interference seen in earlier models. We show that existing LLMs can serve as strong foundations for Liquid, saving 100x in training costs while outperforming Chameleon in multimodal capabilities and maintaining language performance comparable to mainstream LLMs like LLAMA2. Liquid also outperforms models like SD v2.1 and SD-XL (FID of 5.47 on MJHQ-30K), excelling in both vision-language and text-only tasks. This work demonstrates that LLMs such as LLAMA3.2 and GEMMA2 are powerful multimodal generators, offering a scalable solution for enhancing both vision-language understanding and generation. The code and models will be released.
PartGLEE: A Foundation Model for Recognizing and Parsing Any Objects
Jul 23, 2024We present PartGLEE, a part-level foundation model for locating and identifying both objects and parts in images. Through a unified framework, PartGLEE accomplishes detection, segmentation, and grounding of instances at any granularity in the open world scenario. Specifically, we propose a Q-Former to construct the hierarchical relationship between objects and parts, parsing every object into corresponding semantic parts. By incorporating a large amount of object-level data, the hierarchical relationships can be extended, enabling PartGLEE to recognize a rich variety of parts. We conduct comprehensive studies to validate the effectiveness of our method, PartGLEE achieves the state-of-the-art performance across various part-level tasks and obtain competitive results on object-level tasks. The proposed PartGLEE significantly enhances hierarchical modeling capabilities and part-level perception over our previous GLEE model. Further analysis indicates that the hierarchical cognitive ability of PartGLEE is able to facilitate a detailed comprehension in images for mLLMs. The model and code will be released at https://provencestar.github.io/PartGLEE-Vision/ .
PVUW 2024 Challenge on Complex Video Understanding: Methods and Results
Jun 24, 2024



Pixel-level Video Understanding in the Wild Challenge (PVUW) focus on complex video understanding. In this CVPR 2024 workshop, we add two new tracks, Complex Video Object Segmentation Track based on MOSE dataset and Motion Expression guided Video Segmentation track based on MeViS dataset. In the two new tracks, we provide additional videos and annotations that feature challenging elements, such as the disappearance and reappearance of objects, inconspicuous small objects, heavy occlusions, and crowded environments in MOSE. Moreover, we provide a new motion expression guided video segmentation dataset MeViS to study the natural language-guided video understanding in complex environments. These new videos, sentences, and annotations enable us to foster the development of a more comprehensive and robust pixel-level understanding of video scenes in complex environments and realistic scenarios. The MOSE challenge had 140 registered teams in total, 65 teams participated the validation phase and 12 teams made valid submissions in the final challenge phase. The MeViS challenge had 225 registered teams in total, 50 teams participated the validation phase and 5 teams made valid submissions in the final challenge phase.
DIRECT-3D: Learning Direct Text-to-3D Generation on Massive Noisy 3D Data
Jun 07, 2024



We present DIRECT-3D, a diffusion-based 3D generative model for creating high-quality 3D assets (represented by Neural Radiance Fields) from text prompts. Unlike recent 3D generative models that rely on clean and well-aligned 3D data, limiting them to single or few-class generation, our model is directly trained on extensive noisy and unaligned `in-the-wild' 3D assets, mitigating the key challenge (i.e., data scarcity) in large-scale 3D generation. In particular, DIRECT-3D is a tri-plane diffusion model that integrates two innovations: 1) A novel learning framework where noisy data are filtered and aligned automatically during the training process. Specifically, after an initial warm-up phase using a small set of clean data, an iterative optimization is introduced in the diffusion process to explicitly estimate the 3D pose of objects and select beneficial data based on conditional density. 2) An efficient 3D representation that is achieved by disentangling object geometry and color features with two separate conditional diffusion models that are optimized hierarchically. Given a prompt input, our model generates high-quality, high-resolution, realistic, and complex 3D objects with accurate geometric details in seconds. We achieve state-of-the-art performance in both single-class generation and text-to-3D generation. We also demonstrate that DIRECT-3D can serve as a useful 3D geometric prior of objects, for example to alleviate the well-known Janus problem in 2D-lifting methods such as DreamFusion. The code and models are available for research purposes at: https://github.com/qihao067/direct3d.
Debiasing Text-to-Image Diffusion Models
Feb 22, 2024Learning-based Text-to-Image (TTI) models like Stable Diffusion have revolutionized the way visual content is generated in various domains. However, recent research has shown that nonnegligible social bias exists in current state-of-the-art TTI systems, which raises important concerns. In this work, we target resolving the social bias in TTI diffusion models. We begin by formalizing the problem setting and use the text descriptions of bias groups to establish an unsafe direction for guiding the diffusion process. Next, we simplify the problem into a weight optimization problem and attempt a Reinforcement solver, Policy Gradient, which shows sub-optimal performance with slow convergence. Further, to overcome limitations, we propose an iterative distribution alignment (IDA) method. Despite its simplicity, we show that IDA shows efficiency and fast convergence in resolving the social bias in TTI diffusion models. Our code will be released.