 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
InteractAvatar: Modeling Hand-Face Interaction in Photorealistic Avatars with Deformable Gaussians
Apr 10, 2025With the rising interest from the community in digital avatars coupled with the importance of expressions and gestures in communication, modeling natural avatar behavior remains an important challenge across many industries such as teleconferencing, gaming, and AR/VR. Human hands are the primary tool for interacting with the environment and essential for realistic human behavior modeling, yet existing 3D hand and head avatar models often overlook the crucial aspect of hand-body interactions, such as between hand and face. We present InteracttAvatar, the first model to faithfully capture the photorealistic appearance of dynamic hand and non-rigid hand-face interactions. Our novel Dynamic Gaussian Hand model, combining template model and 3D Gaussian Splatting as well as a dynamic refinement module, captures pose-dependent change, e.g. the fine wrinkles and complex shadows that occur during articulation. Importantly, our hand-face interaction module models the subtle geometry and appearance dynamics that underlie common gestures. Through experiments of novel view synthesis, self reenactment and cross-identity reenactment, we demonstrate that InteracttAvatar can reconstruct hand and hand-face interactions from monocular or multiview videos with high-fidelity details and be animated with novel poses.
FoundHand: Large-Scale Domain-Specific Learning for Controllable Hand Image Generation
Dec 03, 2024



Despite remarkable progress in image generation models, generating realistic hands remains a persistent challenge due to their complex articulation, varying viewpoints, and frequent occlusions. We present FoundHand, a large-scale domain-specific diffusion model for synthesizing single and dual hand images. To train our model, we introduce FoundHand-10M, a large-scale hand dataset with 2D keypoints and segmentation mask annotations. Our insight is to use 2D hand keypoints as a universal representation that encodes both hand articulation and camera viewpoint. FoundHand learns from image pairs to capture physically plausible hand articulations, natively enables precise control through 2D keypoints, and supports appearance control. Our model exhibits core capabilities that include the ability to repose hands, transfer hand appearance, and even synthesize novel views. This leads to zero-shot capabilities for fixing malformed hands in previously generated images, or synthesizing hand video sequences. We present extensive experiments and evaluations that demonstrate state-of-the-art performance of our method.
MANUS: Markerless Hand-Object Grasp Capture using Articulated 3D Gaussians
Dec 04, 2023



Understanding how we grasp objects with our hands has important applications in areas like robotics and mixed reality. However, this challenging problem requires accurate modeling of the contact between hands and objects. To capture grasps, existing methods use skeletons, meshes, or parametric models that can cause misalignments resulting in inaccurate contacts. We present MANUS, a method for Markerless Hand-Object Grasp Capture using Articulated 3D Gaussians. We build a novel articulated 3D Gaussians representation that extends 3D Gaussian splatting for high-fidelity representation of articulating hands. Since our representation uses Gaussian primitives, it enables us to efficiently and accurately estimate contacts between the hand and the object. For the most accurate results, our method requires tens of camera views that current datasets do not provide. We therefore build MANUS-Grasps, a new dataset that contains hand-object grasps viewed from 53 cameras across 30+ scenes, 3 subjects, and comprising over 7M frames. In addition to extensive qualitative results, we also show that our method outperforms others on a quantitative contact evaluation method that uses paint transfer from the object to the hand.
DiVA-360: The Dynamic Visuo-Audio Dataset for Immersive Neural Fields
Jul 31, 2023
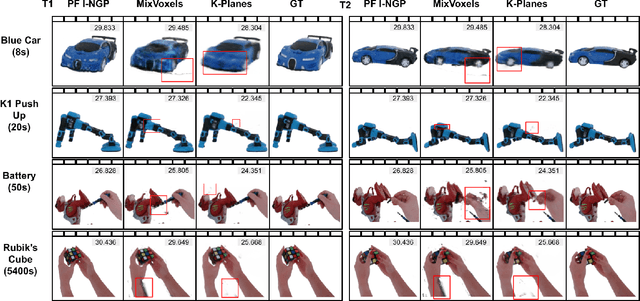
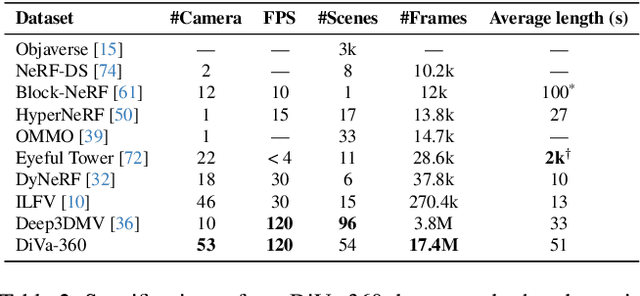

Advances in neural fields are enabling high-fidelity capture of the shape and appearance of static and dynamic scenes. However, their capabilities lag behind those offered by representations such as pixels or meshes due to algorithmic challenges and the lack of large-scale real-world datasets. We address the dataset limitation with DiVA-360, a real-world 360 dynamic visual-audio dataset with synchronized multimodal visual, audio, and textual information about table-scale scenes. It contains 46 dynamic scenes, 30 static scenes, and 95 static objects spanning 11 categories captured using a new hardware system using 53 RGB cameras at 120 FPS and 6 microphones for a total of 8.6M image frames and 1360 s of dynamic data. We provide detailed text descriptions for all scenes, foreground-background segmentation masks, category-specific 3D pose alignment for static objects, as well as metrics for comparison. Our data, hardware and software, and code are available at https://diva360.github.io/.
FACE: Evaluating Natural Language Generation with Fourier Analysis of Cross-Entropy
May 18, 2023Measuring the distance between machine-produced and human language is a critical open problem. Inspired by empirical findings from psycholinguistics on the periodicity of entropy in language, we propose FACE, a set of metrics based on Fourier Analysis of the estimated Cross-Entropy of language, for measuring the similarity between model-generated and human-written languages. Based on an open-ended generation task and the experimental data from previous studies, we find that FACE can effectively identify the human-model gap, scales with model size, reflects the outcomes of different sampling methods for decoding, correlates well with other evaluation metrics and with human judgment scores. FACE is computationally efficient and provides intuitive interpretations.
Communicating Complex Decisions in Robot-Assisted Therapy
Mar 24, 2023Socially Assistive Robots (SARs) have shown promising potential in therapeutic scenarios as decision-making instructors or motivational companions. In human-human therapy, experts often communicate the thought process behind the decisions they make to promote transparency and build trust. As research aims to incorporate more complex decision-making models into these robots to drive better interaction, the ability for the SAR to explain its decisions becomes an increasing challenge. We present the latest examples of complex SAR decision-makers. We argue that, based on the importance of transparent communication in human-human therapy, SARs should incorporate such components into their design. To stimulate discussion around this topic, we present a set of design considerations for researchers.
Wide-Baseline Relative Camera Pose Estimation with Directional Learning
Jun 07, 2021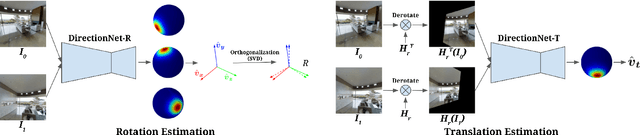
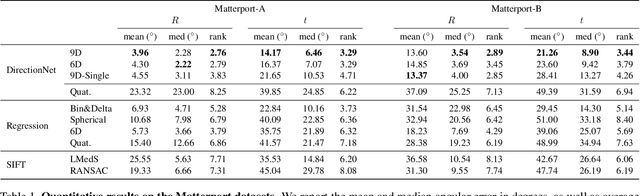
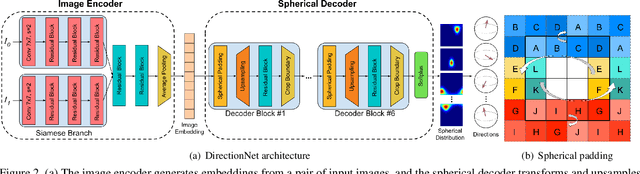
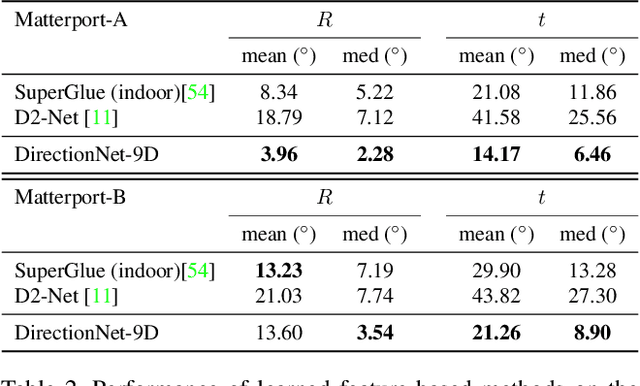
Modern deep learning techniques that regress the relative camera pose between two images have difficulty dealing with challenging scenarios, such as large camera motions resulting in occlusions and significant changes in perspective that leave little overlap between images. These models continue to struggle even with the benefit of large supervised training datasets. To address the limitations of these models, we take inspiration from techniques that show regressing keypoint locations in 2D and 3D can be improved by estimating a discrete distribution over keypoint locations. Analogously, in this paper we explore improving camera pose regression by instead predicting a discrete distribution over camera poses. To realize this idea, we introduce DirectionNet, which estimates discrete distributions over the 5D relative pose space using a novel parameterization to make the estimation problem tractable. Specifically, DirectionNet factorizes relative camera pose, specified by a 3D rotation and a translation direction, into a set of 3D direction vectors. Since 3D directions can be identified with points on the sphere, DirectionNet estimates discrete distributions on the sphere as its output. We evaluate our model on challenging synthetic and real pose estimation datasets constructed from Matterport3D and InteriorNet. Promising results show a near 50% reduction in error over direct regression methods.
An Analysis of SVD for Deep Rotation Estimation
Jun 25, 2020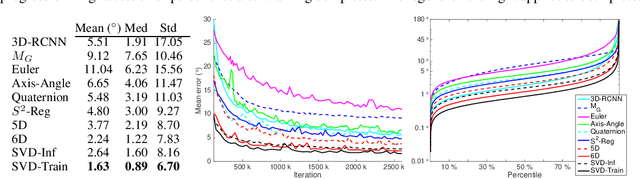
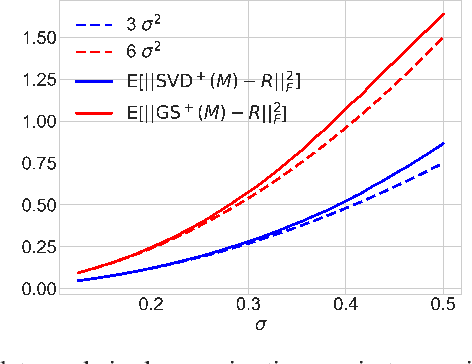
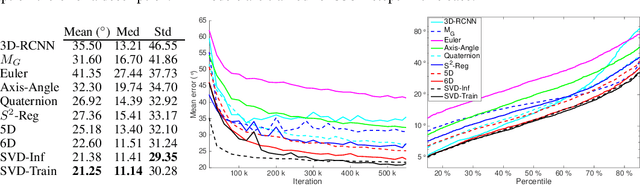
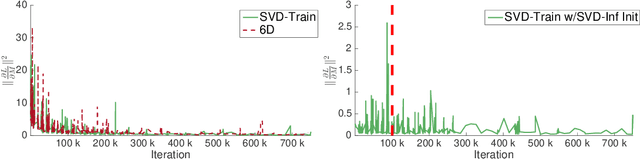
Symmetric orthogonalization via SVD, and closely related procedures, are well-known techniques for projecting matrices onto $O(n)$ or $SO(n)$. These tools have long been used for applications in computer vision, for example optimal 3D alignment problems solved by orthogonal Procrustes, rotation averaging, or Essential matrix decomposition. Despite its utility in different settings, SVD orthogonalization as a procedure for producing rotation matrices is typically overlooked in deep learning models, where the preferences tend toward classic representations like unit quaternions, Euler angles, and axis-angle, or more recently-introduced methods. Despite the importance of 3D rotations in computer vision and robotics, a single universally effective representation is still missing. Here, we explore the viability of SVD orthogonalization for 3D rotations in neural networks. We present a theoretical analysis that shows SVD is the natural choice for projecting onto the rotation group. Our extensive quantitative analysis shows simply replacing existing representations with the SVD orthogonalization procedure obtains state of the art performance in many deep learning applications covering both supervised and unsupervised training.
ImmuNetNAS: An Immune-network approach for searching Convolutional Neural Network Architectures
Feb 28, 2020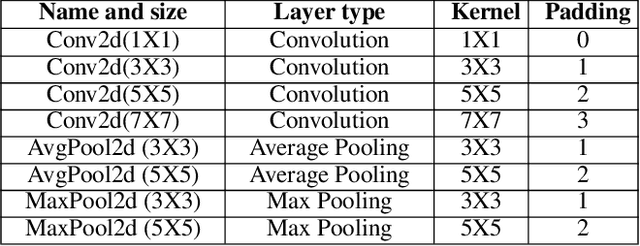
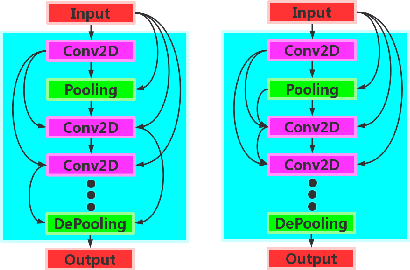
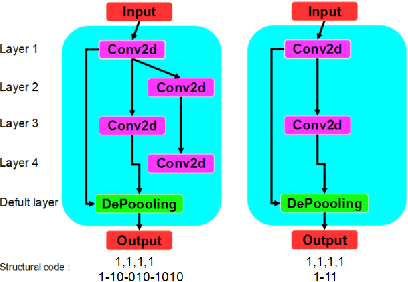
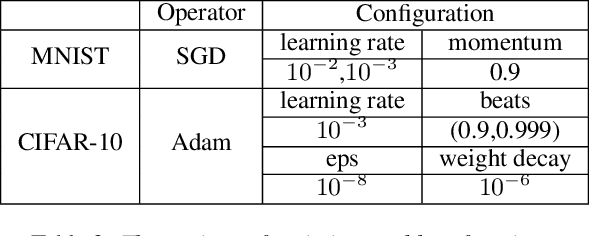
In this research, we propose ImmuNetNAS, a novel Neural Architecture Search (NAS) approach inspired by the immune network theory. The core of ImmuNetNAS is built on the original immune network algorithm, which iteratively updates the population through hypermutation and selection, and eliminates the self-generation individuals that do not meet the requirements through comparing antibody affinity and inter-specific similarity. In addition, in order to facilitate the mutation operation, we propose a novel two-component based neural structure coding strategy. Furthermore, an improved mutation strategy based on Standard Genetic Algorithm (SGA) was proposed according to this encoding method. Finally, based on the proposed two-component based coding method, a new antibody affinity calculation method was developed to screen suitable neural architectures. Systematic evaluations demonstrate that our system has achieved good performance on both the MNIST and CIFAR-10 datasets. We open-source our code on GitHub in order to share it with other deep learning researchers and practitioners.