 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAR: Edge-Aware Reconstruction of 3-D vertebrae structures from bi-planar X-ray images
Jul 30, 2024X-ray images ease the diagnosis and treatment process due to their rapid imaging speed and high resolution. However, due to the projection process of X-ray imaging, much spatial information has been lost. To accurately provide efficient spinal morphological and structural information, reconstructing the 3-D structures of the spine from the 2-D X-ray images is essential. It is challenging for current reconstruction methods to preserve the edge information and local shapes of the asymmetrical vertebrae structures. In this study, we propose a new Edge-Aware Reconstruction network (EAR) to focus on the performance improvement of the edge information and vertebrae shapes. In our network, by using the auto-encoder architecture as the backbone, the edge attention module and frequency enhancement module are proposed to strengthen the perception of the edge reconstruction. Meanwhile, we also combine four loss terms, including reconstruction loss, edge loss, frequency loss and projection loss. The proposed method is evaluated using three publicly accessible datasets and compared with four state-of-the-art models. The proposed method is superior to other methods and achieves 25.32%, 15.32%, 86.44%, 80.13%, 23.7612 and 0.3014 with regard to MSE, MAE, Dice, SSIM, PSNR and frequency distance. Due to the end-to-end and accurate reconstruction process, EAR can provide sufficient 3-D spatial information and precise preoperative surgical planning guidance.
Multi-view X-ray Image Synthesis with Multiple Domain Disentanglement from CT Scans
Apr 18, 2024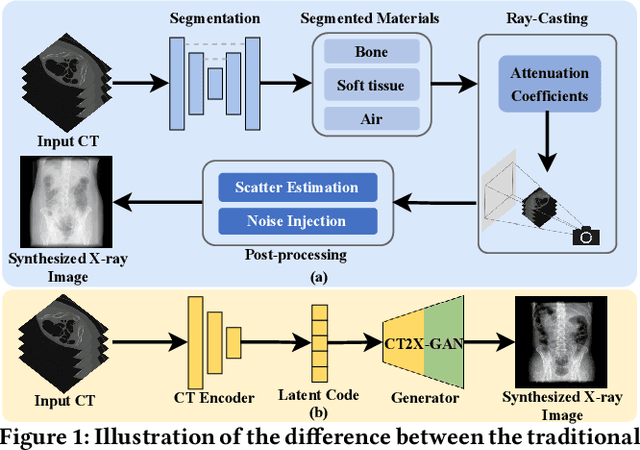

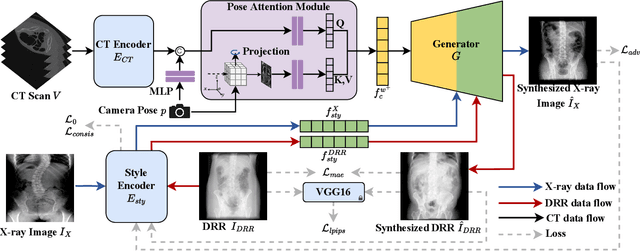
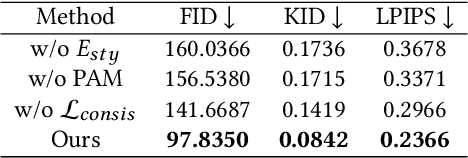
X-ray images play a vital role in the intraoperative processes due to their high resolution and fast imaging speed and greatly promote the subsequent segmentation, registration and reconstruction. However, over-dosed X-rays superimpose potential risks to human health to some extent. Data-driven algorithms from volume scans to X-ray images are restricted by the scarcity of paired X-ray and volume data. Existing methods are mainly realized by modelling the whole X-ray imaging procedure. In this study, we propose a learning-based approach termed CT2X-GAN to synthesize the X-ray images in an end-to-end manner using the content and style disentanglement from three different image domains. Our method decouples the anatomical structure information from CT scans and style information from unpaired real X-ray images/ digital reconstructed radiography (DRR) images via a series of decoupling encoders. Additionally, we introduce a novel consistency regularization term to improve the stylistic resemblance between synthesized X-ray images and real X-ray images. Meanwhile, we also impose a supervised process by computing the similarity of computed real DRR and synthesized DRR images. We further develop a pose attention module to fully strengthen the comprehensive information in the decoupled content code from CT scans, facilitating high-quality multi-view image synthesis in the lower 2D space. Extensive experiments were conducted on the publicly available CTSpine1K dataset and achieved 97.8350, 0.0842 and 3.0938 in terms of FID, KID and defined user-scored X-ray similarity, respectively. In comparison with 3D-aware methods ($\pi$-GAN, EG3D), CT2X-GAN is superior in improving the synthesis quality and realistic to the real X-ray images.
MaTe3D: Mask-guided Text-based 3D-aware Portrait Editing
Dec 12, 2023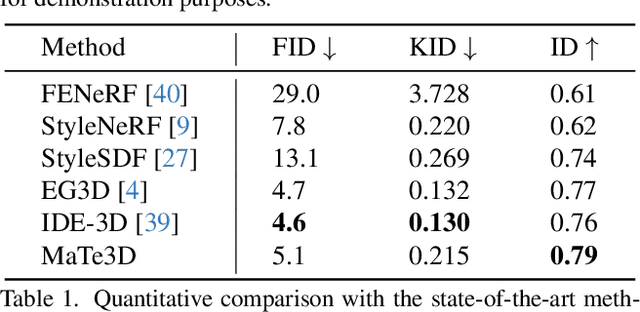
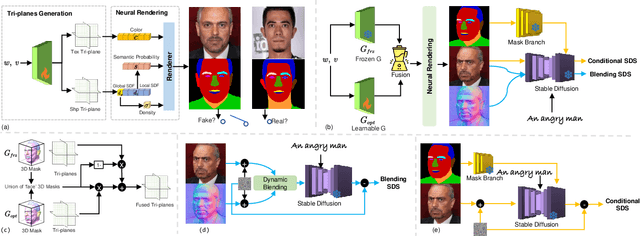
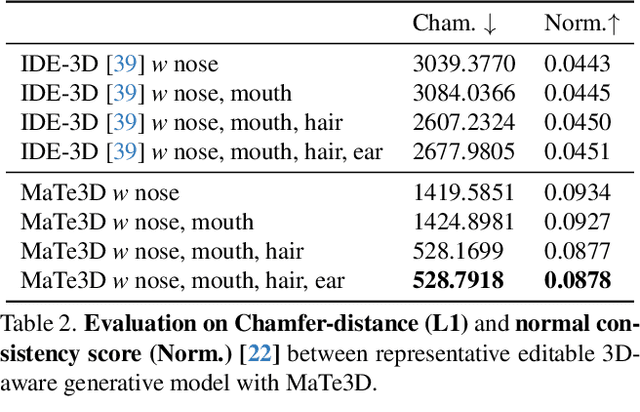

Recently, 3D-aware face editing has witnessed remarkable progress. Although current approaches successfully perform mask-guided or text-based editing, these properties have not been combined into a single method. To address this limitation, we propose \textbf{MaTe3D}: mask-guided text-based 3D-aware portrait editing. First, we propose a new SDF-based 3D generator. To better perform masked-based editing (mainly happening in local areas), we propose SDF and density consistency losses, aiming to effectively model both the global and local representations jointly. Second, we introduce an inference-optimized method. We introduce two techniques based on the SDS (Score Distillation Sampling), including a blending SDS and a conditional SDS. The former aims to overcome the mismatch problem between geometry and appearance, ultimately harming fidelity. The conditional SDS contributes to further producing satisfactory and stable results. Additionally, we create CatMask-HQ dataset, a large-scale high-resolution cat face annotations. We perform experiments on both the FFHQ and CatMask-HQ datasets to demonstrate the effectiveness of the proposed method. Our method generates faithfully a edited 3D-aware face image given a modified mask and a text prompt. Our code and models will be publicly released.
VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
Dec 07, 2023Audio-driven talking head generation has drawn much attention in recent years, and many efforts have been made in lip-sync, expressive facial expressions, natural head pose generation, and high video quality. However, no model has yet led or tied on all these metrics due to the one-to-many mapping between audio and motion. In this paper, we propose VividTalk, a two-stage generic framework that supports generating high-visual quality talking head videos with all the above properties. Specifically, in the first stage, we map the audio to mesh by learning two motions, including non-rigid expression motion and rigid head motion. For expression motion, both blendshape and vertex are adopted as the intermediate representation to maximize the representation ability of the model. For natural head motion, a novel learnable head pose codebook with a two-phase training mechanism is proposed. In the second stage, we proposed a dual branch motion-vae and a generator to transform the meshes into dense motion and synthesize high-quality video frame-by-frame. Extensive experiments show that the proposed VividTalk can generate high-visual quality talking head videos with lip-sync and realistic enhanced by a large margin, and outperforms previous state-of-the-art works in objective and subjective comparisons.