 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePackUV: Packed Gaussian UV Maps for 4D Volumetric Video
Feb 26, 2026Volumetric videos offer immersive 4D experiences, but remain difficult to reconstruct, store, and stream at scale. Existing Gaussian Splatting based methods achieve high-quality reconstruction but break down on long sequences, temporal inconsistency, and fail under large motions and disocclusions. Moreover, their outputs are typically incompatible with conventional video coding pipelines, preventing practical applications. We introduce PackUV, a novel 4D Gaussian representation that maps all Gaussian attributes into a sequence of structured, multi-scale UV atlas, enabling compact, image-native storage. To fit this representation from multi-view videos, we propose PackUV-GS, a temporally consistent fitting method that directly optimizes Gaussian parameters in the UV domain. A flow-guided Gaussian labeling and video keyframing module identifies dynamic Gaussians, stabilizes static regions, and preserves temporal coherence even under large motions and disocclusions. The resulting UV atlas format is the first unified volumetric video representation compatible with standard video codecs (e.g., FFV1) without losing quality, enabling efficient streaming within existing multimedia infrastructure. To evaluate long-duration volumetric capture, we present PackUV-2B, the largest multi-view video dataset to date, featuring more than 50 synchronized cameras, substantial motion, and frequent disocclusions across 100 sequences and 2B (billion) frames. Extensive experiments demonstrate that our method surpasses existing baselines in rendering fidelity while scaling to sequences up to 30 minutes with consistent quality.
* https://ivl.cs.brown.edu/packuv
Turbo-GS: Accelerating 3D Gaussian Fitting for High-Quality Radiance Fields
Dec 18, 2024



Novel-view synthesis is an important problem in computer vision with applications in 3D reconstruction, mixed reality, and robotics. Recent methods like 3D Gaussian Splatting (3DGS) have become the preferred method for this task, providing high-quality novel views in real time. However, the training time of a 3DGS model is slow, often taking 30 minutes for a scene with 200 views. In contrast, our goal is to reduce the optimization time by training for fewer steps while maintaining high rendering quality. Specifically, we combine the guidance from both the position error and the appearance error to achieve a more effective densification. To balance the rate between adding new Gaussians and fitting old Gaussians, we develop a convergence-aware budget control mechanism. Moreover, to make the densification process more reliable, we selectively add new Gaussians from mostly visited regions. With these designs, we reduce the Gaussian optimization steps to one-third of the previous approach while achieving a comparable or even better novel view rendering quality. To further facilitate the rapid fitting of 4K resolution images, we introduce a dilation-based rendering technique. Our method, Turbo-GS, speeds up optimization for typical scenes and scales well to high-resolution (4K) scenarios on standard datasets. Through extensive experiments, we show that our method is significantly faster in optimization than other methods while retaining quality. Project page: https://ivl.cs.brown.edu/research/turbo-gs.
MANUS: Markerless Hand-Object Grasp Capture using Articulated 3D Gaussians
Dec 04, 2023



Understanding how we grasp objects with our hands has important applications in areas like robotics and mixed reality. However, this challenging problem requires accurate modeling of the contact between hands and objects. To capture grasps, existing methods use skeletons, meshes, or parametric models that can cause misalignments resulting in inaccurate contacts. We present MANUS, a method for Markerless Hand-Object Grasp Capture using Articulated 3D Gaussians. We build a novel articulated 3D Gaussians representation that extends 3D Gaussian splatting for high-fidelity representation of articulating hands. Since our representation uses Gaussian primitives, it enables us to efficiently and accurately estimate contacts between the hand and the object. For the most accurate results, our method requires tens of camera views that current datasets do not provide. We therefore build MANUS-Grasps, a new dataset that contains hand-object grasps viewed from 53 cameras across 30+ scenes, 3 subjects, and comprising over 7M frames. In addition to extensive qualitative results, we also show that our method outperforms others on a quantitative contact evaluation method that uses paint transfer from the object to the hand.
DiVA-360: The Dynamic Visuo-Audio Dataset for Immersive Neural Fields
Jul 31, 2023
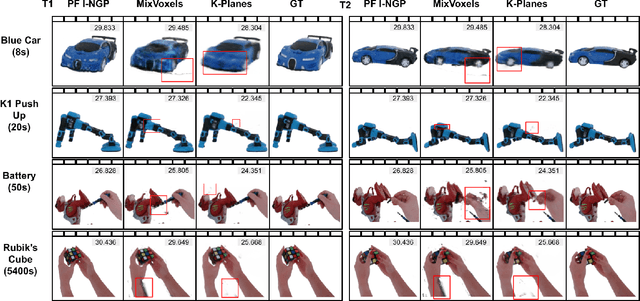
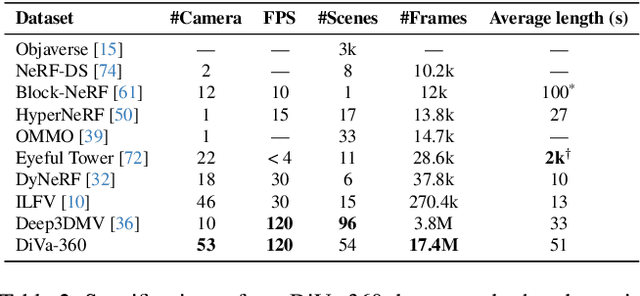

Advances in neural fields are enabling high-fidelity capture of the shape and appearance of static and dynamic scenes. However, their capabilities lag behind those offered by representations such as pixels or meshes due to algorithmic challenges and the lack of large-scale real-world datasets. We address the dataset limitation with DiVA-360, a real-world 360 dynamic visual-audio dataset with synchronized multimodal visual, audio, and textual information about table-scale scenes. It contains 46 dynamic scenes, 30 static scenes, and 95 static objects spanning 11 categories captured using a new hardware system using 53 RGB cameras at 120 FPS and 6 microphones for a total of 8.6M image frames and 1360 s of dynamic data. We provide detailed text descriptions for all scenes, foreground-background segmentation masks, category-specific 3D pose alignment for static objects, as well as metrics for comparison. Our data, hardware and software, and code are available at https://diva360.github.io/.