 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Text-to-Image Diffusion Models
Feb 22, 2024Learning-based Text-to-Image (TTI) models like Stable Diffusion have revolutionized the way visual content is generated in various domains. However, recent research has shown that nonnegligible social bias exists in current state-of-the-art TTI systems, which raises important concerns. In this work, we target resolving the social bias in TTI diffusion models. We begin by formalizing the problem setting and use the text descriptions of bias groups to establish an unsafe direction for guiding the diffusion process. Next, we simplify the problem into a weight optimization problem and attempt a Reinforcement solver, Policy Gradient, which shows sub-optimal performance with slow convergence. Further, to overcome limitations, we propose an iterative distribution alignment (IDA) method. Despite its simplicity, we show that IDA shows efficiency and fast convergence in resolving the social bias in TTI diffusion models. Our code will be released.
Dataset Condensation via Generative Model
Sep 14, 2023Dataset condensation aims to condense a large dataset with a lot of training samples into a small set. Previous methods usually condense the dataset into the pixels format. However, it suffers from slow optimization speed and large number of parameters to be optimized. When increasing image resolutions and classes, the number of learnable parameters grows accordingly, prohibiting condensation methods from scaling up to large datasets with diverse classes. Moreover, the relations among condensed samples have been neglected and hence the feature distribution of condensed samples is often not diverse. To solve these problems, we propose to condense the dataset into another format, a generative model. Such a novel format allows for the condensation of large datasets because the size of the generative model remains relatively stable as the number of classes or image resolution increases. Furthermore, an intra-class and an inter-class loss are proposed to model the relation of condensed samples. Intra-class loss aims to create more diverse samples for each class by pushing each sample away from the others of the same class. Meanwhile, inter-class loss increases the discriminability of samples by widening the gap between the centers of different classes. Extensive comparisons with state-of-the-art methods and our ablation studies confirm the effectiveness of our method and its individual component. To our best knowledge, we are the first to successfully conduct condensation on ImageNet-1k.
Free-ATM: Exploring Unsupervised Learning on Diffusion-Generated Images with Free Attention Masks
Aug 13, 2023Despite the rapid advancement of unsupervised learning in visual representation, it requires training on large-scale datasets that demand costly data collection, and pose additional challenges due to concerns regarding data privacy. Recently, synthetic images generated by text-to-image diffusion models, have shown great potential for benefiting image recognition. Although promising, there has been inadequate exploration dedicated to unsupervised learning on diffusion-generated images. To address this, we start by uncovering that diffusion models' cross-attention layers inherently provide annotation-free attention masks aligned with corresponding text inputs on generated images. We then investigate the problems of three prevalent unsupervised learning techniques ( i.e., contrastive learning, masked modeling, and vision-language pretraining) and introduce customized solutions by fully exploiting the aforementioned free attention masks. Our approach is validated through extensive experiments that show consistent improvements in baseline models across various downstream tasks, including image classification, detection, segmentation, and image-text retrieval. By utilizing our method, it is possible to close the performance gap between unsupervised pretraining on synthetic data and real-world scenarios.
Lowis3D: Language-Driven Open-World Instance-Level 3D Scene Understanding
Aug 01, 2023



Open-world instance-level scene understanding aims to locate and recognize unseen object categories that are not present in the annotated dataset. This task is challenging because the model needs to both localize novel 3D objects and infer their semantic categories. A key factor for the recent progress in 2D open-world perception is the availability of large-scale image-text pairs from the Internet, which cover a wide range of vocabulary concepts. However, this success is hard to replicate in 3D scenarios due to the scarcity of 3D-text pairs. To address this challenge, we propose to harness pre-trained vision-language (VL) foundation models that encode extensive knowledge from image-text pairs to generate captions for multi-view images of 3D scenes. This allows us to establish explicit associations between 3D shapes and semantic-rich captions. Moreover, to enhance the fine-grained visual-semantic representation learning from captions for object-level categorization, we design hierarchical point-caption association methods to learn semantic-aware embeddings that exploit the 3D geometry between 3D points and multi-view images. In addition, to tackle the localization challenge for novel classes in the open-world setting, we develop debiased instance localization, which involves training object grouping modules on unlabeled data using instance-level pseudo supervision. This significantly improves the generalization capabilities of instance grouping and thus the ability to accurately locate novel objects. We conduct extensive experiments on 3D semantic, instance, and panoptic segmentation tasks, covering indoor and outdoor scenes across three datasets. Our method outperforms baseline methods by a significant margin in semantic segmentation (e.g. 34.5%$\sim$65.3%), instance segmentation (e.g. 21.8%$\sim$54.0%) and panoptic segmentation (e.g. 14.7%$\sim$43.3%). Code will be available.
DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
Jul 09, 2023



Precise and controllable image editing is a challenging task that has attracted significant attention. Recently, DragGAN enables an interactive point-based image editing framework and achieves impressive editing results with pixel-level precision. However, since this method is based on generative adversarial networks (GAN), its generality is upper-bounded by the capacity of the pre-trained GAN models. In this work, we extend such an editing framework to diffusion models and propose DragDiffusion. By leveraging large-scale pretrained diffusion models, we greatly improve the applicability of interactive point-based editing in real world scenarios. While most existing diffusion-based image editing methods work on text embeddings, DragDiffusion optimizes the diffusion latent to achieve precise spatial control. Although diffusion models generate images in an iterative manner, we empirically show that optimizing diffusion latent at one single step suffices to generate coherent results, enabling DragDiffusion to complete high-quality editing efficiently. Extensive experiments across a wide range of challenging cases (e.g., multi-objects, diverse object categories, various styles, etc.) demonstrate the versatility and generality of DragDiffusion. Code: https://github.com/Yujun-Shi/DragDiffusion.
Domain Adaptive Scene Text Detection via Subcategorization
Dec 01, 2022Most existing scene text detectors require large-scale training data which cannot scale well due to two major factors: 1) scene text images often have domain-specific distributions; 2) collecting large-scale annotated scene text images is laborious. We study domain adaptive scene text detection, a largely neglected yet very meaningful task that aims for optimal transfer of labelled scene text images while handling unlabelled images in various new domains. Specifically, we design SCAST, a subcategory-aware self-training technique that mitigates the network overfitting and noisy pseudo labels in domain adaptive scene text detection effectively. SCAST consists of two novel designs. For labelled source data, it introduces pseudo subcategories for both foreground texts and background stuff which helps train more generalizable source models with multi-class detection objectives. For unlabelled target data, it mitigates the network overfitting by co-regularizing the binary and subcategory classifiers trained in the source domain. Extensive experiments show that SCAST achieves superior detection performance consistently across multiple public benchmarks, and it also generalizes well to other domain adaptive detection tasks such as vehicle detection.
Language-driven Open-Vocabulary 3D Scene Understanding
Nov 29, 2022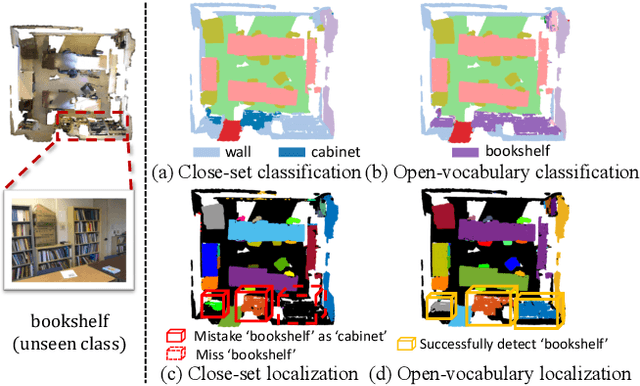
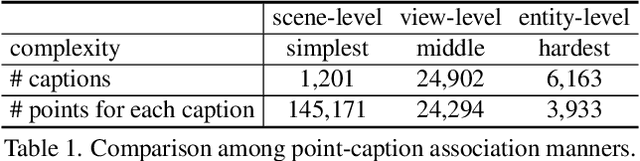
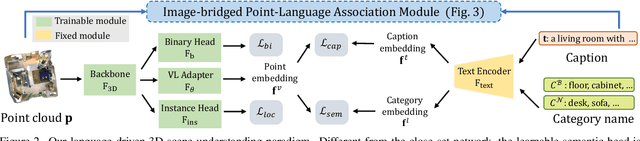
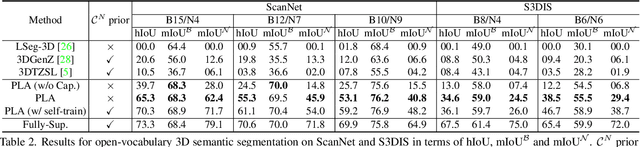
Open-vocabulary scene understanding aims to localize and recognize unseen categories beyond the annotated label space. The recent breakthrough of 2D open-vocabulary perception is largely driven by Internet-scale paired image-text data with rich vocabulary concepts. However, this success cannot be directly transferred to 3D scenarios due to the inaccessibility of large-scale 3D-text pairs. To this end, we propose to distill knowledge encoded in pre-trained vision-language (VL) foundation models through captioning multi-view images from 3D, which allows explicitly associating 3D and semantic-rich captions. Further, to facilitate coarse-to-fine visual-semantic representation learning from captions, we design hierarchical 3D-caption pairs, leveraging geometric constraints between 3D scenes and multi-view images. Finally, by employing contrastive learning, the model learns language-aware embeddings that connect 3D and text for open-vocabulary tasks. Our method not only remarkably outperforms baseline methods by 25.8% $\sim$ 44.7% hIoU and 14.5% $\sim$ 50.4% hAP$_{50}$ on open-vocabulary semantic and instance segmentation, but also shows robust transferability on challenging zero-shot domain transfer tasks. Code will be available at https://github.com/CVMI-Lab/PLA.
Is synthetic data from generative models ready for image recognition?
Oct 14, 2022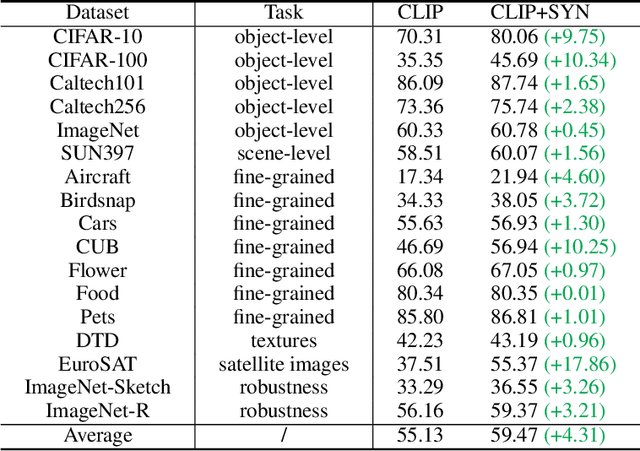
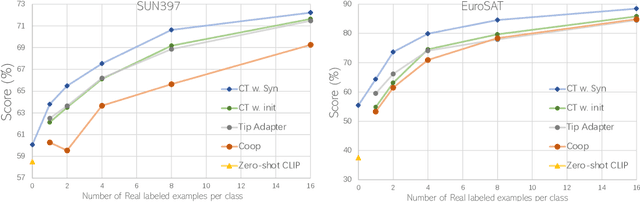
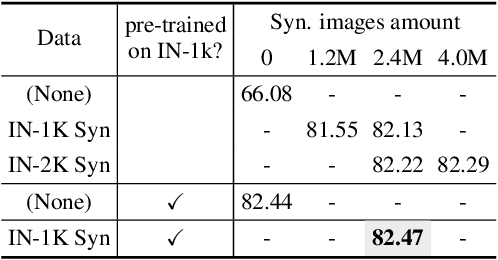

Recent text-to-image generation models have shown promising results in generating high-fidelity photo-realistic images. Though the results are astonishing to human eyes, how applicable these generated images are for recognition tasks remains under-explored. In this work, we extensively study whether and how synthetic images generated from state-of-the-art text-to-image generation models can be used for image recognition tasks, and focus on two perspectives: synthetic data for improving classification models in data-scarce settings (i.e. zero-shot and few-shot), and synthetic data for large-scale model pre-training for transfer learning. We showcase the powerfulness and shortcomings of synthetic data from existing generative models, and propose strategies for better applying synthetic data for recognition tasks. Code: https://github.com/CVMI-Lab/SyntheticData.
1st Place Solution to ECCV 2022 Challenge on Out of Vocabulary Scene Text Understanding: Cropped Word Recognition
Aug 04, 2022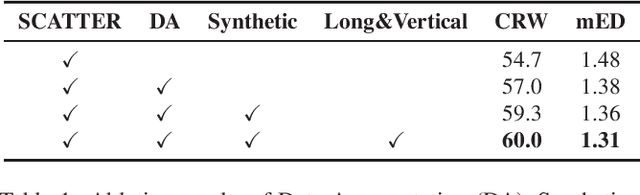


This report presents our winner solution to ECCV 2022 challenge on Out-of-Vocabulary Scene Text Understanding (OOV-ST) : Cropped Word Recognition. This challenge is held in the context of ECCV 2022 workshop on Text in Everything (TiE), which aims to extract out-of-vocabulary words from natural scene images. In the competition, we first pre-train SCATTER on the synthetic datasets, then fine-tune the model on the training set with data augmentations. Meanwhile, two additional models are trained specifically for long and vertical texts. Finally, we combine the output from different models with different layers, different backbones, and different seeds as the final results. Our solution achieves an overall word accuracy of 69.73% when considering both in-vocabulary and out-of-vocabulary words.
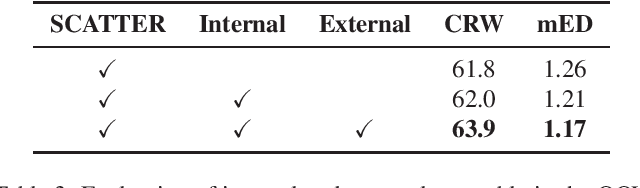
Contextual Text Block Detection towards Scene Text Understanding
Jul 26, 2022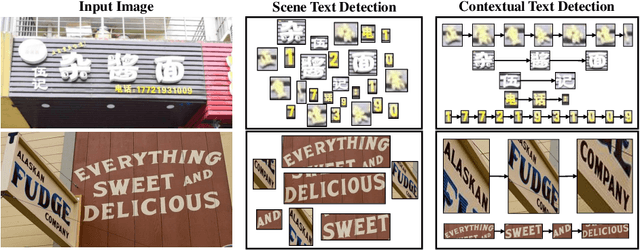

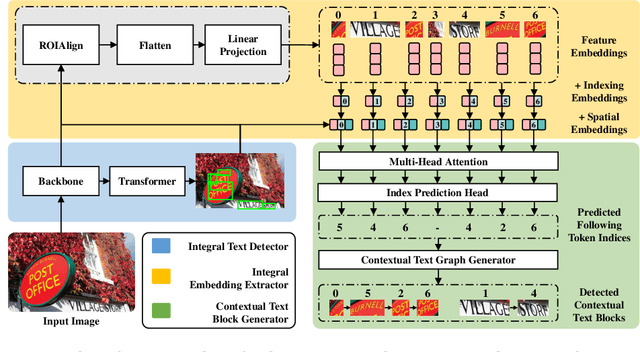

Most existing scene text detectors focus on detecting characters or words that only capture partial text messages due to missing contextual information. For a better understanding of text in scenes, it is more desired to detect contextual text blocks (CTBs) which consist of one or multiple integral text units (e.g., characters, words, or phrases) in natural reading order and transmit certain complete text messages. This paper presents contextual text detection, a new setup that detects CTBs for better understanding of texts in scenes. We formulate the new setup by a dual detection task which first detects integral text units and then groups them into a CTB. To this end, we design a novel scene text clustering technique that treats integral text units as tokens and groups them (belonging to the same CTB) into an ordered token sequence. In addition, we create two datasets SCUT-CTW-Context and ReCTS-Context to facilitate future research, where each CTB is well annotated by an ordered sequence of integral text units. Further, we introduce three metrics that measure contextual text detection in local accuracy, continuity, and global accuracy. Extensive experiments show that our method accurately detects CTBs which effectively facilitates downstream tasks such as text classification and translation. The project is available at https://sg-vilab.github.io/publication/xue2022contextual/.