 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErased, But Not Forgotten: Erased Rectified Flow Transformers Still Remain Unsafe Under Concept Attack
Oct 01, 2025Recent advances in text-to-image (T2I) diffusion models have enabled impressive generative capabilities, but they also raise significant safety concerns due to the potential to produce harmful or undesirable content. While concept erasure has been explored as a mitigation strategy, most existing approaches and corresponding attack evaluations are tailored to Stable Diffusion (SD) and exhibit limited effectiveness when transferred to next-generation rectified flow transformers such as Flux. In this work, we present ReFlux, the first concept attack method specifically designed to assess the robustness of concept erasure in the latest rectified flow-based T2I framework. Our approach is motivated by the observation that existing concept erasure techniques, when applied to Flux, fundamentally rely on a phenomenon known as attention localization. Building on this insight, we propose a simple yet effective attack strategy that specifically targets this property. At its core, a reverse-attention optimization strategy is introduced to effectively reactivate suppressed signals while stabilizing attention. This is further reinforced by a velocity-guided dynamic that enhances the robustness of concept reactivation by steering the flow matching process, and a consistency-preserving objective that maintains the global layout and preserves unrelated content. Extensive experiments consistently demonstrate the effectiveness and efficiency of the proposed attack method, establishing a reliable benchmark for evaluating the robustness of concept erasure strategies in rectified flow transformers.
Undress to Redress: A Training-Free Framework for Virtual Try-On
Aug 11, 2025Virtual try-on (VTON) is a crucial task for enhancing user experience in online shopping by generating realistic garment previews on personal photos. Although existing methods have achieved impressive results, they struggle with long-sleeve-to-short-sleeve conversions-a common and practical scenario-often producing unrealistic outputs when exposed skin is underrepresented in the original image. We argue that this challenge arises from the ''majority'' completion rule in current VTON models, which leads to inaccurate skin restoration in such cases. To address this, we propose UR-VTON (Undress-Redress Virtual Try-ON), a novel, training-free framework that can be seamlessly integrated with any existing VTON method. UR-VTON introduces an ''undress-to-redress'' mechanism: it first reveals the user's torso by virtually ''undressing,'' then applies the target short-sleeve garment, effectively decomposing the conversion into two more manageable steps. Additionally, we incorporate Dynamic Classifier-Free Guidance scheduling to balance diversity and image quality during DDPM sampling, and employ Structural Refiner to enhance detail fidelity using high-frequency cues. Finally, we present LS-TON, a new benchmark for long-sleeve-to-short-sleeve try-on. Extensive experiments demonstrate that UR-VTON outperforms state-of-the-art methods in both detail preservation and image quality. Code will be released upon acceptance.
MES-RAG: Bringing Multi-modal, Entity-Storage, and Secure Enhancements to RAG
Mar 17, 2025



Retrieval-Augmented Generation (RAG) improves Large Language Models (LLMs) by using external knowledge, but it struggles with precise entity information retrieval. In this paper, we proposed MES-RAG framework, which enhances entity-specific query handling and provides accurate, secure, and consistent responses. MES-RAG introduces proactive security measures that ensure system integrity by applying protections prior to data access. Additionally, the system supports real-time multi-modal outputs, including text, images, audio, and video, seamlessly integrating into existing RAG architectures. Experimental results demonstrate that MES-RAG significantly improves both accuracy and recall, highlighting its effectiveness in advancing the security and utility of question-answering, increasing accuracy to 0.83 (+0.25) on targeted task. Our code and data are available at https://github.com/wpydcr/MES-RAG.
EraseAnything: Enabling Concept Erasure in Rectified Flow Transformers
Dec 29, 2024Removing unwanted concepts from large-scale text-to-image (T2I) diffusion models while maintaining their overall generative quality remains an open challenge. This difficulty is especially pronounced in emerging paradigms, such as Stable Diffusion (SD) v3 and Flux, which incorporate flow matching and transformer-based architectures. These advancements limit the transferability of existing concept-erasure techniques that were originally designed for the previous T2I paradigm (\textit{e.g.}, SD v1.4). In this work, we introduce \logopic \textbf{EraseAnything}, the first method specifically developed to address concept erasure within the latest flow-based T2I framework. We formulate concept erasure as a bi-level optimization problem, employing LoRA-based parameter tuning and an attention map regularizer to selectively suppress undesirable activations. Furthermore, we propose a self-contrastive learning strategy to ensure that removing unwanted concepts does not inadvertently harm performance on unrelated ones. Experimental results demonstrate that EraseAnything successfully fills the research gap left by earlier methods in this new T2I paradigm, achieving state-of-the-art performance across a wide range of concept erasure tasks.
OutfitAnyone: Ultra-high Quality Virtual Try-On for Any Clothing and Any Person
Jul 23, 2024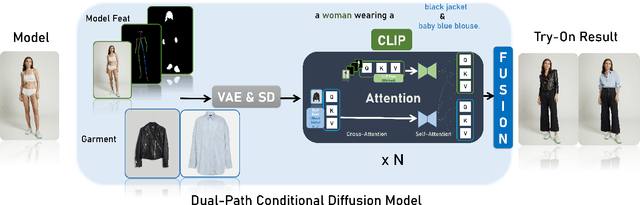
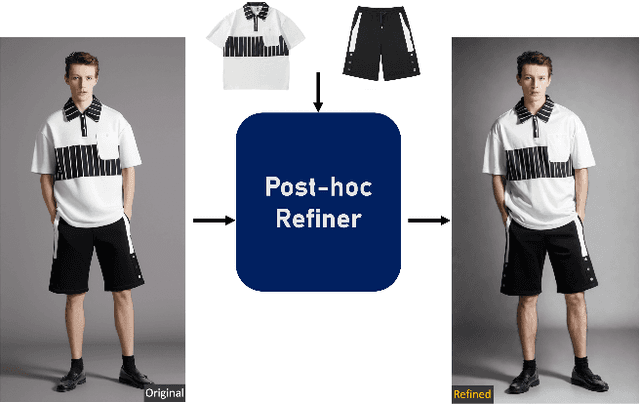


Virtual Try-On (VTON) has become a transformative technology, empowering users to experiment with fashion without ever having to physically try on clothing. However, existing methods often struggle with generating high-fidelity and detail-consistent results. While diffusion models, such as Stable Diffusion series, have shown their capability in creating high-quality and photorealistic images, they encounter formidable challenges in conditional generation scenarios like VTON. Specifically, these models struggle to maintain a balance between control and consistency when generating images for virtual clothing trials. OutfitAnyone addresses these limitations by leveraging a two-stream conditional diffusion model, enabling it to adeptly handle garment deformation for more lifelike results. It distinguishes itself with scalability-modulating factors such as pose, body shape and broad applicability, extending from anime to in-the-wild images. OutfitAnyone's performance in diverse scenarios underscores its utility and readiness for real-world deployment. For more details and animated results, please see \url{https://humanaigc.github.io/outfit-anyone/}.
MaTe3D: Mask-guided Text-based 3D-aware Portrait Editing
Dec 12, 2023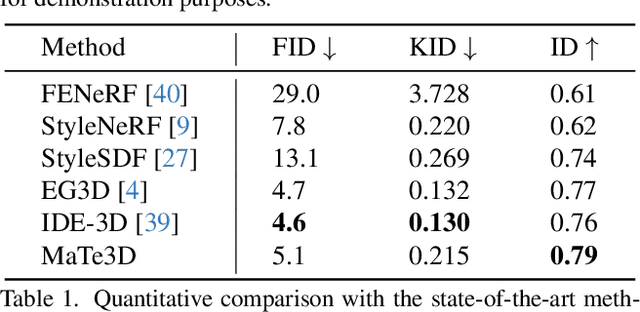
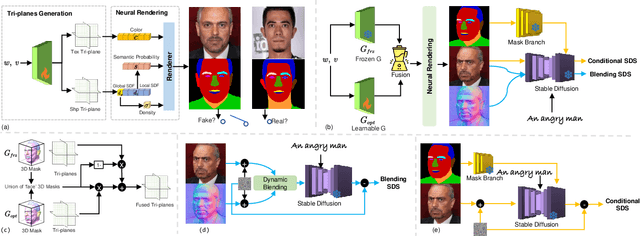
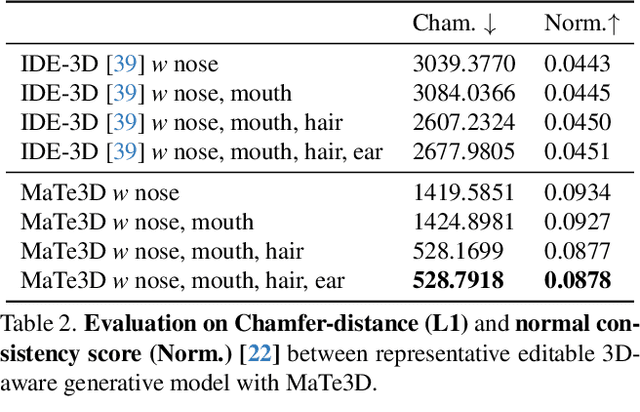

Recently, 3D-aware face editing has witnessed remarkable progress. Although current approaches successfully perform mask-guided or text-based editing, these properties have not been combined into a single method. To address this limitation, we propose \textbf{MaTe3D}: mask-guided text-based 3D-aware portrait editing. First, we propose a new SDF-based 3D generator. To better perform masked-based editing (mainly happening in local areas), we propose SDF and density consistency losses, aiming to effectively model both the global and local representations jointly. Second, we introduce an inference-optimized method. We introduce two techniques based on the SDS (Score Distillation Sampling), including a blending SDS and a conditional SDS. The former aims to overcome the mismatch problem between geometry and appearance, ultimately harming fidelity. The conditional SDS contributes to further producing satisfactory and stable results. Additionally, we create CatMask-HQ dataset, a large-scale high-resolution cat face annotations. We perform experiments on both the FFHQ and CatMask-HQ datasets to demonstrate the effectiveness of the proposed method. Our method generates faithfully a edited 3D-aware face image given a modified mask and a text prompt. Our code and models will be publicly released.
VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
Dec 07, 2023Audio-driven talking head generation has drawn much attention in recent years, and many efforts have been made in lip-sync, expressive facial expressions, natural head pose generation, and high video quality. However, no model has yet led or tied on all these metrics due to the one-to-many mapping between audio and motion. In this paper, we propose VividTalk, a two-stage generic framework that supports generating high-visual quality talking head videos with all the above properties. Specifically, in the first stage, we map the audio to mesh by learning two motions, including non-rigid expression motion and rigid head motion. For expression motion, both blendshape and vertex are adopted as the intermediate representation to maximize the representation ability of the model. For natural head motion, a novel learnable head pose codebook with a two-phase training mechanism is proposed. In the second stage, we proposed a dual branch motion-vae and a generator to transform the meshes into dense motion and synthesize high-quality video frame-by-frame. Extensive experiments show that the proposed VividTalk can generate high-visual quality talking head videos with lip-sync and realistic enhanced by a large margin, and outperforms previous state-of-the-art works in objective and subjective comparisons.
HAVE-FUN: Human Avatar Reconstruction from Few-Shot Unconstrained Images
Nov 27, 2023As for human avatar reconstruction, contemporary techniques commonly necessitate the acquisition of costly data and struggle to achieve satisfactory results from a small number of casual images. In this paper, we investigate this task from a few-shot unconstrained photo album. The reconstruction of human avatars from such data sources is challenging because of limited data amount and dynamic articulated poses. For handling dynamic data, we integrate a skinning mechanism with deep marching tetrahedra (DMTet) to form a drivable tetrahedral representation, which drives arbitrary mesh topologies generated by the DMTet for the adaptation of unconstrained images. To effectively mine instructive information from few-shot data, we devise a two-phase optimization method with few-shot reference and few-shot guidance. The former focuses on aligning avatar identity with reference images, while the latter aims to generate plausible appearances for unseen regions. Overall, our framework, called HaveFun, can undertake avatar reconstruction, rendering, and animation. Extensive experiments on our developed benchmarks demonstrate that HaveFun exhibits substantially superior performance in reconstructing the human body and hand. Project website: https://seanchenxy.github.io/HaveFunWeb/.
Cloth2Tex: A Customized Cloth Texture Generation Pipeline for 3D Virtual Try-On
Aug 08, 2023Fabricating and designing 3D garments has become extremely demanding with the increasing need for synthesizing realistic dressed persons for a variety of applications, e.g. 3D virtual try-on, digitalization of 2D clothes into 3D apparel, and cloth animation. It thus necessitates a simple and straightforward pipeline to obtain high-quality texture from simple input, such as 2D reference images. Since traditional warping-based texture generation methods require a significant number of control points to be manually selected for each type of garment, which can be a time-consuming and tedious process. We propose a novel method, called Cloth2Tex, which eliminates the human burden in this process. Cloth2Tex is a self-supervised method that generates texture maps with reasonable layout and structural consistency. Another key feature of Cloth2Tex is that it can be used to support high-fidelity texture inpainting. This is done by combining Cloth2Tex with a prevailing latent diffusion model. We evaluate our approach both qualitatively and quantitatively and demonstrate that Cloth2Tex can generate high-quality texture maps and achieve the best visual effects in comparison to other methods. Project page: tomguluson92.github.io/projects/cloth2tex/
DART: Articulated Hand Model with Diverse Accessories and Rich Textures
Oct 14, 2022
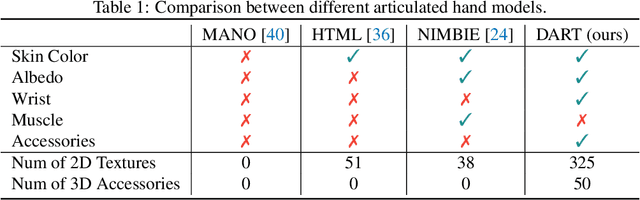


Hand, the bearer of human productivity and intelligence, is receiving much attention due to the recent fever of digital twins. Among different hand morphable models, MANO has been widely used in vision and graphics community. However, MANO disregards textures and accessories, which largely limits its power to synthesize photorealistic hand data. In this paper, we extend MANO with Diverse Accessories and Rich Textures, namely DART. DART is composed of 50 daily 3D accessories which varies in appearance and shape, and 325 hand-crafted 2D texture maps covers different kinds of blemishes or make-ups. Unity GUI is also provided to generate synthetic hand data with user-defined settings, e.g., pose, camera, background, lighting, textures, and accessories. Finally, we release DARTset, which contains large-scale (800K), high-fidelity synthetic hand images, paired with perfect-aligned 3D labels. Experiments demonstrate its superiority in diversity. As a complement to existing hand datasets, DARTset boosts the generalization in both hand pose estimation and mesh recovery tasks. Raw ingredients (textures, accessories), Unity GUI, source code and DARTset are publicly available at dart2022.github.io