 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightHeadEd: Relightable & Editable Head Avatars from a Smartphone
Apr 13, 2025Creating photorealistic, animatable, and relightable 3D head avatars traditionally requires expensive Lightstage with multiple calibrated cameras, making it inaccessible for widespread adoption. To bridge this gap, we present a novel, cost-effective approach for creating high-quality relightable head avatars using only a smartphone equipped with polaroid filters. Our approach involves simultaneously capturing cross-polarized and parallel-polarized video streams in a dark room with a single point-light source, separating the skin's diffuse and specular components during dynamic facial performances. We introduce a hybrid representation that embeds 2D Gaussians in the UV space of a parametric head model, facilitating efficient real-time rendering while preserving high-fidelity geometric details. Our learning-based neural analysis-by-synthesis pipeline decouples pose and expression-dependent geometrical offsets from appearance, decomposing the surface into albedo, normal, and specular UV texture maps, along with the environment maps. We collect a unique dataset of various subjects performing diverse facial expressions and head movements.
GSN: Generalisable Segmentation in Neural Radiance Field
Feb 07, 2024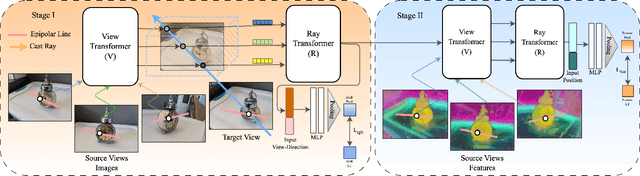
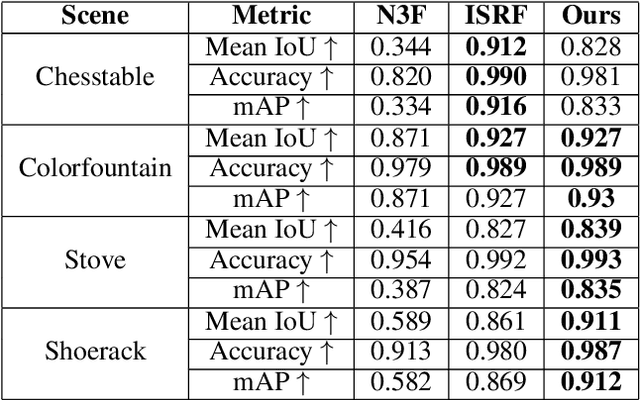


Traditional Radiance Field (RF) representations capture details of a specific scene and must be trained afresh on each scene. Semantic feature fields have been added to RFs to facilitate several segmentation tasks. Generalised RF representations learn the principles of view interpolation. A generalised RF can render new views of an unknown and untrained scene, given a few views. We present a way to distil feature fields into the generalised GNT representation. Our GSN representation generates new views of unseen scenes on the fly along with consistent, per-pixel semantic features. This enables multi-view segmentation of arbitrary new scenes. We show different semantic features being distilled into generalised RFs. Our multi-view segmentation results are on par with methods that use traditional RFs. GSN closes the gap between standard and generalisable RF methods significantly. Project Page: https://vinayak-vg.github.io/GSN/
StyleTRF: Stylizing Tensorial Radiance Fields
Dec 19, 2022Stylized view generation of scenes captured casually using a camera has received much attention recently. The geometry and appearance of the scene are typically captured as neural point sets or neural radiance fields in the previous work. An image stylization method is used to stylize the captured appearance by training its network jointly or iteratively with the structure capture network. The state-of-the-art SNeRF method trains the NeRF and stylization network in an alternating manner. These methods have high training time and require joint optimization. In this work, we present StyleTRF, a compact, quick-to-optimize strategy for stylized view generation using TensoRF. The appearance part is fine-tuned using sparse stylized priors of a few views rendered using the TensoRF representation for a few iterations. Our method thus effectively decouples style-adaption from view capture and is much faster than the previous methods. We show state-of-the-art results on several scenes used for this purpose.
Casual Indoor HDR Radiance Capture from Omnidirectional Images
Aug 16, 2022
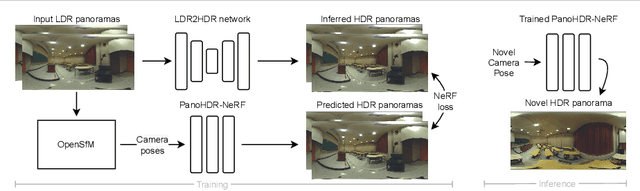


We present PanoHDR-NeRF, a novel pipeline to casually capture a plausible full HDR radiance field of a large indoor scene without elaborate setups or complex capture protocols. First, a user captures a low dynamic range (LDR) omnidirectional video of the scene by freely waving an off-the-shelf camera around the scene. Then, an LDR2HDR network uplifts the captured LDR frames to HDR, subsequently used to train a tailored NeRF++ model. The resulting PanoHDR-NeRF pipeline can estimate full HDR panoramas from any location of the scene. Through experiments on a novel test dataset of a variety of real scenes with the ground truth HDR radiance captured at locations not seen during training, we show that PanoHDR-NeRF predicts plausible radiance from any scene point. We also show that the HDR images produced by PanoHDR-NeRF can synthesize correct lighting effects, enabling the augmentation of indoor scenes with synthetic objects that are lit correctly.
SHARP: Shape-Aware Reconstruction of People in Loose Clothing
May 24, 2022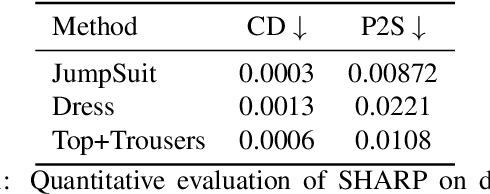
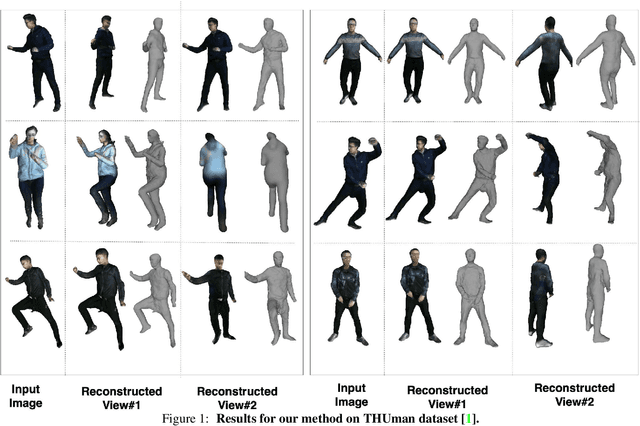
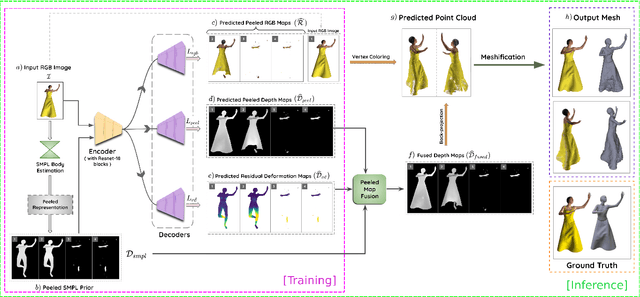
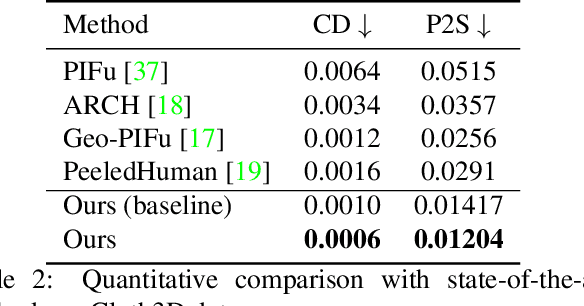
Recent advancements in deep learning have enabled 3D human body reconstruction from a monocular image, which has broad applications in multiple domains. In this paper, we propose SHARP (SHape Aware Reconstruction of People in loose clothing), a novel end-to-end trainable network that accurately recovers the 3D geometry and appearance of humans in loose clothing from a monocular image. SHARP uses a sparse and efficient fusion strategy to combine parametric body prior with a non-parametric 2D representation of clothed humans. The parametric body prior enforces geometrical consistency on the body shape and pose, while the non-parametric representation models loose clothing and handle self-occlusions as well. We also leverage the sparseness of the non-parametric representation for faster training of our network while using losses on 2D maps. Another key contribution is 3DHumans, our new life-like dataset of 3D human body scans with rich geometrical and textural details. We evaluate SHARP on 3DHumans and other publicly available datasets and show superior qualitative and quantitative performance than existing state-of-the-art methods.
Appearance Editing with Free-viewpoint Neural Rendering
Oct 14, 2021



We present a neural rendering framework for simultaneous view synthesis and appearance editing of a scene from multi-view images captured under known environment illumination. Existing approaches either achieve view synthesis alone or view synthesis along with relighting, without direct control over the scene's appearance. Our approach explicitly disentangles the appearance and learns a lighting representation that is independent of it. Specifically, we independently estimate the BRDF and use it to learn a lighting-only representation of the scene. Such disentanglement allows our approach to generalize to arbitrary changes in appearance while performing view synthesis. We show results of editing the appearance of a real scene, demonstrating that our approach produces plausible appearance editing. The performance of our view synthesis approach is demonstrated to be at par with state-of-the-art approaches on both real and synthetic data.
SHARP: Shape-Aware Reconstruction of People In Loose Clothing
Jun 17, 20213D human body reconstruction from monocular images is an interesting and ill-posed problem in computer vision with wider applications in multiple domains. In this paper, we propose SHARP, a novel end-to-end trainable network that accurately recovers the detailed geometry and appearance of 3D people in loose clothing from a monocular image. We propose a sparse and efficient fusion of a parametric body prior with a non-parametric peeled depth map representation of clothed models. The parametric body prior constraints our model in two ways: first, the network retains geometrically consistent body parts that are not occluded by clothing, and second, it provides a body shape context that improves prediction of the peeled depth maps. This enables SHARP to recover fine-grained 3D geometrical details with just L1 losses on the 2D maps, given an input image. We evaluate SHARP on publicly available Cloth3D and THuman datasets and report superior performance to state-of-the-art approaches.
Geometric Scene Refocusing
Dec 20, 2020


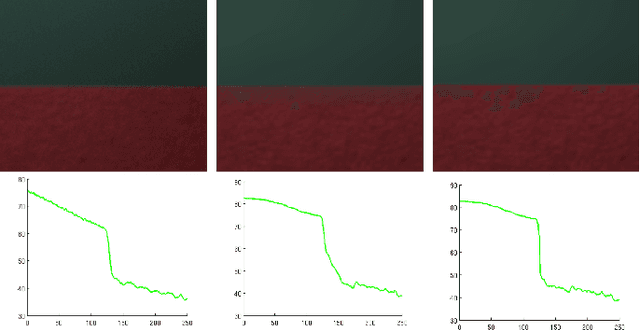
An image captured with a wide-aperture camera exhibits a finite depth-of-field, with focused and defocused pixels. A compact and robust representation of focus and defocus helps analyze and manipulate such images. In this work, we study the fine characteristics of images with a shallow depth-of-field in the context of focal stacks. We present a composite measure for focus that is a combination of existing measures. We identify in-focus pixels, dual-focus pixels, pixels that exhibit bokeh and spatially-varying blur kernels between focal slices. We use these to build a novel representation that facilitates easy manipulation of focal stacks. We present a comprehensive algorithm for post-capture refocusing in a geometrically correct manner. Our approach can refocus the scene at high fidelity while preserving fine aspects of focus and defocus blur.
PeelNet: Textured 3D reconstruction of human body using single view RGB image
Feb 16, 2020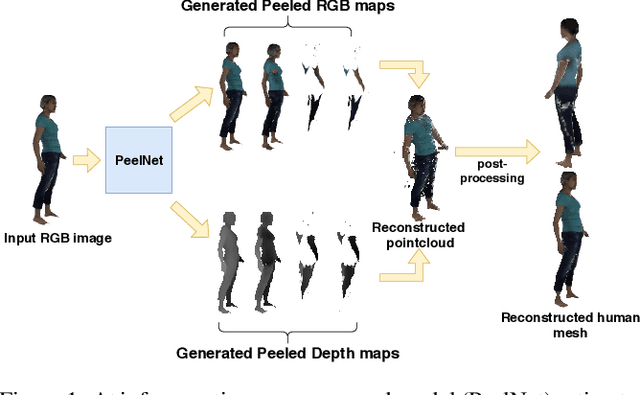


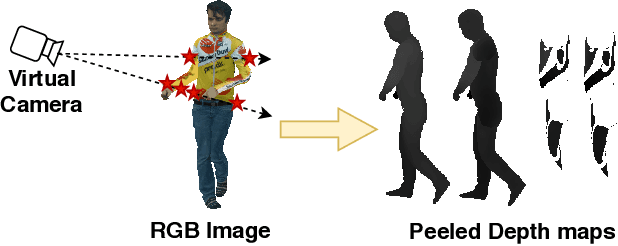
Reconstructing human shape and pose from a single image is a challenging problem due to issues like severe self-occlusions, clothing variations, and changes in lighting to name a few. Many applications in the entertainment industry, e-commerce, health-care (physiotherapy), and mobile-based AR/VR platforms can benefit from recovering the 3D human shape, pose, and texture. In this paper, we present PeelNet, an end-to-end generative adversarial framework to tackle the problem of textured 3D reconstruction of the human body from a single RGB image. Motivated by ray tracing for generating realistic images of a 3D scene, we tackle this problem by representing the human body as a set of peeled depth and RGB maps which are obtained by extending rays beyond the first intersection with the 3D object. This formulation allows us to handle self-occlusions efficiently. Current parametric model-based approaches fail to model loose clothing and surface-level details and are proposed for the underlying naked human body. Majority of non-parametric approaches are either computationally expensive or provide unsatisfactory results. We present a simple non-parametric solution where the peeled maps are generated from a single RGB image as input. Our proposed peeled depth maps are back-projected to 3D volume to obtain a complete 3D shape. The corresponding RGB maps provide vertex-level texture details. We compare our method against current state-of-the-art methods in 3D reconstruction and demonstrate the effectiveness of our method on BUFF and MonoPerfCap datasets.
Semantic Hierarchical Priors for Intrinsic Image Decomposition
Feb 11, 2019



Intrinsic Image Decomposition (IID) is a challenging and interesting computer vision problem with various applications in several fields. We present novel semantic priors and an integrated approach for single image IID that involves analyzing image at three hierarchical context levels. Local context priors capture scene properties at each pixel within a small neighbourhood. Mid-level context priors encode object level semantics. Global context priors establish correspondences at the scene level. Our semantic priors are designed on both fixed and flexible regions, using selective search method and Convolutional Neural Network features. Our IID method is an iterative multistage optimization scheme and consists of two complementary formulations: $L_2$ smoothing for shading and $L_1$ sparsity for reflectance. Experiments and analysis of our method indicate the utility of our semantic priors and structured hierarchical analysis in an IID framework. We compare our method with other contemporary IID solutions and show results with lesser artifacts. Finally, we highlight that proper choice and encoding of prior knowledge can produce competitive results even when compared to end-to-end deep learning IID methods, signifying the importance of such priors. We believe that the insights and techniques presented in this paper would be useful in the future IID research.