 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Modality Guidance to Enhance VFM-based Feature Fusion for UDA in 3D Semantic Segmentation
Apr 19, 2025Vision Foundation Models (VFMs) have become a de facto choice for many downstream vision tasks, like image classification, image segmentation, and object localization. However, they can also provide significant utility for downstream 3D tasks that can leverage the cross-modal information (e.g., from paired image data). In our work, we further explore the utility of VFMs for adapting from a labeled source to unlabeled target data for the task of LiDAR-based 3D semantic segmentation. Our method consumes paired 2D-3D (image and point cloud) data and relies on the robust (cross-domain) features from a VFM to train a 3D backbone on a mix of labeled source and unlabeled target data. At the heart of our method lies a fusion network that is guided by both the image and point cloud streams, with their relative contributions adjusted based on the target domain. We extensively compare our proposed methodology with different state-of-the-art methods in several settings and achieve strong performance gains. For example, achieving an average improvement of 6.5 mIoU (over all tasks), when compared with the previous state-of-the-art.
Teaching VLMs to Localize Specific Objects from In-context Examples
Nov 20, 2024



Vision-Language Models (VLMs) have shown remarkable capabilities across diverse visual tasks, including image recognition, video understanding, and Visual Question Answering (VQA) when explicitly trained for these tasks. Despite these advances, we find that current VLMs lack a fundamental cognitive ability: learning to localize objects in a scene by taking into account the context. In this work, we focus on the task of few-shot personalized localization, where a model is given a small set of annotated images (in-context examples) -- each with a category label and bounding box -- and is tasked with localizing the same object type in a query image. To provoke personalized localization abilities in models, we present a data-centric solution that fine-tunes them using carefully curated data from video object tracking datasets. By leveraging sequences of frames tracking the same object across multiple shots, we simulate instruction-tuning dialogues that promote context awareness. To reinforce this, we introduce a novel regularization technique that replaces object labels with pseudo-names, ensuring the model relies on visual context rather than prior knowledge. Our method significantly enhances few-shot localization performance without sacrificing generalization, as demonstrated on several benchmarks tailored to personalized localization. This work is the first to explore and benchmark personalized few-shot localization for VLMs, laying a foundation for future research in context-driven vision-language applications. The code for our project is available at https://github.com/SivanDoveh/IPLoc
LiveXiv -- A Multi-Modal Live Benchmark Based on Arxiv Papers Content
Oct 15, 2024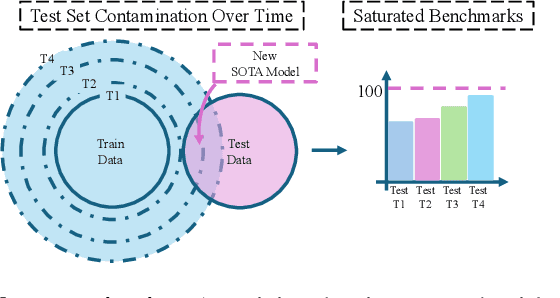



The large-scale training of multi-modal models on data scraped from the web has shown outstanding utility in infusing these models with the required world knowledge to perform effectively on multiple downstream tasks. However, one downside of scraping data from the web can be the potential sacrifice of the benchmarks on which the abilities of these models are often evaluated. To safeguard against test data contamination and to truly test the abilities of these foundation models we propose LiveXiv: A scalable evolving live benchmark based on scientific ArXiv papers. LiveXiv accesses domain-specific manuscripts at any given timestamp and proposes to automatically generate visual question-answer pairs (VQA). This is done without any human-in-the-loop, using the multi-modal content in the manuscripts, like graphs, charts, and tables. Moreover, we introduce an efficient evaluation approach that estimates the performance of all models on the evolving benchmark using evaluations of only a subset of models. This significantly reduces the overall evaluation cost. We benchmark multiple open and proprietary Large Multi-modal Models (LMMs) on the first version of our benchmark, showing its challenging nature and exposing the models true abilities, avoiding contamination. Lastly, in our commitment to high quality, we have collected and evaluated a manually verified subset. By comparing its overall results to our automatic annotations, we have found that the performance variance is indeed minimal (<2.5%). Our dataset is available online on HuggingFace, and our code will be available here.
Augmenting In-Context-Learning in LLMs via Automatic Data Labeling and Refinement
Oct 14, 2024It has been shown that Large Language Models' (LLMs) performance can be improved for many tasks using Chain of Thought (CoT) or In-Context Learning (ICL), which involve demonstrating the steps needed to solve a task using a few examples. However, while datasets with input-output pairs are relatively easy to produce, providing demonstrations which include intermediate steps requires cumbersome manual work. These steps may be executable programs, as in agentic flows, or step-by-step reasoning as in CoT. In this work, we propose Automatic Data Labeling and Refinement (ADLR), a method to automatically generate and filter demonstrations which include the above intermediate steps, starting from a small seed of manually crafted examples. We demonstrate the advantage of ADLR in code-based table QA and mathematical reasoning, achieving up to a 5.5% gain. The code implementing our method is provided in the Supplementary material and will be made available.
GLOV: Guided Large Language Models as Implicit Optimizers for Vision Language Models
Oct 08, 2024



In this work, we propose a novel method (GLOV) enabling Large Language Models (LLMs) to act as implicit Optimizers for Vision-Langugage Models (VLMs) to enhance downstream vision tasks. Our GLOV meta-prompts an LLM with the downstream task description, querying it for suitable VLM prompts (e.g., for zero-shot classification with CLIP). These prompts are ranked according to a purity measure obtained through a fitness function. In each respective optimization step, the ranked prompts are fed as in-context examples (with their accuracies) to equip the LLM with the knowledge of the type of text prompts preferred by the downstream VLM. Furthermore, we also explicitly steer the LLM generation process in each optimization step by specifically adding an offset difference vector of the embeddings from the positive and negative solutions found by the LLM, in previous optimization steps, to the intermediate layer of the network for the next generation step. This offset vector steers the LLM generation toward the type of language preferred by the downstream VLM, resulting in enhanced performance on the downstream vision tasks. We comprehensively evaluate our GLOV on 16 diverse datasets using two families of VLMs, i.e., dual-encoder (e.g., CLIP) and encoder-decoder (e.g., LLaVa) models -- showing that the discovered solutions can enhance the recognition performance by up to 15.0% and 57.5% (3.8% and 21.6% on average) for these models.
Comparison Visual Instruction Tuning
Jun 13, 2024



Comparing two images in terms of Commonalities and Differences (CaD) is a fundamental human capability that forms the basis of advanced visual reasoning and interpretation. It is essential for the generation of detailed and contextually relevant descriptions, performing comparative analysis, novelty detection, and making informed decisions based on visual data. However, surprisingly, little attention has been given to these fundamental concepts in the best current mimic of human visual intelligence - Large Multimodal Models (LMMs). We develop and contribute a new two-phase approach CaD-VI for collecting synthetic visual instructions, together with an instruction-following dataset CaD-Inst containing 349K image pairs with CaD instructions collected using CaD-VI. Our approach significantly improves the CaD spotting capabilities in LMMs, advancing the SOTA on a diverse set of related tasks by up to 17.5%. It is also complementary to existing difference-only instruction datasets, allowing automatic targeted refinement of those resources increasing their effectiveness for CaD tuning by up to 10%. Additionally, we propose an evaluation benchmark with 7.5K open-ended QAs to assess the CaD understanding abilities of LMMs.
ConMe: Rethinking Evaluation of Compositional Reasoning for Modern VLMs
Jun 12, 2024



Compositional Reasoning (CR) entails grasping the significance of attributes, relations, and word order. Recent Vision-Language Models (VLMs), comprising a visual encoder and a Large Language Model (LLM) decoder, have demonstrated remarkable proficiency in such reasoning tasks. This prompts a crucial question: have VLMs effectively tackled the CR challenge? We conjecture that existing CR benchmarks may not adequately push the boundaries of modern VLMs due to the reliance on an LLM-only negative text generation pipeline. Consequently, the negatives produced either appear as outliers from the natural language distribution learned by VLMs' LLM decoders or as improbable within the corresponding image context. To address these limitations, we introduce ConMe -- a compositional reasoning benchmark and a novel data generation pipeline leveraging VLMs to produce `hard CR Q&A'. Through a new concept of VLMs conversing with each other to collaboratively expose their weaknesses, our pipeline autonomously generates, evaluates, and selects challenging compositional reasoning questions, establishing a robust CR benchmark, also subsequently validated manually. Our benchmark provokes a noteworthy, up to 33%, decrease in CR performance compared to preceding benchmarks, reinstating the CR challenge even for state-of-the-art VLMs.
NumeroLogic: Number Encoding for Enhanced LLMs' Numerical Reasoning
Mar 30, 2024



Language models struggle with handling numerical data and performing arithmetic operations. We hypothesize that this limitation can be partially attributed to non-intuitive textual numbers representation. When a digit is read or generated by a causal language model it does not know its place value (e.g. thousands vs. hundreds) until the entire number is processed. To address this issue, we propose a simple adjustment to how numbers are represented by including the count of digits before each number. For instance, instead of "42", we suggest using "{2:42}" as the new format. This approach, which we term NumeroLogic, offers an added advantage in number generation by serving as a Chain of Thought (CoT). By requiring the model to consider the number of digits first, it enhances the reasoning process before generating the actual number. We use arithmetic tasks to demonstrate the effectiveness of the NumeroLogic formatting. We further demonstrate NumeroLogic applicability to general natural language modeling, improving language understanding performance in the MMLU benchmark.
Towards Multimodal In-Context Learning for Vision & Language Models
Mar 19, 2024



Inspired by the emergence of Large Language Models (LLMs) that can truly understand human language, significant progress has been made in aligning other, non-language, modalities to be `understandable' by an LLM, primarily via converting their samples into a sequence of embedded language-like tokens directly fed into the LLM (decoder) input stream. However, so far limited attention has been given to transferring (and evaluating) one of the core LLM capabilities to the emerging VLMs, namely the In-Context Learning (ICL) ability, or in other words to guide VLMs to desired target downstream tasks or output structure using in-context image+text demonstrations. In this work, we dive deeper into analyzing the capabilities of some of the state-of-the-art VLMs to follow ICL instructions, discovering them to be somewhat lacking. We discover that even models that underwent large-scale mixed modality pre-training and were implicitly guided to make use of interleaved image and text information (intended to consume helpful context from multiple images) under-perform when prompted with few-shot (ICL) demonstrations, likely due to their lack of `direct' ICL instruction tuning. To test this conjecture, we propose a simple, yet surprisingly effective, strategy of extending a common VLM alignment framework with ICL support, methodology, and curriculum. We explore, analyze, and provide insights into effective data mixes, leading up to a significant 21.03% (and 11.3% on average) ICL performance boost over the strongest VLM baselines and a variety of ICL benchmarks. We also contribute new benchmarks for ICL evaluation in VLMs and discuss their advantages over the prior art.
Meta-Prompting for Automating Zero-shot Visual Recognition with LLMs
Mar 19, 2024Prompt ensembling of Large Language Model (LLM) generated category-specific prompts has emerged as an effective method to enhance zero-shot recognition ability of Vision-Language Models (VLMs). To obtain these category-specific prompts, the present methods rely on hand-crafting the prompts to the LLMs for generating VLM prompts for the downstream tasks. However, this requires manually composing these task-specific prompts and still, they might not cover the diverse set of visual concepts and task-specific styles associated with the categories of interest. To effectively take humans out of the loop and completely automate the prompt generation process for zero-shot recognition, we propose Meta-Prompting for Visual Recognition (MPVR). Taking as input only minimal information about the target task, in the form of its short natural language description, and a list of associated class labels, MPVR automatically produces a diverse set of category-specific prompts resulting in a strong zero-shot classifier. MPVR generalizes effectively across various popular zero-shot image recognition benchmarks belonging to widely different domains when tested with multiple LLMs and VLMs. For example, MPVR obtains a zero-shot recognition improvement over CLIP by up to 19.8% and 18.2% (5.0% and 4.5% on average over 20 datasets) leveraging GPT and Mixtral LLMs, respectively