 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteerVTE: Seamless Video Text Editing with Style and Glyph Control
Jun 22, 2026Visual text editing aims to precisely modify text in images and videos while preserving stylistic consistency and visual realism. Despite significant advances in the image domain, video text editing remains largely unexplored: it is a localized task demanding stroke-level precision within small text regions, which compounds the challenges of cross-frame accuracy, temporal coherence, and stylistic fidelity. We introduce SteerVTE, a unified framework that \underline{\textbf{steer}}s a frozen video diffusion model to perform precise \underline{\textbf{V}}ideo \underline{\textbf{T}}ext \underline{\textbf{E}}diting through style and glyph control. Built on a frozen diffusion transformer, SteerVTE attaches a lightweight text context adapter with two complementary modules: a style encoder capturing the original text's visual attributes, and dual-granularity glyph encoders encoding the target text at both the line and character levels. To overcome the inherently weak text rendering priors of video foundation models, we further propose a glyph-aware spatial-focal loss and a three-stage progressive training curriculum that scales from image to video data. To support large-scale training, we also develop an automatic synthesis pipeline and construct SteerVTE-1M, a dataset of one million triplets spanning diverse scenes, fonts, and stylistic effects. Extensive experiments demonstrate that SteerVTE substantially outperforms existing video editing baselines across text accuracy, style consistency, and temporal coherence.
TextSculptor: Training and Benchmarking Scene Text Editing
May 20, 2026Recent advances in Multimodal Large Language Models (MLLMs) and diffusion-based generative models have substantially improved prompt-driven image editing. However, scene text editing remains challenging, as it requires models to precisely modify textual content while preserving visual realism and non-target regions. Current open-source models still lag behind proprietary systems, largely due to the scarcity of high-quality training data and the lack of standardized benchmarks tailored to text editing. To address these challenges, we present TextSculptor, a comprehensive framework for data construction and evaluation of scene text editing. We first develop an automated data construction pipeline that combines text-aware image synthesis with programmatic text rendering and compositing. Based on this pipeline, we build TextSculpt-Data, a large-scale dataset containing 3.2M training samples, including 1.2M OCR-verified text-to-image samples and 2M paired text editing samples with naturally aligned source-target images and strong background consistency. We further introduce TextSculpt-Bench, a benchmark covering four fundamental text editing tasks: text addition, text replacement, text removal, and hybrid editing. To support reliable evaluation, we design a tailored protocol that measures text accuracy, visual quality, and background preservation through OCR-based text alignment, multimodal judgment, and background-region similarity. Extensive experiments show that TextSculptor improves open-source text editing performance and narrows the gap to proprietary models. The data and benchmark are available at https://github.com/linyiheng123/TextSculptor.
Preference-Based Self-Distillation: Beyond KL Matching via Reward Regularization
May 06, 2026On-policy distillation is an efficient alternative to reinforcement learning, offering dense token-level training signals. However, its reliance on a stronger external teacher has driven recent work on on-policy self-distillation, where the same model serves as both teacher and student under different prompt contexts. Yet, existing self-distillation methods largely reduce learning to KL matching toward the context-augmented teacher model. This approach often suffers from training instability and can degrade reasoning performance over time. Moreover, self-distillation from the same model with prompt augmentation lacks the exploratory diversity provided by a genuine external teacher. To address these limitations, we move beyond fixed-teacher KL matching and propose \textbf{P}reference-\textbf{B}ased \textbf{S}elf-\textbf{D}istillation (\textbf{PBSD}), which revisits on-policy self-distillation through a reward-regularized perspective. Instead of directly matching the teacher distribution, we derive a reward-regularized objective whose analytic optimum is a reward-reweighted teacher distribution, yielding a target policy provably superior to the original teacher under this objective. Practically, PBSD optimizes preference gaps between teacher and student samples while maintaining on-policy student sampling. We support this framework with a statistical analysis of the induced preference-learning problem, formally establishing when on policy self-distillation is preferable to learning from an external teacher in our setting. Experiments on mathematical reasoning and tool-use benchmarks across multiple model scales demonstrate that PBSD consistently achieves the strongest average performance among comparable baselines, showing improved training stability over prior self-distillation baselines while preserving token efficiency.
Monocular Normal Estimation via Shading Sequence Estimation
Feb 11, 2026Monocular normal estimation aims to estimate the normal map from a single RGB image of an object under arbitrary lights. Existing methods rely on deep models to directly predict normal maps. However, they often suffer from 3D misalignment: while the estimated normal maps may appear to have a correct appearance, the reconstructed surfaces often fail to align with the geometric details. We argue that this misalignment stems from the current paradigm: the model struggles to distinguish and reconstruct varying geometry represented in normal maps, as the differences in underlying geometry are reflected only through relatively subtle color variations. To address this issue, we propose a new paradigm that reformulates normal estimation as shading sequence estimation, where shading sequences are more sensitive to various geometric information. Building on this paradigm, we present RoSE, a method that leverages image-to-video generative models to predict shading sequences. The predicted shading sequences are then converted into normal maps by solving a simple ordinary least-squares problem. To enhance robustness and better handle complex objects, RoSE is trained on a synthetic dataset, MultiShade, with diverse shapes, materials, and light conditions. Experiments demonstrate that RoSE achieves state-of-the-art performance on real-world benchmark datasets for object-based monocular normal estimation.
ThinkGen: Generalized Thinking for Visual Generation
Dec 29, 2025Recent progress in Multimodal Large Language Models (MLLMs) demonstrates that Chain-of-Thought (CoT) reasoning enables systematic solutions to complex understanding tasks. However, its extension to generation tasks remains nascent and limited by scenario-specific mechanisms that hinder generalization and adaptation. In this work, we present ThinkGen, the first think-driven visual generation framework that explicitly leverages MLLM's CoT reasoning in various generation scenarios. ThinkGen employs a decoupled architecture comprising a pretrained MLLM and a Diffusion Transformer (DiT), wherein the MLLM generates tailored instructions based on user intent, and DiT produces high-quality images guided by these instructions. We further propose a separable GRPO-based training paradigm (SepGRPO), alternating reinforcement learning between the MLLM and DiT modules. This flexible design enables joint training across diverse datasets, facilitating effective CoT reasoning for a wide range of generative scenarios. Extensive experiments demonstrate that ThinkGen achieves robust, state-of-the-art performance across multiple generation benchmarks. Code is available: https://github.com/jiaosiyuu/ThinkGen
CodeDance: A Dynamic Tool-integrated MLLM for Executable Visual Reasoning
Dec 19, 2025Recent releases such as o3 highlight human-like "thinking with images" reasoning that combines structured tool use with stepwise verification, yet most open-source approaches still rely on text-only chains, rigid visual schemas, or single-step pipelines, limiting flexibility, interpretability, and transferability on complex tasks. We introduce CodeDance, which explores executable code as a general solver for visual reasoning. Unlike fixed-schema calls (e.g., only predicting bounding-box coordinates), CodeDance defines, composes, and executes code to orchestrate multiple tools, compute intermediate results, and render visual artifacts (e.g., boxes, lines, plots) that support transparent, self-checkable reasoning. To guide this process, we introduce a reward for balanced and adaptive tool-call, which balances exploration with efficiency and mitigates tool overuse. Interestingly, beyond the expected capabilities taught by atomic supervision, we empirically observe novel emergent behaviors during RL training: CodeDance demonstrates novel tool invocations, unseen compositions, and cross-task transfer. These behaviors arise without task-specific fine-tuning, suggesting a general and scalable mechanism of executable visual reasoning. Extensive experiments across reasoning benchmarks (e.g., visual search, math, chart QA) show that CodeDance not only consistently outperforms schema-driven and text-only baselines, but also surpasses advanced closed models such as GPT-4o and larger open-source models.
GUI-Rise: Structured Reasoning and History Summarization for GUI Navigation
Oct 31, 2025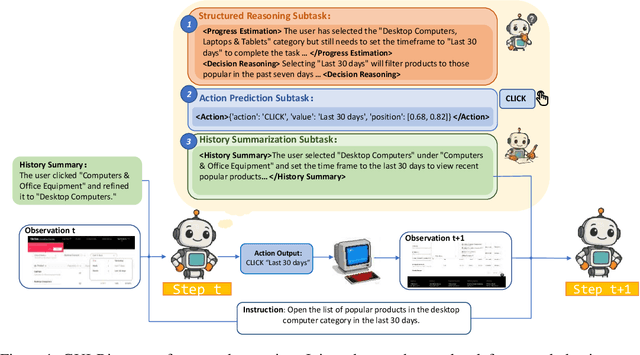
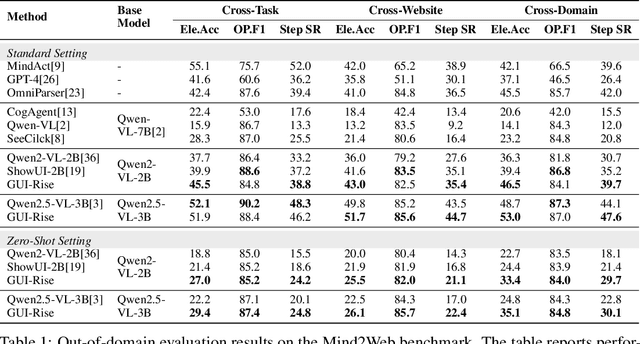
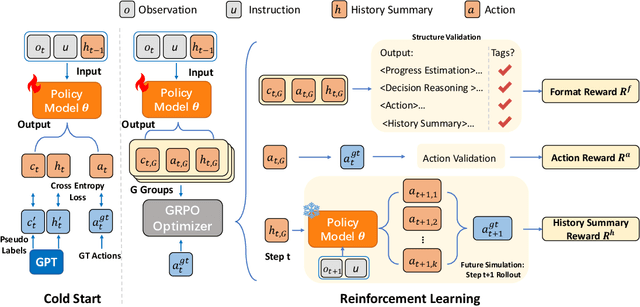
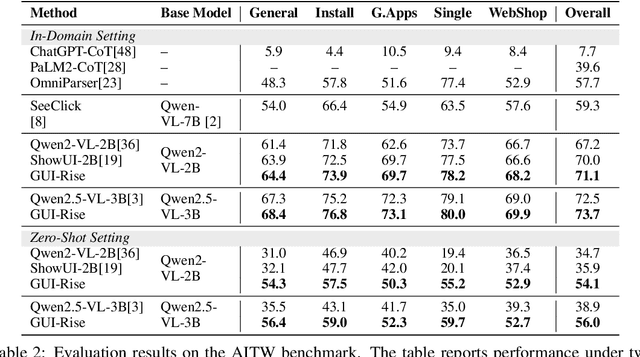
While Multimodal Large Language Models (MLLMs) have advanced GUI navigation agents, current approaches face limitations in cross-domain generalization and effective history utilization. We present a reasoning-enhanced framework that systematically integrates structured reasoning, action prediction, and history summarization. The structured reasoning component generates coherent Chain-of-Thought analyses combining progress estimation and decision reasoning, which inform both immediate action predictions and compact history summaries for future steps. Based on this framework, we train a GUI agent, \textbf{GUI-Rise}, through supervised fine-tuning on pseudo-labeled trajectories and reinforcement learning with Group Relative Policy Optimization (GRPO). This framework employs specialized rewards, including a history-aware objective, directly linking summary quality to subsequent action performance. Comprehensive evaluations on standard benchmarks demonstrate state-of-the-art results under identical training data conditions, with particularly strong performance in out-of-domain scenarios. These findings validate our framework's ability to maintain robust reasoning and generalization across diverse GUI navigation tasks. Code is available at https://leon022.github.io/GUI-Rise.
Debiasing Text-to-Image Diffusion Models
Feb 22, 2024Learning-based Text-to-Image (TTI) models like Stable Diffusion have revolutionized the way visual content is generated in various domains. However, recent research has shown that nonnegligible social bias exists in current state-of-the-art TTI systems, which raises important concerns. In this work, we target resolving the social bias in TTI diffusion models. We begin by formalizing the problem setting and use the text descriptions of bias groups to establish an unsafe direction for guiding the diffusion process. Next, we simplify the problem into a weight optimization problem and attempt a Reinforcement solver, Policy Gradient, which shows sub-optimal performance with slow convergence. Further, to overcome limitations, we propose an iterative distribution alignment (IDA) method. Despite its simplicity, we show that IDA shows efficiency and fast convergence in resolving the social bias in TTI diffusion models. Our code will be released.
Pose-Free Neural Radiance Fields via Implicit Pose Regularization
Aug 29, 2023
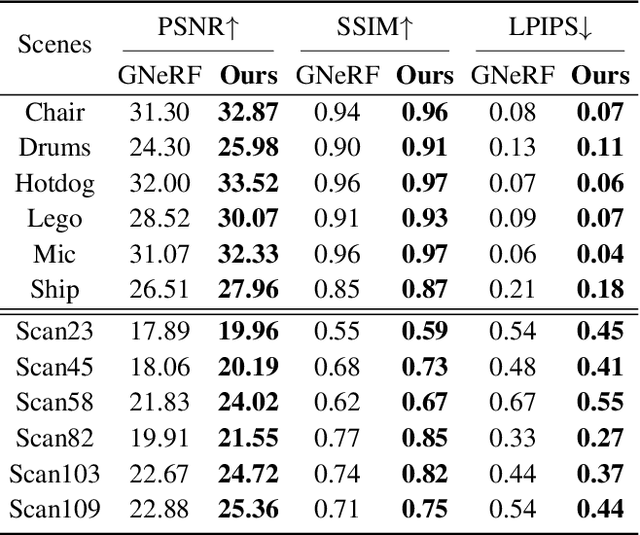
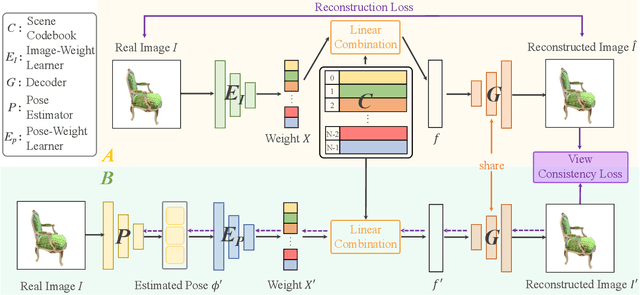

Pose-free neural radiance fields (NeRF) aim to train NeRF with unposed multi-view images and it has achieved very impressive success in recent years. Most existing works share the pipeline of training a coarse pose estimator with rendered images at first, followed by a joint optimization of estimated poses and neural radiance field. However, as the pose estimator is trained with only rendered images, the pose estimation is usually biased or inaccurate for real images due to the domain gap between real images and rendered images, leading to poor robustness for the pose estimation of real images and further local minima in joint optimization. We design IR-NeRF, an innovative pose-free NeRF that introduces implicit pose regularization to refine pose estimator with unposed real images and improve the robustness of the pose estimation for real images. With a collection of 2D images of a specific scene, IR-NeRF constructs a scene codebook that stores scene features and captures the scene-specific pose distribution implicitly as priors. Thus, the robustness of pose estimation can be promoted with the scene priors according to the rationale that a 2D real image can be well reconstructed from the scene codebook only when its estimated pose lies within the pose distribution. Extensive experiments show that IR-NeRF achieves superior novel view synthesis and outperforms the state-of-the-art consistently across multiple synthetic and real datasets.
WaveNeRF: Wavelet-based Generalizable Neural Radiance Fields
Aug 09, 2023
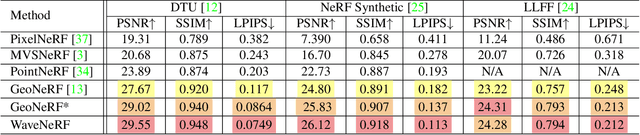
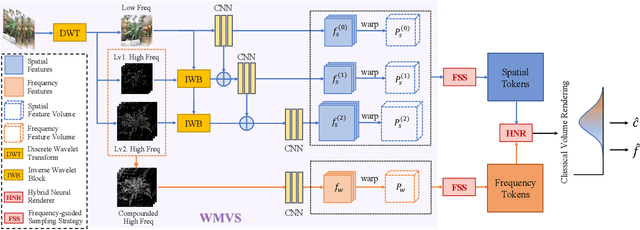

Neural Radiance Field (NeRF) has shown impressive performance in novel view synthesis via implicit scene representation. However, it usually suffers from poor scalability as requiring densely sampled images for each new scene. Several studies have attempted to mitigate this problem by integrating Multi-View Stereo (MVS) technique into NeRF while they still entail a cumbersome fine-tuning process for new scenes. Notably, the rendering quality will drop severely without this fine-tuning process and the errors mainly appear around the high-frequency features. In the light of this observation, we design WaveNeRF, which integrates wavelet frequency decomposition into MVS and NeRF to achieve generalizable yet high-quality synthesis without any per-scene optimization. To preserve high-frequency information when generating 3D feature volumes, WaveNeRF builds Multi-View Stereo in the Wavelet domain by integrating the discrete wavelet transform into the classical cascade MVS, which disentangles high-frequency information explicitly. With that, disentangled frequency features can be injected into classic NeRF via a novel hybrid neural renderer to yield faithful high-frequency details, and an intuitive frequency-guided sampling strategy can be designed to suppress artifacts around high-frequency regions. Extensive experiments over three widely studied benchmarks show that WaveNeRF achieves superior generalizable radiance field modeling when only given three images as input.