 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
Apr 06, 2026Video question answering (VideoQA) is a challenging task that requires integrating spatial, temporal, and semantic information to capture the complex dynamics of video sequences. Although recent advances have introduced various approaches for video understanding, most existing methods still rely on locating relevant frames to answer questions rather than reasoning through the evolving storyline as humans do. Humans naturally interpret videos through coherent storylines, an ability that is crucial for making robust and contextually grounded predictions. To address this gap, we propose SVAgent, a storyline-guided cross-modal multi-agent framework for VideoQA. The storyline agent progressively constructs a narrative representation based on frames suggested by a refinement suggestion agent that analyzes historical failures. In addition, cross-modal decision agents independently predict answers from visual and textual modalities under the guidance of the evolving storyline. Their outputs are then evaluated by a meta-agent to align cross-modal predictions and enhance reasoning robustness and answer consistency. Experimental results demonstrate that SVAgent achieves superior performance and interpretability by emulating human-like storyline reasoning in video understanding.
A Comprehensive Study on Visual Token Redundancy for Discrete Diffusion-based Multimodal Large Language Models
Nov 19, 2025Discrete diffusion-based multimodal large language models (dMLLMs) have emerged as a promising alternative to autoregressive MLLMs thanks to their advantages in parallel decoding and bidirectional context modeling, but most existing dMLLMs incur significant computational overhead during inference due to the full-sequence attention computation in each denoising step. Pioneer studies attempt to resolve this issue from a modality-agnostic perspective via key-value cache optimization or efficient sampling but most of them overlook modality-specific visual token redundancy. In this work, we conduct a comprehensive study on how visual token redundancy evolves with different dMLLM architectures and tasks and how visual token pruning affects dMLLM responses and efficiency. Specifically, our study reveals that visual redundancy emerges only in from-scratch dMLLMs while handling long-answer tasks. In addition, we validate that visual token pruning introduces non-negligible information loss in dMLLMs and only from-scratch dMLLMs can recover the lost information progressively during late denoising steps. Furthermore, our study shows that layer-skipping is promising for accelerating AR-to-diffusion dMLLMs, whereas progressive or late-step pruning is more effective for from-scratch dMLLMs. Overall, this work offers a new perspective on efficiency optimization for dMLLMs, greatly advancing their applicability across various multimodal understanding tasks.
ToDRE: Visual Token Pruning via Diversity and Task Awareness for Efficient Large Vision-Language Models
May 24, 2025
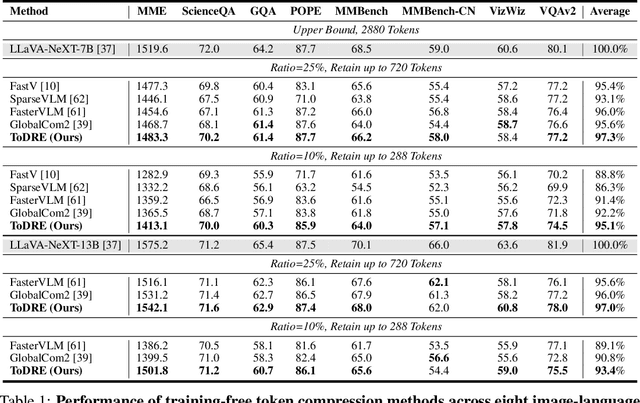
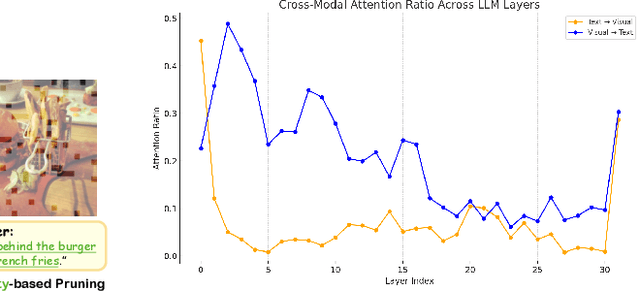
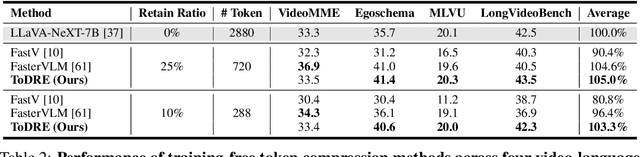
The representation of visual inputs of large vision-language models (LVLMs) usually involves substantially more tokens than that of textual inputs, leading to significant computational overhead. Several recent studies strive to mitigate this issue by either conducting token compression to prune redundant visual tokens or guiding them to bypass certain computational stages. While most existing work exploits token importance as the redundancy indicator, our study reveals that two largely neglected factors, namely, the diversity of retained visual tokens and their task relevance, often offer more robust criteria in token pruning. To this end, we design ToDRE, a two-stage and training-free token compression framework that achieves superior performance by pruning Tokens based on token Diversity and token-task RElevance. Instead of pruning redundant tokens, ToDRE introduces a greedy k-center algorithm to select and retain a small subset of diverse visual tokens after the vision encoder. Additionally, ToDRE addresses the "information migration" by further eliminating task-irrelevant visual tokens within the decoder of large language model (LLM). Extensive experiments show that ToDRE effectively reduces 90% of visual tokens after vision encoder and adaptively prunes all visual tokens within certain LLM's decoder layers, leading to a 2.6x speed-up in total inference time while maintaining 95.1% of model performance and excellent compatibility with efficient attention operators.
AI-Generated Images as Data Source: The Dawn of Synthetic Era
Oct 09, 2023
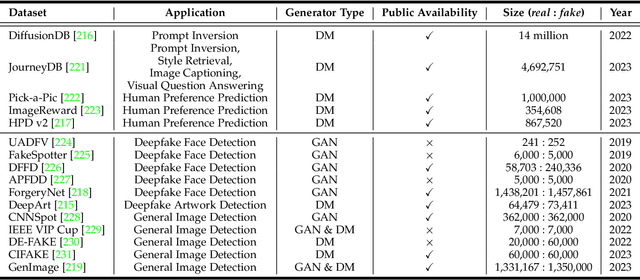


The advancement of visual intelligence is intrinsically tethered to the availability of data. In parallel, generative Artificial Intelligence (AI) has unlocked the potential to create synthetic images that closely resemble real-world photographs, which prompts a compelling inquiry: how visual intelligence benefit from the advance of generative AI? This paper explores the innovative concept of harnessing these AI-generated images as a new data source, reshaping traditional model paradigms in visual intelligence. In contrast to real data, AI-generated data sources exhibit remarkable advantages, including unmatched abundance and scalability, the rapid generation of vast datasets, and the effortless simulation of edge cases. Built on the success of generative AI models, we examines the potential of their generated data in a range of applications, from training machine learning models to simulating scenarios for computational modeling, testing, and validation. We probe the technological foundations that support this groundbreaking use of generative AI, engaging in an in-depth discussion on the ethical, legal, and practical considerations that accompany this transformative paradigm shift. Through an exhaustive survey of current technologies and applications, this paper presents a comprehensive view of the synthetic era in visual intelligence. A project associated with this paper can be found at https://github.com/mwxely/AIGS .
FACE: Evaluating Natural Language Generation with Fourier Analysis of Cross-Entropy
May 18, 2023Measuring the distance between machine-produced and human language is a critical open problem. Inspired by empirical findings from psycholinguistics on the periodicity of entropy in language, we propose FACE, a set of metrics based on Fourier Analysis of the estimated Cross-Entropy of language, for measuring the similarity between model-generated and human-written languages. Based on an open-ended generation task and the experimental data from previous studies, we find that FACE can effectively identify the human-model gap, scales with model size, reflects the outcomes of different sampling methods for decoding, correlates well with other evaluation metrics and with human judgment scores. FACE is computationally efficient and provides intuitive interpretations.
PaCaNet: A Study on CycleGAN with Transfer Learning for Diversifying Fused Chinese Painting and Calligraphy
Feb 01, 2023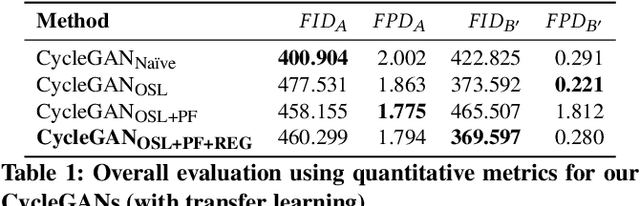

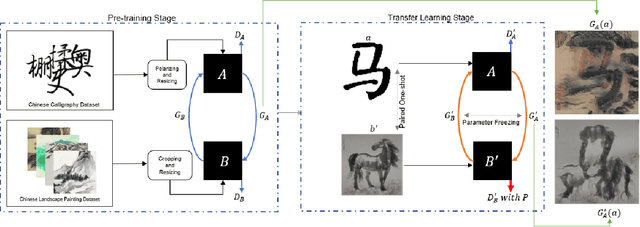

AI-Generated Content (AIGC) has recently gained a surge in popularity, powered by its high efficiency and consistency in production, and its capability of being customized and diversified. The cross-modality nature of the representation learning mechanism in most AIGC technology allows for more freedom and flexibility in exploring new types of art that would be impossible in the past. Inspired by the pictogram subset of Chinese characters, we proposed PaCaNet, a CycleGAN-based pipeline for producing novel artworks that fuse two different art types, traditional Chinese painting and calligraphy. In an effort to produce stable and diversified output, we adopted three main technical innovations: 1. Using one-shot learning to increase the creativity of pre-trained models and diversify the content of the fused images. 2. Controlling the preference over generated Chinese calligraphy by freezing randomly sampled parameters in pre-trained models. 3. Using a regularization method to encourage the models to produce images similar to Chinese paintings. Furthermore, we conducted a systematic study to explore the performance of PaCaNet in diversifying fused Chinese painting and calligraphy, which showed satisfying results. In conclusion, we provide a new direction of creating arts by fusing the visual information in paintings and the stroke features in Chinese calligraphy. Our approach creates a unique aesthetic experience rooted in the origination of Chinese hieroglyph characters. It is also a unique opportunity to delve deeper into traditional artwork and, in doing so, to create a meaningful impact on preserving and revitalizing traditional heritage.