 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANUS: Markerless Hand-Object Grasp Capture using Articulated 3D Gaussians
Dec 04, 2023



Understanding how we grasp objects with our hands has important applications in areas like robotics and mixed reality. However, this challenging problem requires accurate modeling of the contact between hands and objects. To capture grasps, existing methods use skeletons, meshes, or parametric models that can cause misalignments resulting in inaccurate contacts. We present MANUS, a method for Markerless Hand-Object Grasp Capture using Articulated 3D Gaussians. We build a novel articulated 3D Gaussians representation that extends 3D Gaussian splatting for high-fidelity representation of articulating hands. Since our representation uses Gaussian primitives, it enables us to efficiently and accurately estimate contacts between the hand and the object. For the most accurate results, our method requires tens of camera views that current datasets do not provide. We therefore build MANUS-Grasps, a new dataset that contains hand-object grasps viewed from 53 cameras across 30+ scenes, 3 subjects, and comprising over 7M frames. In addition to extensive qualitative results, we also show that our method outperforms others on a quantitative contact evaluation method that uses paint transfer from the object to the hand.
DiVA-360: The Dynamic Visuo-Audio Dataset for Immersive Neural Fields
Jul 31, 2023
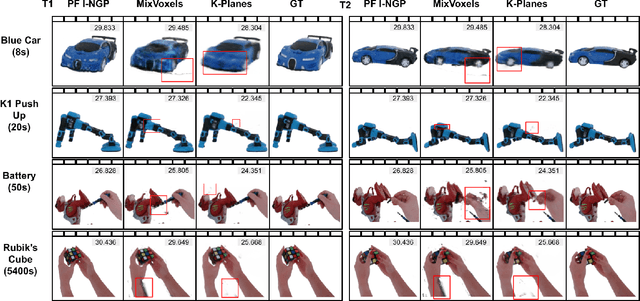
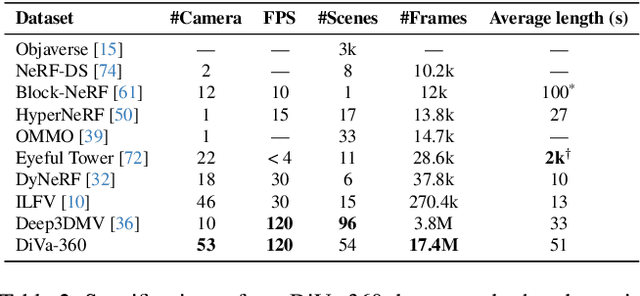

Advances in neural fields are enabling high-fidelity capture of the shape and appearance of static and dynamic scenes. However, their capabilities lag behind those offered by representations such as pixels or meshes due to algorithmic challenges and the lack of large-scale real-world datasets. We address the dataset limitation with DiVA-360, a real-world 360 dynamic visual-audio dataset with synchronized multimodal visual, audio, and textual information about table-scale scenes. It contains 46 dynamic scenes, 30 static scenes, and 95 static objects spanning 11 categories captured using a new hardware system using 53 RGB cameras at 120 FPS and 6 microphones for a total of 8.6M image frames and 1360 s of dynamic data. We provide detailed text descriptions for all scenes, foreground-background segmentation masks, category-specific 3D pose alignment for static objects, as well as metrics for comparison. Our data, hardware and software, and code are available at https://diva360.github.io/.
xCloth: Extracting Template-free Textured 3D Clothes from a Monocular Image
Aug 27, 2022

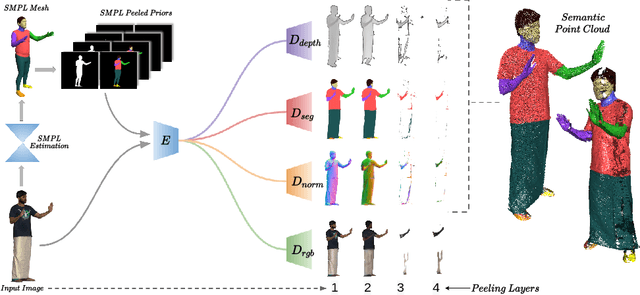
Existing approaches for 3D garment reconstruction either assume a predefined template for the garment geometry (restricting them to fixed clothing styles) or yield vertex colored meshes (lacking high-frequency textural details). Our novel framework co-learns geometric and semantic information of garment surface from the input monocular image for template-free textured 3D garment digitization. More specifically, we propose to extend PeeledHuman representation to predict the pixel-aligned, layered depth and semantic maps to extract 3D garments. The layered representation is further exploited to UV parametrize the arbitrary surface of the extracted garment without any human intervention to form a UV atlas. The texture is then imparted on the UV atlas in a hybrid fashion by first projecting pixels from the input image to UV space for the visible region, followed by inpainting the occluded regions. Thus, we are able to digitize arbitrarily loose clothing styles while retaining high-frequency textural details from a monocular image. We achieve high-fidelity 3D garment reconstruction results on three publicly available datasets and generalization on internet images.
SHARP: Shape-Aware Reconstruction of People in Loose Clothing
May 24, 2022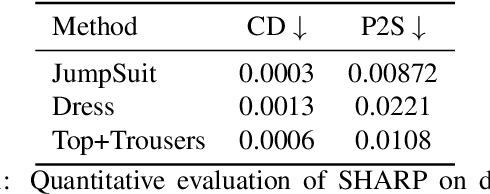
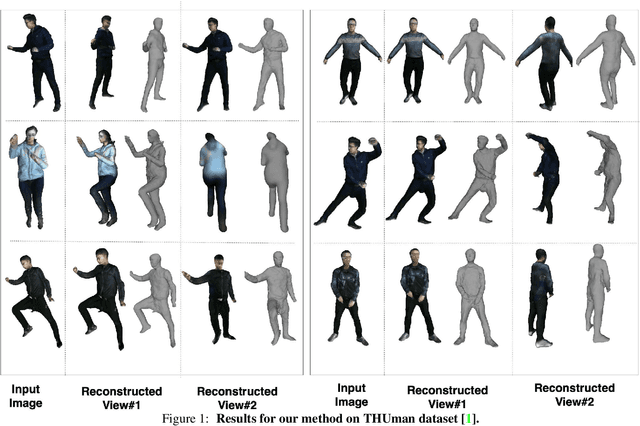
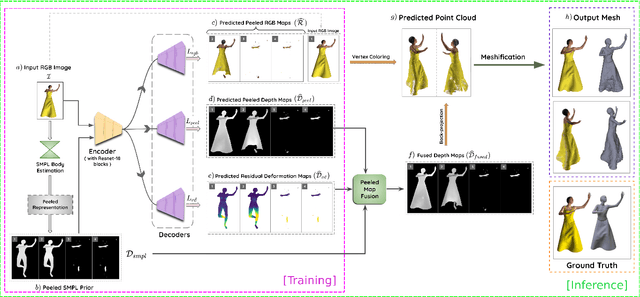
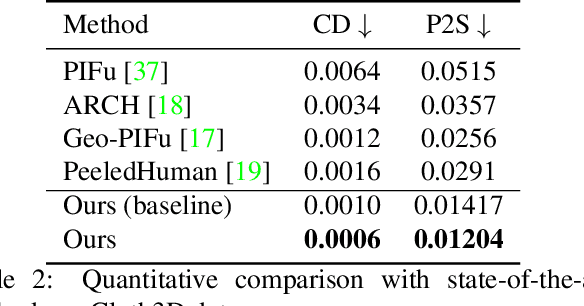
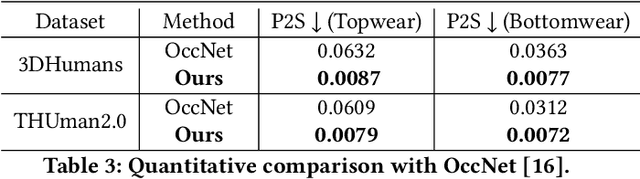
Recent advancements in deep learning have enabled 3D human body reconstruction from a monocular image, which has broad applications in multiple domains. In this paper, we propose SHARP (SHape Aware Reconstruction of People in loose clothing), a novel end-to-end trainable network that accurately recovers the 3D geometry and appearance of humans in loose clothing from a monocular image. SHARP uses a sparse and efficient fusion strategy to combine parametric body prior with a non-parametric 2D representation of clothed humans. The parametric body prior enforces geometrical consistency on the body shape and pose, while the non-parametric representation models loose clothing and handle self-occlusions as well. We also leverage the sparseness of the non-parametric representation for faster training of our network while using losses on 2D maps. Another key contribution is 3DHumans, our new life-like dataset of 3D human body scans with rich geometrical and textural details. We evaluate SHARP on 3DHumans and other publicly available datasets and show superior qualitative and quantitative performance than existing state-of-the-art methods.