 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleGaussian: Instant 3D Style Transfer with Gaussian Splatting
Mar 12, 2024



We introduce StyleGaussian, a novel 3D style transfer technique that allows instant transfer of any image's style to a 3D scene at 10 frames per second (fps). Leveraging 3D Gaussian Splatting (3DGS), StyleGaussian achieves style transfer without compromising its real-time rendering ability and multi-view consistency. It achieves instant style transfer with three steps: embedding, transfer, and decoding. Initially, 2D VGG scene features are embedded into reconstructed 3D Gaussians. Next, the embedded features are transformed according to a reference style image. Finally, the transformed features are decoded into the stylized RGB. StyleGaussian has two novel designs. The first is an efficient feature rendering strategy that first renders low-dimensional features and then maps them into high-dimensional features while embedding VGG features. It cuts the memory consumption significantly and enables 3DGS to render the high-dimensional memory-intensive features. The second is a K-nearest-neighbor-based 3D CNN. Working as the decoder for the stylized features, it eliminates the 2D CNN operations that compromise strict multi-view consistency. Extensive experiments show that StyleGaussian achieves instant 3D stylization with superior stylization quality while preserving real-time rendering and strict multi-view consistency. Project page: https://kunhao-liu.github.io/StyleGaussian/
FreGS: 3D Gaussian Splatting with Progressive Frequency Regularization
Mar 11, 2024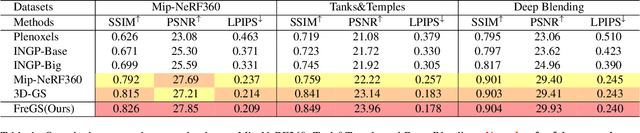
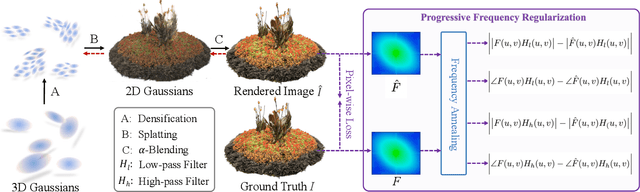
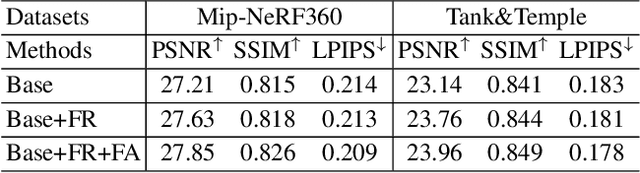
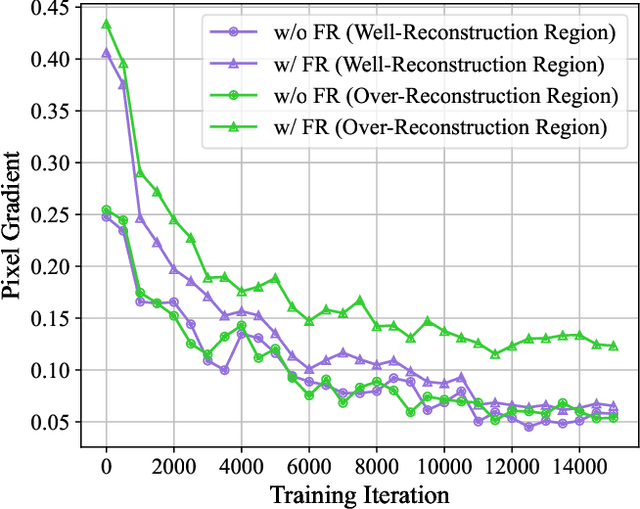
3D Gaussian splatting has achieved very impressive performance in real-time novel view synthesis. However, it often suffers from over-reconstruction during Gaussian densification where high-variance image regions are covered by a few large Gaussians only, leading to blur and artifacts in the rendered images. We design a progressive frequency regularization (FreGS) technique to tackle the over-reconstruction issue within the frequency space. Specifically, FreGS performs coarse-to-fine Gaussian densification by exploiting low-to-high frequency components that can be easily extracted with low-pass and high-pass filters in the Fourier space. By minimizing the discrepancy between the frequency spectrum of the rendered image and the corresponding ground truth, it achieves high-quality Gaussian densification and alleviates the over-reconstruction of Gaussian splatting effectively. Experiments over multiple widely adopted benchmarks (e.g., Mip-NeRF360, Tanks-and-Temples and Deep Blending) show that FreGS achieves superior novel view synthesis and outperforms the state-of-the-art consistently.
AI-Generated Images as Data Source: The Dawn of Synthetic Era
Oct 09, 2023
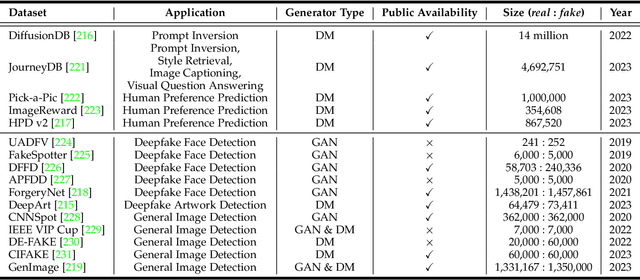


The advancement of visual intelligence is intrinsically tethered to the availability of data. In parallel, generative Artificial Intelligence (AI) has unlocked the potential to create synthetic images that closely resemble real-world photographs, which prompts a compelling inquiry: how visual intelligence benefit from the advance of generative AI? This paper explores the innovative concept of harnessing these AI-generated images as a new data source, reshaping traditional model paradigms in visual intelligence. In contrast to real data, AI-generated data sources exhibit remarkable advantages, including unmatched abundance and scalability, the rapid generation of vast datasets, and the effortless simulation of edge cases. Built on the success of generative AI models, we examines the potential of their generated data in a range of applications, from training machine learning models to simulating scenarios for computational modeling, testing, and validation. We probe the technological foundations that support this groundbreaking use of generative AI, engaging in an in-depth discussion on the ethical, legal, and practical considerations that accompany this transformative paradigm shift. Through an exhaustive survey of current technologies and applications, this paper presents a comprehensive view of the synthetic era in visual intelligence. A project associated with this paper can be found at https://github.com/mwxely/AIGS .
WaveNeRF: Wavelet-based Generalizable Neural Radiance Fields
Aug 09, 2023
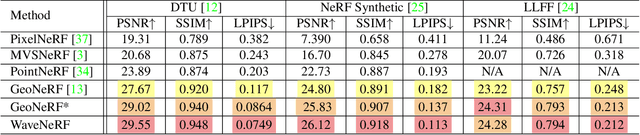
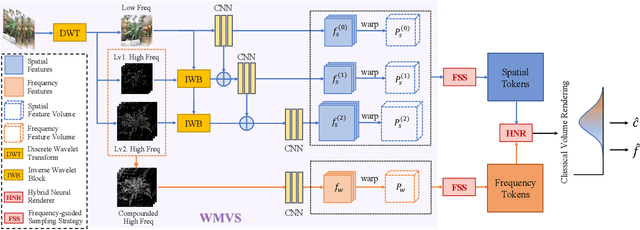

Neural Radiance Field (NeRF) has shown impressive performance in novel view synthesis via implicit scene representation. However, it usually suffers from poor scalability as requiring densely sampled images for each new scene. Several studies have attempted to mitigate this problem by integrating Multi-View Stereo (MVS) technique into NeRF while they still entail a cumbersome fine-tuning process for new scenes. Notably, the rendering quality will drop severely without this fine-tuning process and the errors mainly appear around the high-frequency features. In the light of this observation, we design WaveNeRF, which integrates wavelet frequency decomposition into MVS and NeRF to achieve generalizable yet high-quality synthesis without any per-scene optimization. To preserve high-frequency information when generating 3D feature volumes, WaveNeRF builds Multi-View Stereo in the Wavelet domain by integrating the discrete wavelet transform into the classical cascade MVS, which disentangles high-frequency information explicitly. With that, disentangled frequency features can be injected into classic NeRF via a novel hybrid neural renderer to yield faithful high-frequency details, and an intuitive frequency-guided sampling strategy can be designed to suppress artifacts around high-frequency regions. Extensive experiments over three widely studied benchmarks show that WaveNeRF achieves superior generalizable radiance field modeling when only given three images as input.
3D Open-vocabulary Segmentation with Foundation Models
May 24, 2023



Open-vocabulary segmentation of 3D scenes is a fundamental function of human perception and thus a crucial objective in computer vision research. However, this task is heavily impeded by the lack of large-scale and diverse 3D open-vocabulary segmentation datasets for training robust and generalizable models. Distilling knowledge from pre-trained 2D open-vocabulary segmentation models helps but it compromises the open-vocabulary feature significantly as the 2D models are mostly finetuned with close-vocabulary datasets. We tackle the challenges in 3D open-vocabulary segmentation by exploiting the open-vocabulary multimodal knowledge and object reasoning capability of pre-trained foundation models CLIP and DINO, without necessitating any fine-tuning. Specifically, we distill open-vocabulary visual and textual knowledge from CLIP into a neural radiance field (NeRF) which effectively lifts 2D features into view-consistent 3D segmentation. Furthermore, we introduce the Relevancy-Distribution Alignment loss and Feature-Distribution Alignment loss to respectively mitigate the ambiguities of CLIP features and distill precise object boundaries from DINO features, eliminating the need for segmentation annotations during training. Extensive experiments show that our method even outperforms fully supervised models trained with segmentation annotations, suggesting that 3D open-vocabulary segmentation can be effectively learned from 2D images and text-image pairs.