 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaTe3D: Mask-guided Text-based 3D-aware Portrait Editing
Dec 12, 2023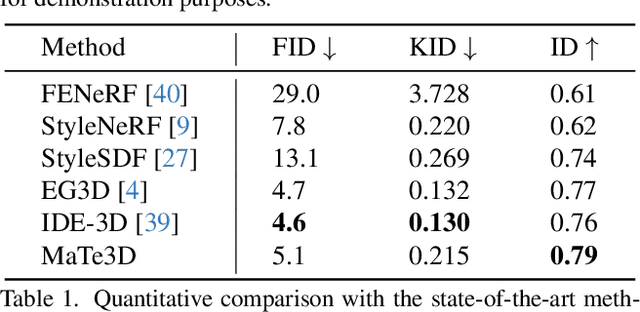
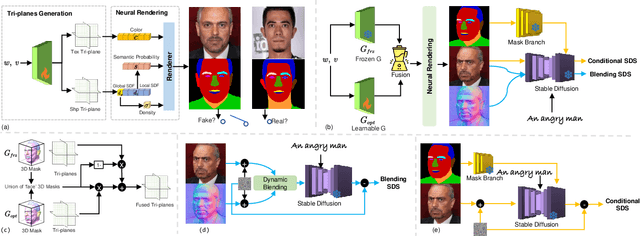
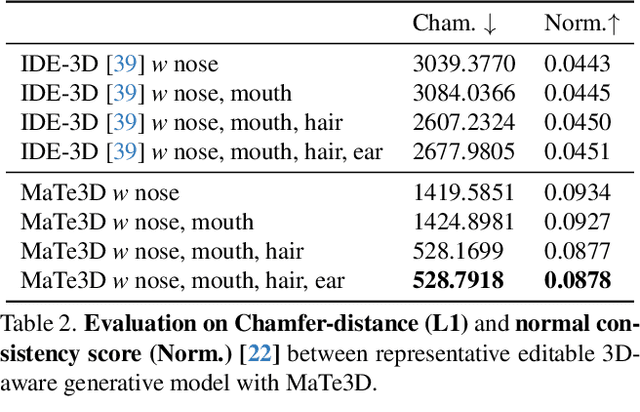

Recently, 3D-aware face editing has witnessed remarkable progress. Although current approaches successfully perform mask-guided or text-based editing, these properties have not been combined into a single method. To address this limitation, we propose \textbf{MaTe3D}: mask-guided text-based 3D-aware portrait editing. First, we propose a new SDF-based 3D generator. To better perform masked-based editing (mainly happening in local areas), we propose SDF and density consistency losses, aiming to effectively model both the global and local representations jointly. Second, we introduce an inference-optimized method. We introduce two techniques based on the SDS (Score Distillation Sampling), including a blending SDS and a conditional SDS. The former aims to overcome the mismatch problem between geometry and appearance, ultimately harming fidelity. The conditional SDS contributes to further producing satisfactory and stable results. Additionally, we create CatMask-HQ dataset, a large-scale high-resolution cat face annotations. We perform experiments on both the FFHQ and CatMask-HQ datasets to demonstrate the effectiveness of the proposed method. Our method generates faithfully a edited 3D-aware face image given a modified mask and a text prompt. Our code and models will be publicly released.
VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
Dec 07, 2023Audio-driven talking head generation has drawn much attention in recent years, and many efforts have been made in lip-sync, expressive facial expressions, natural head pose generation, and high video quality. However, no model has yet led or tied on all these metrics due to the one-to-many mapping between audio and motion. In this paper, we propose VividTalk, a two-stage generic framework that supports generating high-visual quality talking head videos with all the above properties. Specifically, in the first stage, we map the audio to mesh by learning two motions, including non-rigid expression motion and rigid head motion. For expression motion, both blendshape and vertex are adopted as the intermediate representation to maximize the representation ability of the model. For natural head motion, a novel learnable head pose codebook with a two-phase training mechanism is proposed. In the second stage, we proposed a dual branch motion-vae and a generator to transform the meshes into dense motion and synthesize high-quality video frame-by-frame. Extensive experiments show that the proposed VividTalk can generate high-visual quality talking head videos with lip-sync and realistic enhanced by a large margin, and outperforms previous state-of-the-art works in objective and subjective comparisons.
MoFaNeRF: Morphable Facial Neural Radiance Field
Dec 04, 2021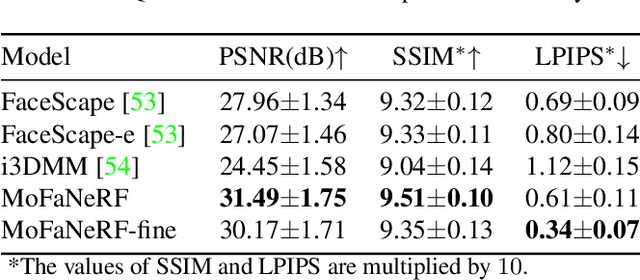
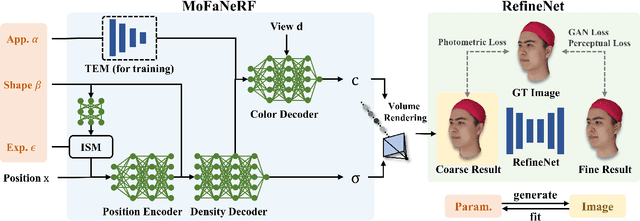


We propose a parametric model that maps free-view images into a vector space of coded facial shape, expression and appearance using a neural radiance field, namely Morphable Facial NeRF. Specifically, MoFaNeRF takes the coded facial shape, expression and appearance along with space coordinate and view direction as input to an MLP, and outputs the radiance of the space point for photo-realistic image synthesis. Compared with conventional 3D morphable models (3DMM), MoFaNeRF shows superiority in directly synthesizing photo-realistic facial details even for eyes, mouths, and beards. Also, continuous face morphing can be easily achieved by interpolating the input shape, expression and appearance codes. By introducing identity-specific modulation and texture encoder, our model synthesizes accurate photometric details and shows strong representation ability. Our model shows strong ability on multiple applications including image-based fitting, random generation, face rigging, face editing, and novel view synthesis. Experiments show that our method achieves higher representation ability than previous parametric models, and achieves competitive performance in several applications. To the best of our knowledge, our work is the first facial parametric model built upon a neural radiance field that can be used in fitting, generation and manipulation. Our code and model are released in https://github.com/zhuhao-nju/mofanerf.