 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMPL Normal Map Is All You Need for Single-view Textured Human Reconstruction
Jun 15, 2025Single-view textured human reconstruction aims to reconstruct a clothed 3D digital human by inputting a monocular 2D image. Existing approaches include feed-forward methods, limited by scarce 3D human data, and diffusion-based methods, prone to erroneous 2D hallucinations. To address these issues, we propose a novel SMPL normal map Equipped 3D Human Reconstruction (SEHR) framework, integrating a pretrained large 3D reconstruction model with human geometry prior. SEHR performs single-view human reconstruction without using a preset diffusion model in one forward propagation. Concretely, SEHR consists of two key components: SMPL Normal Map Guidance (SNMG) and SMPL Normal Map Constraint (SNMC). SNMG incorporates SMPL normal maps into an auxiliary network to provide improved body shape guidance. SNMC enhances invisible body parts by constraining the model to predict an extra SMPL normal Gaussians. Extensive experiments on two benchmark datasets demonstrate that SEHR outperforms existing state-of-the-art methods.
ProbDiffFlow: An Efficient Learning-Free Framework for Probabilistic Single-Image Optical Flow Estimation
Mar 16, 2025This paper studies optical flow estimation, a critical task in motion analysis with applications in autonomous navigation, action recognition, and film production. Traditional optical flow methods require consecutive frames, which are often unavailable due to limitations in data acquisition or real-world scene disruptions. Thus, single-frame optical flow estimation is emerging in the literature. However, existing single-frame approaches suffer from two major limitations: (1) they rely on labeled training data, making them task-specific, and (2) they produce deterministic predictions, failing to capture motion uncertainty. To overcome these challenges, we propose ProbDiffFlow, a training-free framework that estimates optical flow distributions from a single image. Instead of directly predicting motion, ProbDiffFlow follows an estimation-by-synthesis paradigm: it first generates diverse plausible future frames using a diffusion-based model, then estimates motion from these synthesized samples using a pre-trained optical flow model, and finally aggregates the results into a probabilistic flow distribution. This design eliminates the need for task-specific training while capturing multiple plausible motions. Experiments on both synthetic and real-world datasets demonstrate that ProbDiffFlow achieves superior accuracy, diversity, and efficiency, outperforming existing single-image and two-frame baselines.
AvatarStudio: High-fidelity and Animatable 3D Avatar Creation from Text
Nov 29, 2023



We study the problem of creating high-fidelity and animatable 3D avatars from only textual descriptions. Existing text-to-avatar methods are either limited to static avatars which cannot be animated or struggle to generate animatable avatars with promising quality and precise pose control. To address these limitations, we propose AvatarStudio, a coarse-to-fine generative model that generates explicit textured 3D meshes for animatable human avatars. Specifically, AvatarStudio begins with a low-resolution NeRF-based representation for coarse generation, followed by incorporating SMPL-guided articulation into the explicit mesh representation to support avatar animation and high resolution rendering. To ensure view consistency and pose controllability of the resulting avatars, we introduce a 2D diffusion model conditioned on DensePose for Score Distillation Sampling supervision. By effectively leveraging the synergy between the articulated mesh representation and the DensePose-conditional diffusion model, AvatarStudio can create high-quality avatars from text that are ready for animation, significantly outperforming previous methods. Moreover, it is competent for many applications, e.g., multimodal avatar animations and style-guided avatar creation. For more results, please refer to our project page: http://jeff95.me/projects/avatarstudio.html
GETAvatar: Generative Textured Meshes for Animatable Human Avatars
Oct 04, 2023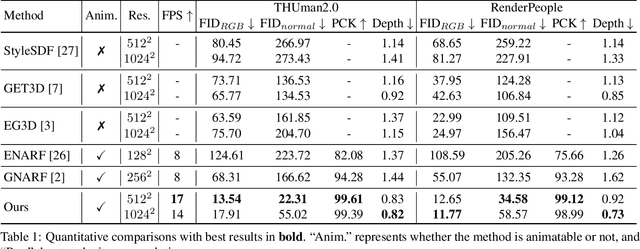
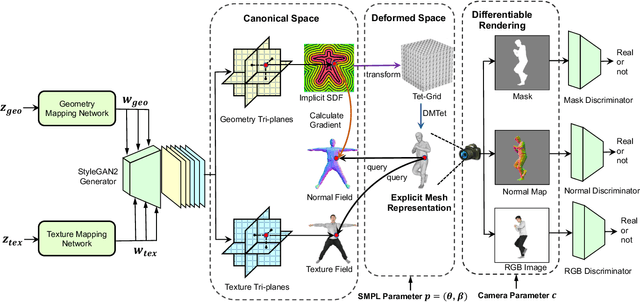
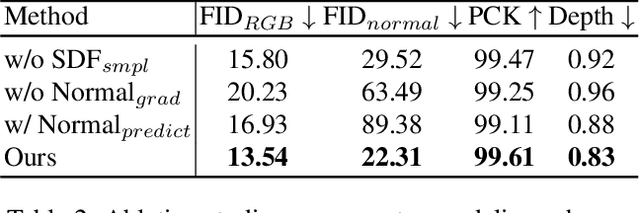

We study the problem of 3D-aware full-body human generation, aiming at creating animatable human avatars with high-quality textures and geometries. Generally, two challenges remain in this field: i) existing methods struggle to generate geometries with rich realistic details such as the wrinkles of garments; ii) they typically utilize volumetric radiance fields and neural renderers in the synthesis process, making high-resolution rendering non-trivial. To overcome these problems, we propose GETAvatar, a Generative model that directly generates Explicit Textured 3D meshes for animatable human Avatar, with photo-realistic appearance and fine geometric details. Specifically, we first design an articulated 3D human representation with explicit surface modeling, and enrich the generated humans with realistic surface details by learning from the 2D normal maps of 3D scan data. Second, with the explicit mesh representation, we can use a rasterization-based renderer to perform surface rendering, allowing us to achieve high-resolution image generation efficiently. Extensive experiments demonstrate that GETAvatar achieves state-of-the-art performance on 3D-aware human generation both in appearance and geometry quality. Notably, GETAvatar can generate images at 512x512 resolution with 17FPS and 1024x1024 resolution with 14FPS, improving upon previous methods by 2x. Our code and models will be available.
Multi-View Consistent Generative Adversarial Networks for 3D-aware Image Synthesis
Apr 13, 2022



3D-aware image synthesis aims to generate images of objects from multiple views by learning a 3D representation. However, one key challenge remains: existing approaches lack geometry constraints, hence usually fail to generate multi-view consistent images. To address this challenge, we propose Multi-View Consistent Generative Adversarial Networks (MVCGAN) for high-quality 3D-aware image synthesis with geometry constraints. By leveraging the underlying 3D geometry information of generated images, i.e., depth and camera transformation matrix, we explicitly establish stereo correspondence between views to perform multi-view joint optimization. In particular, we enforce the photometric consistency between pairs of views and integrate a stereo mixup mechanism into the training process, encouraging the model to reason about the correct 3D shape. Besides, we design a two-stage training strategy with feature-level multi-view joint optimization to improve the image quality. Extensive experiments on three datasets demonstrate that MVCGAN achieves the state-of-the-art performance for 3D-aware image synthesis.
Understanding Image Retrieval Re-Ranking: A Graph Neural Network Perspective
Dec 29, 2020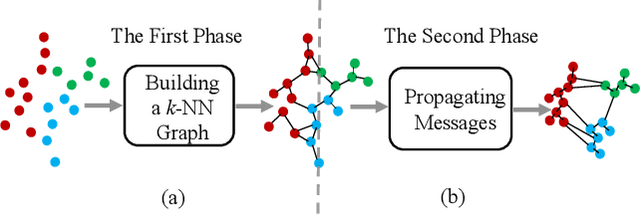

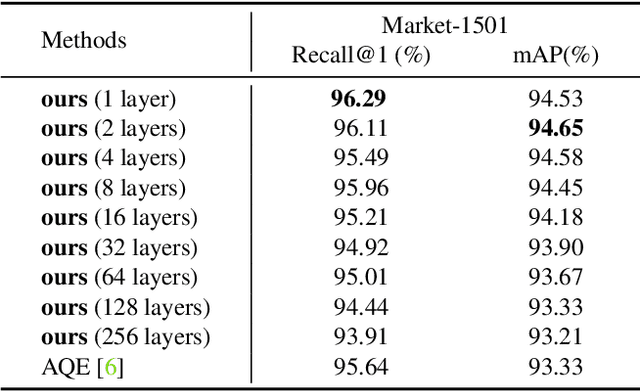
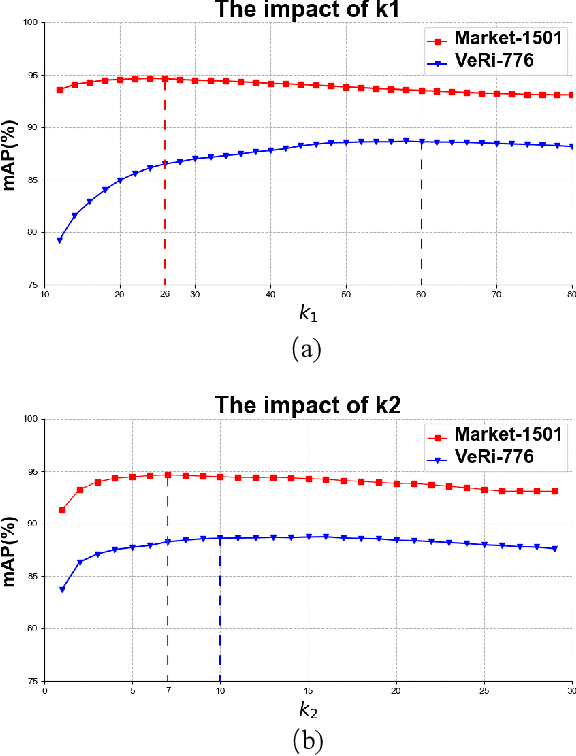
The re-ranking approach leverages high-confidence retrieved samples to refine retrieval results, which have been widely adopted as a post-processing tool for image retrieval tasks. However, we notice one main flaw of re-ranking, i.e., high computational complexity, which leads to an unaffordable time cost for real-world applications. In this paper, we revisit re-ranking and demonstrate that re-ranking can be reformulated as a high-parallelism Graph Neural Network (GNN) function. In particular, we divide the conventional re-ranking process into two phases, i.e., retrieving high-quality gallery samples and updating features. We argue that the first phase equals building the k-nearest neighbor graph, while the second phase can be viewed as spreading the message within the graph. In practice, GNN only needs to concern vertices with the connected edges. Since the graph is sparse, we can efficiently update the vertex features. On the Market-1501 dataset, we accelerate the re-ranking processing from 89.2s to 9.4ms with one K40m GPU, facilitating the real-time post-processing. Similarly, we observe that our method achieves comparable or even better retrieval results on the other four image retrieval benchmarks, i.e., VeRi-776, Oxford-5k, Paris-6k and University-1652, with limited time cost. Our code is publicly available.