 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic AI as a Cybersecurity Attack Surface: Threats, Exploits, and Defenses in Runtime Supply Chains
Feb 23, 2026Agentic systems built on large language models (LLMs) extend beyond text generation to autonomously retrieve information and invoke tools. This runtime execution model shifts the attack surface from build-time artifacts to inference-time dependencies, exposing agents to manipulation through untrusted data and probabilistic capability resolution. While prior work has focused on model-level vulnerabilities, security risks emerging from cyclic and interdependent runtime behavior remain fragmented. We systematize these risks within a unified runtime framework, categorizing threats into data supply chain attacks (transient context injection and persistent memory poisoning) and tool supply chain attacks (discovery, implementation, and invocation). We further identify the Viral Agent Loop, in which agents act as vectors for self-propagating generative worms without exploiting code-level flaws. Finally, we advocate a Zero-Trust Runtime Architecture that treats context as untrusted control flow and constrains tool execution through cryptographic provenance rather than semantic inference.
EchoDistill: Bidirectional Concept Distillation for One-Step Diffusion Personalization
Oct 23, 2025Recent advances in accelerating text-to-image (T2I) diffusion models have enabled the synthesis of high-fidelity images even in a single step. However, personalizing these models to incorporate novel concepts remains a challenge due to the limited capacity of one-step models to capture new concept distributions effectively. We propose a bidirectional concept distillation framework, EchoDistill, to enable one-step diffusion personalization (1-SDP). Our approach involves an end-to-end training process where a multi-step diffusion model (teacher) and a one-step diffusion model (student) are trained simultaneously. The concept is first distilled from the teacher model to the student, and then echoed back from the student to the teacher. During the EchoDistill, we share the text encoder between the two models to ensure consistent semantic understanding. Following this, the student model is optimized with adversarial losses to align with the real image distribution and with alignment losses to maintain consistency with the teacher's output. Furthermore, we introduce the bidirectional echoing refinement strategy, wherein the student model leverages its faster generation capability to feedback to the teacher model. This bidirectional concept distillation mechanism not only enhances the student ability to personalize novel concepts but also improves the generative quality of the teacher model. Our experiments demonstrate that this collaborative framework significantly outperforms existing personalization methods over the 1-SDP setup, establishing a novel paradigm for rapid and effective personalization in T2I diffusion models.
From Cradle to Cane: A Two-Pass Framework for High-Fidelity Lifespan Face Aging
Jun 26, 2025



Face aging has become a crucial task in computer vision, with applications ranging from entertainment to healthcare. However, existing methods struggle with achieving a realistic and seamless transformation across the entire lifespan, especially when handling large age gaps or extreme head poses. The core challenge lies in balancing age accuracy and identity preservation--what we refer to as the Age-ID trade-off. Most prior methods either prioritize age transformation at the expense of identity consistency or vice versa. In this work, we address this issue by proposing a two-pass face aging framework, named Cradle2Cane, based on few-step text-to-image (T2I) diffusion models. The first pass focuses on solving age accuracy by introducing an adaptive noise injection (AdaNI) mechanism. This mechanism is guided by including prompt descriptions of age and gender for the given person as the textual condition. Also, by adjusting the noise level, we can control the strength of aging while allowing more flexibility in transforming the face. However, identity preservation is weakly ensured here to facilitate stronger age transformations. In the second pass, we enhance identity preservation while maintaining age-specific features by conditioning the model on two identity-aware embeddings (IDEmb): SVR-ArcFace and Rotate-CLIP. This pass allows for denoising the transformed image from the first pass, ensuring stronger identity preservation without compromising the aging accuracy. Both passes are jointly trained in an end-to-end way. Extensive experiments on the CelebA-HQ test dataset, evaluated through Face++ and Qwen-VL protocols, show that our Cradle2Cane outperforms existing face aging methods in age accuracy and identity consistency.
One-Way Ticket:Time-Independent Unified Encoder for Distilling Text-to-Image Diffusion Models
May 28, 2025
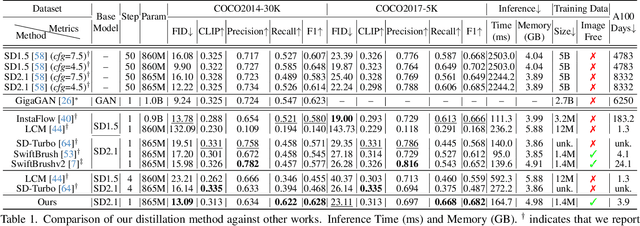

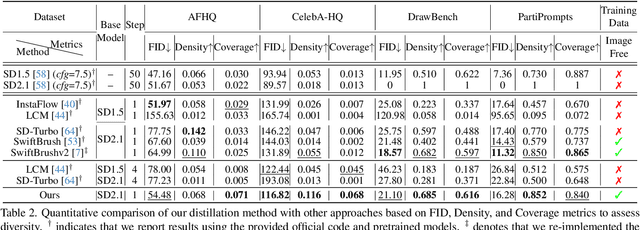
Text-to-Image (T2I) diffusion models have made remarkable advancements in generative modeling; however, they face a trade-off between inference speed and image quality, posing challenges for efficient deployment. Existing distilled T2I models can generate high-fidelity images with fewer sampling steps, but often struggle with diversity and quality, especially in one-step models. From our analysis, we observe redundant computations in the UNet encoders. Our findings suggest that, for T2I diffusion models, decoders are more adept at capturing richer and more explicit semantic information, while encoders can be effectively shared across decoders from diverse time steps. Based on these observations, we introduce the first Time-independent Unified Encoder TiUE for the student model UNet architecture, which is a loop-free image generation approach for distilling T2I diffusion models. Using a one-pass scheme, TiUE shares encoder features across multiple decoder time steps, enabling parallel sampling and significantly reducing inference time complexity. In addition, we incorporate a KL divergence term to regularize noise prediction, which enhances the perceptual realism and diversity of the generated images. Experimental results demonstrate that TiUE outperforms state-of-the-art methods, including LCM, SD-Turbo, and SwiftBrushv2, producing more diverse and realistic results while maintaining the computational efficiency.
Interpretable Credit Default Prediction with Ensemble Learning and SHAP
May 27, 2025



This study focuses on the problem of credit default prediction, builds a modeling framework based on machine learning, and conducts comparative experiments on a variety of mainstream classification algorithms. Through preprocessing, feature engineering, and model training of the Home Credit dataset, the performance of multiple models including logistic regression, random forest, XGBoost, LightGBM, etc. in terms of accuracy, precision, and recall is evaluated. The results show that the ensemble learning method has obvious advantages in predictive performance, especially in dealing with complex nonlinear relationships between features and data imbalance problems. It shows strong robustness. At the same time, the SHAP method is used to analyze the importance and dependency of features, and it is found that the external credit score variable plays a dominant role in model decision making, which helps to improve the model's interpretability and practical application value. The research results provide effective reference and technical support for the intelligent development of credit risk control systems.
AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control
May 06, 2025Humanoid robots derive much of their dexterity from hyper-dexterous whole-body movements, enabling tasks that require a large operational workspace: such as picking objects off the ground. However, achieving these capabilities on real humanoids remains challenging due to their high degrees of freedom (DoF) and nonlinear dynamics. We propose Adaptive Motion Optimization (AMO), a framework that integrates sim-to-real reinforcement learning (RL) with trajectory optimization for real-time, adaptive whole-body control. To mitigate distribution bias in motion imitation RL, we construct a hybrid AMO dataset and train a network capable of robust, on-demand adaptation to potentially O.O.D. commands. We validate AMO in simulation and on a 29-DoF Unitree G1 humanoid robot, demonstrating superior stability and an expanded workspace compared to strong baselines. Finally, we show that AMO's consistent performance supports autonomous task execution via imitation learning, underscoring the system's versatility and robustness.
Free-Lunch Color-Texture Disentanglement for Stylized Image Generation
Mar 21, 2025



Recent advances in Text-to-Image (T2I) diffusion models have transformed image generation, enabling significant progress in stylized generation using only a few style reference images. However, current diffusion-based methods struggle with fine-grained style customization due to challenges in controlling multiple style attributes, such as color and texture. This paper introduces the first tuning-free approach to achieve free-lunch color-texture disentanglement in stylized T2I generation, addressing the need for independently controlled style elements for the Disentangled Stylized Image Generation (DisIG) problem. Our approach leverages the Image-Prompt Additivity property in the CLIP image embedding space to develop techniques for separating and extracting Color-Texture Embeddings (CTE) from individual color and texture reference images. To ensure that the color palette of the generated image aligns closely with the color reference, we apply a whitening and coloring transformation to enhance color consistency. Additionally, to prevent texture loss due to the signal-leak bias inherent in diffusion training, we introduce a noise term that preserves textural fidelity during the Regularized Whitening and Coloring Transformation (RegWCT). Through these methods, our Style Attributes Disentanglement approach (SADis) delivers a more precise and customizable solution for stylized image generation. Experiments on images from the WikiArt and StyleDrop datasets demonstrate that, both qualitatively and quantitatively, SADis surpasses state-of-the-art stylization methods in the DisIG task.Code will be released at https://deepffff.github.io/sadis.github.io/.
Humanoid Policy ~ Human Policy
Mar 17, 2025Training manipulation policies for humanoid robots with diverse data enhances their robustness and generalization across tasks and platforms. However, learning solely from robot demonstrations is labor-intensive, requiring expensive tele-operated data collection which is difficult to scale. This paper investigates a more scalable data source, egocentric human demonstrations, to serve as cross-embodiment training data for robot learning. We mitigate the embodiment gap between humanoids and humans from both the data and modeling perspectives. We collect an egocentric task-oriented dataset (PH2D) that is directly aligned with humanoid manipulation demonstrations. We then train a human-humanoid behavior policy, which we term Human Action Transformer (HAT). The state-action space of HAT is unified for both humans and humanoid robots and can be differentiably retargeted to robot actions. Co-trained with smaller-scale robot data, HAT directly models humanoid robots and humans as different embodiments without additional supervision. We show that human data improves both generalization and robustness of HAT with significantly better data collection efficiency. Code and data: https://human-as-robot.github.io/
InterLCM: Low-Quality Images as Intermediate States of Latent Consistency Models for Effective Blind Face Restoration
Feb 04, 2025
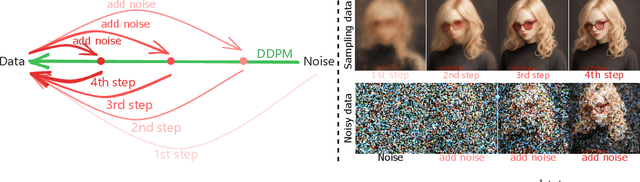
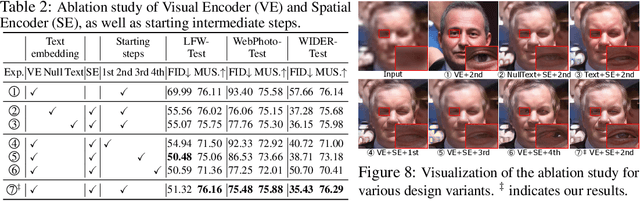
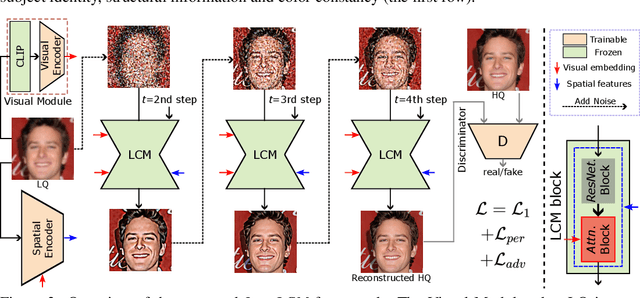
Diffusion priors have been used for blind face restoration (BFR) by fine-tuning diffusion models (DMs) on restoration datasets to recover low-quality images. However, the naive application of DMs presents several key limitations. (i) The diffusion prior has inferior semantic consistency (e.g., ID, structure and color.), increasing the difficulty of optimizing the BFR model; (ii) reliance on hundreds of denoising iterations, preventing the effective cooperation with perceptual losses, which is crucial for faithful restoration. Observing that the latent consistency model (LCM) learns consistency noise-to-data mappings on the ODE-trajectory and therefore shows more semantic consistency in the subject identity, structural information and color preservation, we propose InterLCM to leverage the LCM for its superior semantic consistency and efficiency to counter the above issues. Treating low-quality images as the intermediate state of LCM, InterLCM achieves a balance between fidelity and quality by starting from earlier LCM steps. LCM also allows the integration of perceptual loss during training, leading to improved restoration quality, particularly in real-world scenarios. To mitigate structural and semantic uncertainties, InterLCM incorporates a Visual Module to extract visual features and a Spatial Encoder to capture spatial details, enhancing the fidelity of restored images. Extensive experiments demonstrate that InterLCM outperforms existing approaches in both synthetic and real-world datasets while also achieving faster inference speed.
Mobile-TeleVision: Predictive Motion Priors for Humanoid Whole-Body Control
Dec 10, 2024



Humanoid robots require both robust lower-body locomotion and precise upper-body manipulation. While recent Reinforcement Learning (RL) approaches provide whole-body loco-manipulation policies, they lack precise manipulation with high DoF arms. In this paper, we propose decoupling upper-body control from locomotion, using inverse kinematics (IK) and motion retargeting for precise manipulation, while RL focuses on robust lower-body locomotion. We introduce PMP (Predictive Motion Priors), trained with Conditional Variational Autoencoder (CVAE) to effectively represent upper-body motions. The locomotion policy is trained conditioned on this upper-body motion representation, ensuring that the system remains robust with both manipulation and locomotion. We show that CVAE features are crucial for stability and robustness, and significantly outperforms RL-based whole-body control in precise manipulation. With precise upper-body motion and robust lower-body locomotion control, operators can remotely control the humanoid to walk around and explore different environments, while performing diverse manipulation tasks.