 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGETAvatar: Generative Textured Meshes for Animatable Human Avatars
Oct 04, 2023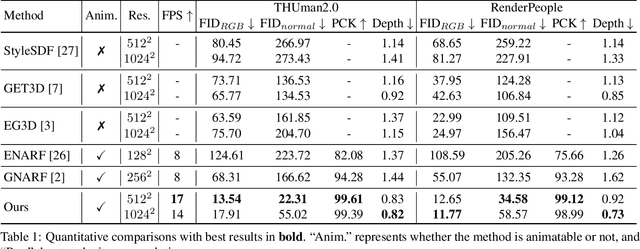
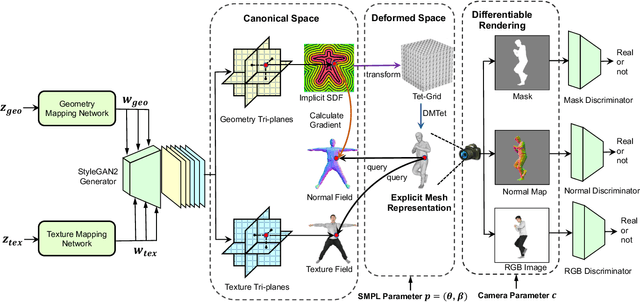
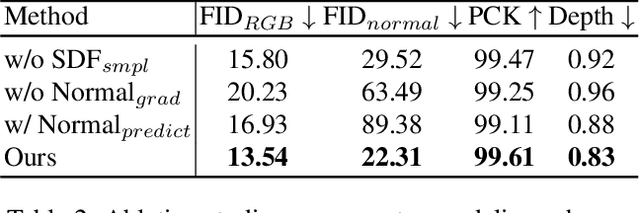

We study the problem of 3D-aware full-body human generation, aiming at creating animatable human avatars with high-quality textures and geometries. Generally, two challenges remain in this field: i) existing methods struggle to generate geometries with rich realistic details such as the wrinkles of garments; ii) they typically utilize volumetric radiance fields and neural renderers in the synthesis process, making high-resolution rendering non-trivial. To overcome these problems, we propose GETAvatar, a Generative model that directly generates Explicit Textured 3D meshes for animatable human Avatar, with photo-realistic appearance and fine geometric details. Specifically, we first design an articulated 3D human representation with explicit surface modeling, and enrich the generated humans with realistic surface details by learning from the 2D normal maps of 3D scan data. Second, with the explicit mesh representation, we can use a rasterization-based renderer to perform surface rendering, allowing us to achieve high-resolution image generation efficiently. Extensive experiments demonstrate that GETAvatar achieves state-of-the-art performance on 3D-aware human generation both in appearance and geometry quality. Notably, GETAvatar can generate images at 512x512 resolution with 17FPS and 1024x1024 resolution with 14FPS, improving upon previous methods by 2x. Our code and models will be available.
SHARP: Shape-Aware Reconstruction of People In Loose Clothing
Jun 17, 2021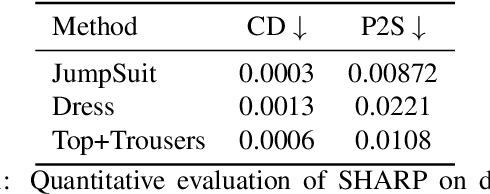
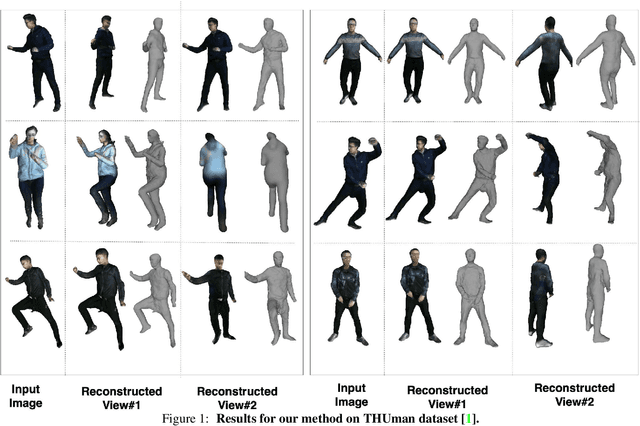
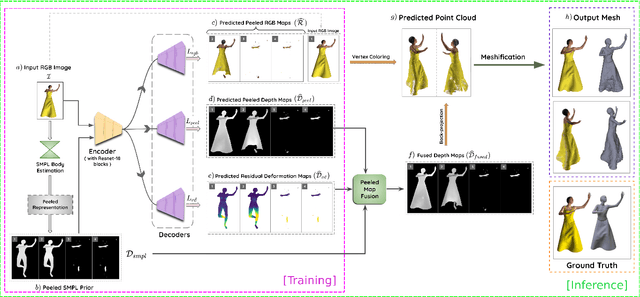
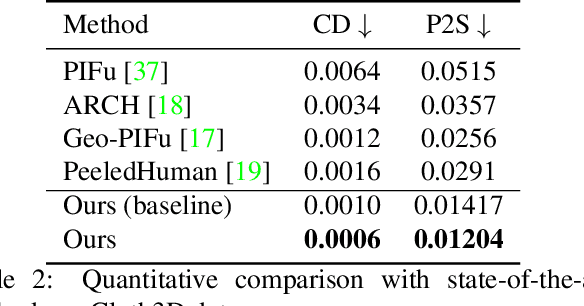
3D human body reconstruction from monocular images is an interesting and ill-posed problem in computer vision with wider applications in multiple domains. In this paper, we propose SHARP, a novel end-to-end trainable network that accurately recovers the detailed geometry and appearance of 3D people in loose clothing from a monocular image. We propose a sparse and efficient fusion of a parametric body prior with a non-parametric peeled depth map representation of clothed models. The parametric body prior constraints our model in two ways: first, the network retains geometrically consistent body parts that are not occluded by clothing, and second, it provides a body shape context that improves prediction of the peeled depth maps. This enables SHARP to recover fine-grained 3D geometrical details with just L1 losses on the 2D maps, given an input image. We evaluate SHARP on publicly available Cloth3D and THuman datasets and report superior performance to state-of-the-art approaches.
PeelNet: Textured 3D reconstruction of human body using single view RGB image
Feb 16, 2020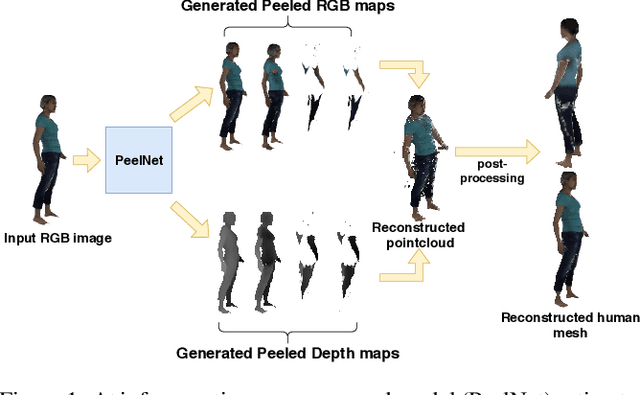


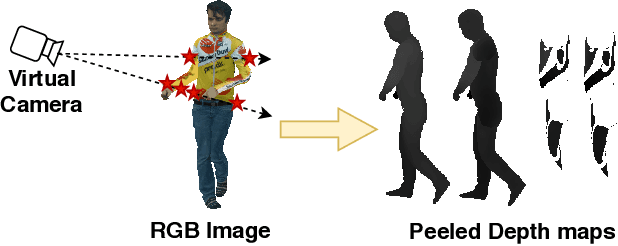
Reconstructing human shape and pose from a single image is a challenging problem due to issues like severe self-occlusions, clothing variations, and changes in lighting to name a few. Many applications in the entertainment industry, e-commerce, health-care (physiotherapy), and mobile-based AR/VR platforms can benefit from recovering the 3D human shape, pose, and texture. In this paper, we present PeelNet, an end-to-end generative adversarial framework to tackle the problem of textured 3D reconstruction of the human body from a single RGB image. Motivated by ray tracing for generating realistic images of a 3D scene, we tackle this problem by representing the human body as a set of peeled depth and RGB maps which are obtained by extending rays beyond the first intersection with the 3D object. This formulation allows us to handle self-occlusions efficiently. Current parametric model-based approaches fail to model loose clothing and surface-level details and are proposed for the underlying naked human body. Majority of non-parametric approaches are either computationally expensive or provide unsatisfactory results. We present a simple non-parametric solution where the peeled maps are generated from a single RGB image as input. Our proposed peeled depth maps are back-projected to 3D volume to obtain a complete 3D shape. The corresponding RGB maps provide vertex-level texture details. We compare our method against current state-of-the-art methods in 3D reconstruction and demonstrate the effectiveness of our method on BUFF and MonoPerfCap datasets.