 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaTe3D: Mask-guided Text-based 3D-aware Portrait Editing
Paper and Code
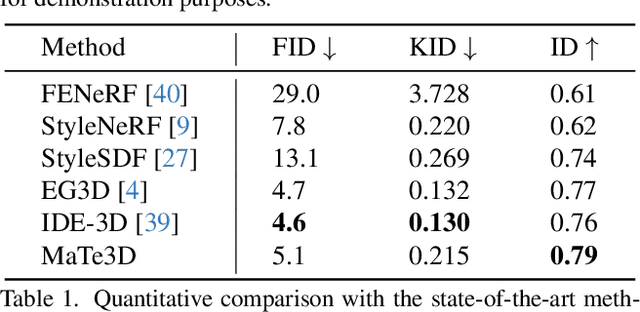
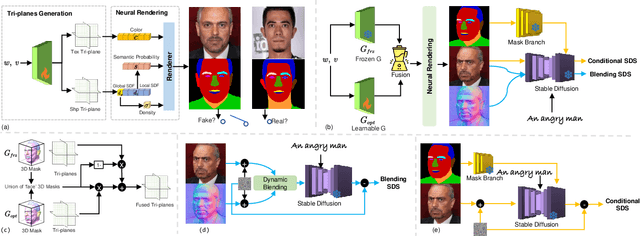
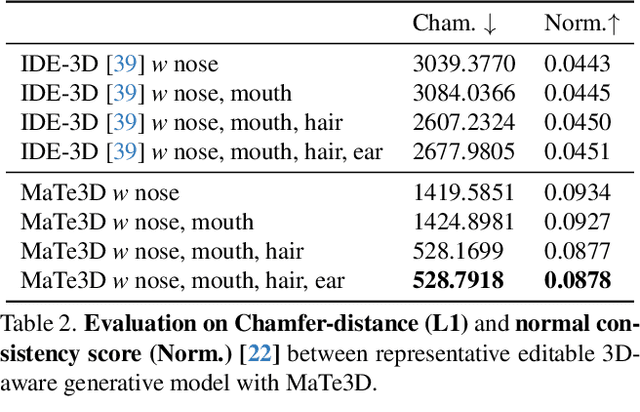

Recently, 3D-aware face editing has witnessed remarkable progress. Although current approaches successfully perform mask-guided or text-based editing, these properties have not been combined into a single method. To address this limitation, we propose \textbf{MaTe3D}: mask-guided text-based 3D-aware portrait editing. First, we propose a new SDF-based 3D generator. To better perform masked-based editing (mainly happening in local areas), we propose SDF and density consistency losses, aiming to effectively model both the global and local representations jointly. Second, we introduce an inference-optimized method. We introduce two techniques based on the SDS (Score Distillation Sampling), including a blending SDS and a conditional SDS. The former aims to overcome the mismatch problem between geometry and appearance, ultimately harming fidelity. The conditional SDS contributes to further producing satisfactory and stable results. Additionally, we create CatMask-HQ dataset, a large-scale high-resolution cat face annotations. We perform experiments on both the FFHQ and CatMask-HQ datasets to demonstrate the effectiveness of the proposed method. Our method generates faithfully a edited 3D-aware face image given a modified mask and a text prompt. Our code and models will be publicly released.