 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMULDE: Multiscale Log-Density Estimation via Denoising Score Matching for Video Anomaly Detection
Mar 21, 2024



We propose a novel approach to video anomaly detection: we treat feature vectors extracted from videos as realizations of a random variable with a fixed distribution and model this distribution with a neural network. This lets us estimate the likelihood of test videos and detect video anomalies by thresholding the likelihood estimates. We train our video anomaly detector using a modification of denoising score matching, a method that injects training data with noise to facilitate modeling its distribution. To eliminate hyperparameter selection, we model the distribution of noisy video features across a range of noise levels and introduce a regularizer that tends to align the models for different levels of noise. At test time, we combine anomaly indications at multiple noise scales with a Gaussian mixture model. Running our video anomaly detector induces minimal delays as inference requires merely extracting the features and forward-propagating them through a shallow neural network and a Gaussian mixture model. Our experiments on five popular video anomaly detection benchmarks demonstrate state-of-the-art performance, both in the object-centric and in the frame-centric setup.
Meta-Prompting for Automating Zero-shot Visual Recognition with LLMs
Mar 19, 2024Prompt ensembling of Large Language Model (LLM) generated category-specific prompts has emerged as an effective method to enhance zero-shot recognition ability of Vision-Language Models (VLMs). To obtain these category-specific prompts, the present methods rely on hand-crafting the prompts to the LLMs for generating VLM prompts for the downstream tasks. However, this requires manually composing these task-specific prompts and still, they might not cover the diverse set of visual concepts and task-specific styles associated with the categories of interest. To effectively take humans out of the loop and completely automate the prompt generation process for zero-shot recognition, we propose Meta-Prompting for Visual Recognition (MPVR). Taking as input only minimal information about the target task, in the form of its short natural language description, and a list of associated class labels, MPVR automatically produces a diverse set of category-specific prompts resulting in a strong zero-shot classifier. MPVR generalizes effectively across various popular zero-shot image recognition benchmarks belonging to widely different domains when tested with multiple LLMs and VLMs. For example, MPVR obtains a zero-shot recognition improvement over CLIP by up to 19.8% and 18.2% (5.0% and 4.5% on average over 20 datasets) leveraging GPT and Mixtral LLMs, respectively
Sit Back and Relax: Learning to Drive Incrementally in All Weather Conditions
May 30, 2023



In autonomous driving scenarios, current object detection models show strong performance when tested in clear weather. However, their performance deteriorates significantly when tested in degrading weather conditions. In addition, even when adapted to perform robustly in a sequence of different weather conditions, they are often unable to perform well in all of them and suffer from catastrophic forgetting. To efficiently mitigate forgetting, we propose Domain-Incremental Learning through Activation Matching (DILAM), which employs unsupervised feature alignment to adapt only the affine parameters of a clear weather pre-trained network to different weather conditions. We propose to store these affine parameters as a memory bank for each weather condition and plug-in their weather-specific parameters during driving (i.e. test time) when the respective weather conditions are encountered. Our memory bank is extremely lightweight, since affine parameters account for less than 2% of a typical object detector. Furthermore, contrary to previous domain-incremental learning approaches, we do not require the weather label when testing and propose to automatically infer the weather condition by a majority voting linear classifier.
LaFTer: Label-Free Tuning of Zero-shot Classifier using Language and Unlabeled Image Collections
May 29, 2023Recently, large-scale pre-trained Vision and Language (VL) models have set a new state-of-the-art (SOTA) in zero-shot visual classification enabling open-vocabulary recognition of potentially unlimited set of categories defined as simple language prompts. However, despite these great advances, the performance of these zeroshot classifiers still falls short of the results of dedicated (closed category set) classifiers trained with supervised fine tuning. In this paper we show, for the first time, how to reduce this gap without any labels and without any paired VL data, using an unlabeled image collection and a set of texts auto-generated using a Large Language Model (LLM) describing the categories of interest and effectively substituting labeled visual instances of those categories. Using our label-free approach, we are able to attain significant performance improvements over the zero-shot performance of the base VL model and other contemporary methods and baselines on a wide variety of datasets, demonstrating absolute improvement of up to 11.7% (3.8% on average) in the label-free setting. Moreover, despite our approach being label-free, we observe 1.3% average gains over leading few-shot prompting baselines that do use 5-shot supervision.
MAtch, eXpand and Improve: Unsupervised Finetuning for Zero-Shot Action Recognition with Language Knowledge
Mar 15, 2023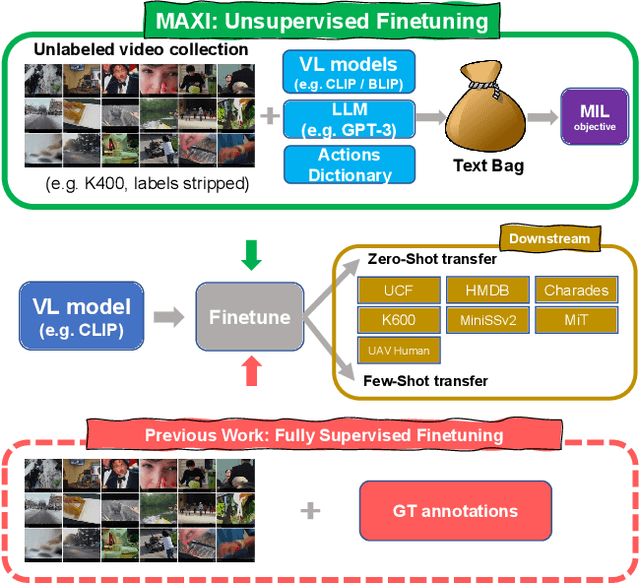
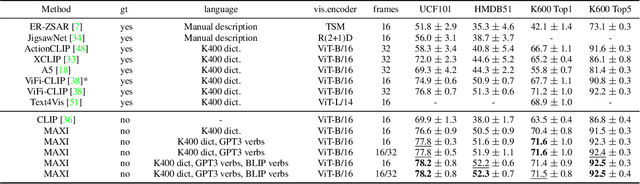
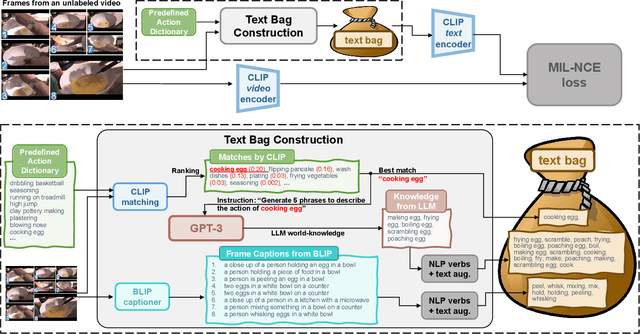

Large scale Vision-Language (VL) models have shown tremendous success in aligning representations between visual and text modalities. This enables remarkable progress in zero-shot recognition, image generation & editing, and many other exciting tasks. However, VL models tend to over-represent objects while paying much less attention to verbs, and require additional tuning on video data for best zero-shot action recognition performance. While previous work relied on large-scale, fully-annotated data, in this work we propose an unsupervised approach. We adapt a VL model for zero-shot and few-shot action recognition using a collection of unlabeled videos and an unpaired action dictionary. Based on that, we leverage Large Language Models and VL models to build a text bag for each unlabeled video via matching, text expansion and captioning. We use those bags in a Multiple Instance Learning setup to adapt an image-text backbone to video data. Although finetuned on unlabeled video data, our resulting models demonstrate high transferability to numerous unseen zero-shot downstream tasks, improving the base VL model performance by up to 14\%, and even comparing favorably to fully-supervised baselines in both zero-shot and few-shot video recognition transfer. The code will be released later at \url{https://github.com/wlin-at/MAXI}.
Video Test-Time Adaptation for Action Recognition
Dec 02, 2022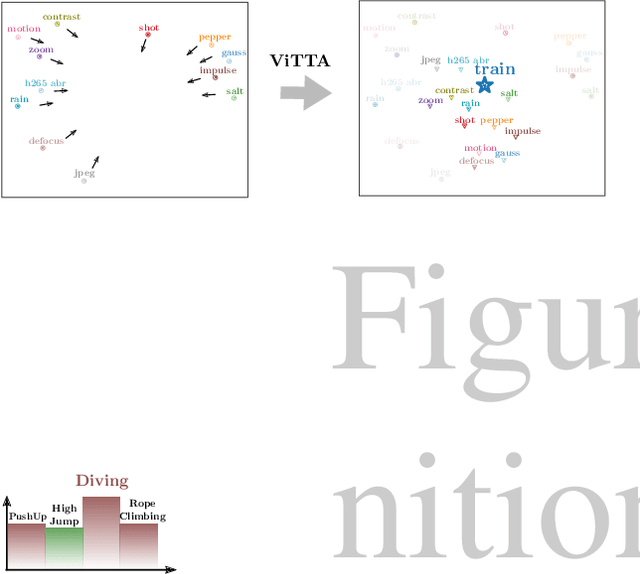
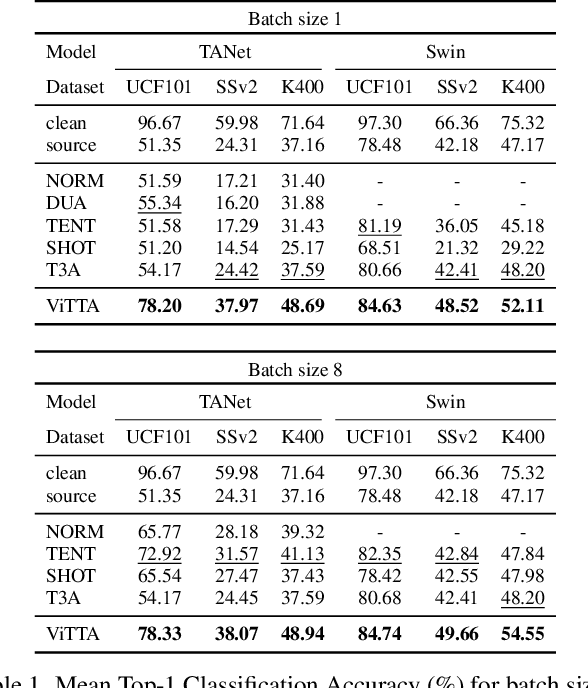
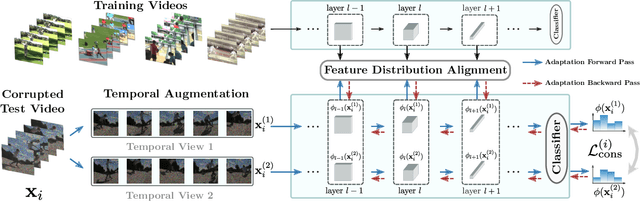
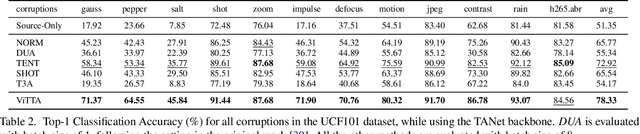
Although action recognition systems can achieve top performance when evaluated on in-distribution test points, they are vulnerable to unanticipated distribution shifts in test data. However, test-time adaptation of video action recognition models against common distribution shifts has so far not been demonstrated. We propose to address this problem with an approach tailored to spatio-temporal models that is capable of adaptation on a single video sample at a step. It consists in a feature distribution alignment technique that aligns online estimates of test set statistics towards the training statistics. We further enforce prediction consistency over temporally augmented views of the same test video sample. Evaluations on three benchmark action recognition datasets show that our proposed technique is architecture-agnostic and able to significantly boost the performance on both, the state of the art convolutional architecture TANet and the Video Swin Transformer. Our proposed method demonstrates a substantial performance gain over existing test-time adaptation approaches in both evaluations of a single distribution shift and the challenging case of random distribution shifts. Code will be available at \url{https://github.com/wlin-at/ViTTA}.
MATE: Masked Autoencoders are Online 3D Test-Time Learners
Nov 24, 2022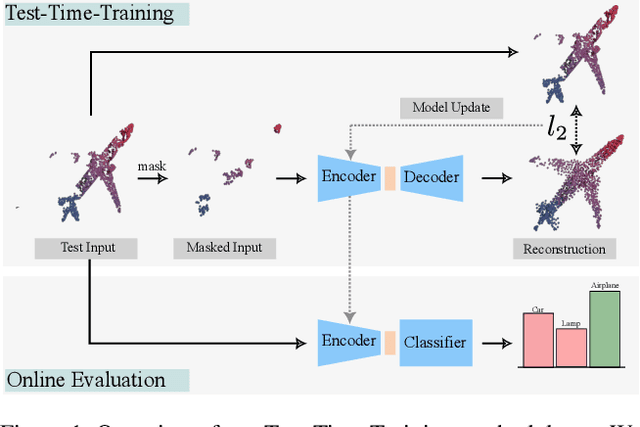



We propose MATE, the first Test-Time-Training (TTT) method designed for 3D data. It makes deep networks trained in point cloud classification robust to distribution shifts occurring in test data, which could not be anticipated during training. Like existing TTT methods, which focused on classifying 2D images in the presence of distribution shifts at test-time, MATE also leverages test data for adaptation. Its test-time objective is that of a Masked Autoencoder: Each test point cloud has a large portion of its points removed before it is fed to the network, tasked with reconstructing the full point cloud. Once the network is updated, it is used to classify the point cloud. We test MATE on several 3D object classification datasets and show that it significantly improves robustness of deep networks to several types of corruptions commonly occurring in 3D point clouds. Further, we show that MATE is very efficient in terms of the fraction of points it needs for the adaptation. It can effectively adapt given as few as 5% of tokens of each test sample, which reduces its memory footprint and makes it lightweight. We also highlight that MATE achieves competitive performance by adapting sparingly on the test data, which further reduces its computational overhead, making it ideal for real-time applications.
ActMAD: Activation Matching to Align Distributions for Test-Time-Training
Nov 23, 2022



Test-Time-Training (TTT) is an approach to cope with out-of-distribution (OOD) data by adapting a trained model to distribution shifts occurring at test-time. We propose to perform this adaptation via Activation Matching (ActMAD): We analyze activations of the model and align activation statistics of the OOD test data to those of the training data. In contrast to existing methods, which model the distribution of entire channels in the ultimate layer of the feature extractor, we model the distribution of each feature in multiple layers across the network. This results in a more fine-grained supervision and makes ActMAD attain state of the art performance on CIFAR-100C and Imagenet-C. ActMAD is also architecture- and task-agnostic, which lets us go beyond image classification, and score 15.4% improvement over previous approaches when evaluating a KITTI-trained object detector on KITTI-Fog. Our experiments highlight that ActMAD can be applied to online adaptation in realistic scenarios, requiring little data to attain its full performance.
Enforcing connectivity of 3D linear structures using their 2D projections
Jul 14, 2022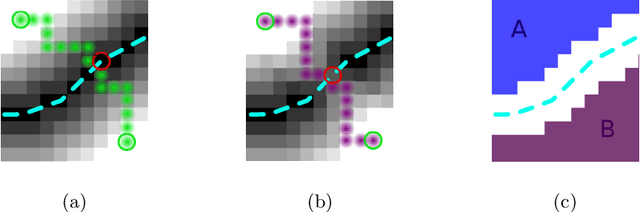
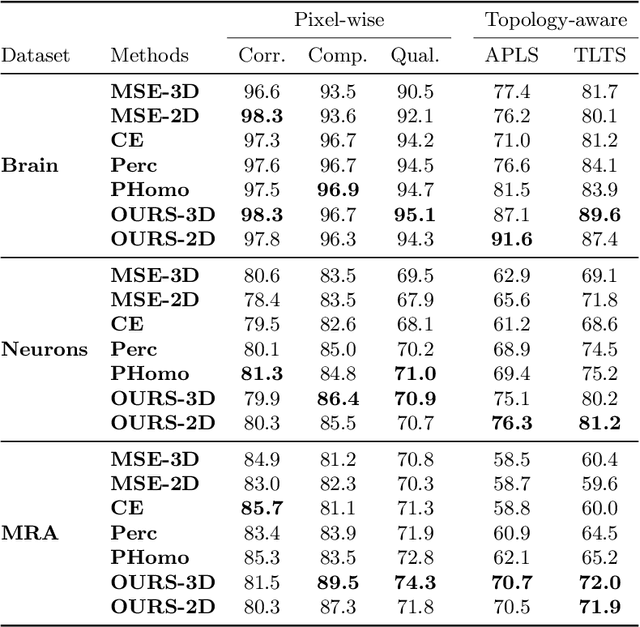
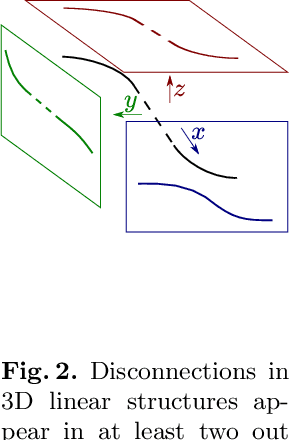
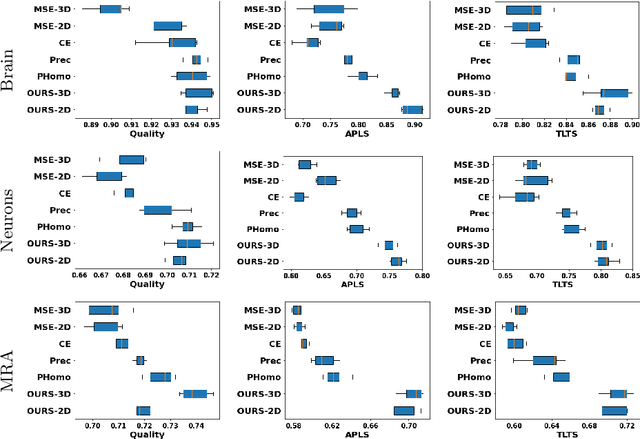
Many biological and medical tasks require the delineation of 3D curvilinear structures such as blood vessels and neurites from image volumes. This is typically done using neural networks trained by minimizing voxel-wise loss functions that do not capture the topological properties of these structures. As a result, the connectivity of the recovered structures is often wrong, which lessens their usefulness. In this paper, we propose to improve the 3D connectivity of our results by minimizing a sum of topology-aware losses on their 2D projections. This suffices to increase the accuracy and to reduce the annotation effort required to provide the required annotated training data.
TopoAL: An Adversarial Learning Approach for Topology-Aware Road Segmentation
Jul 17, 2020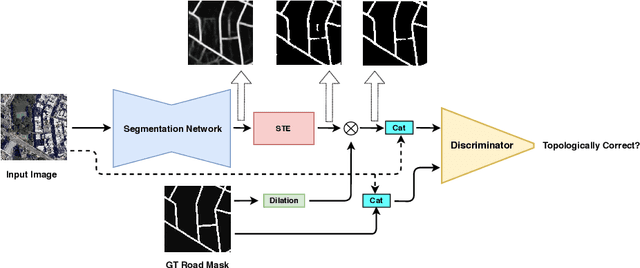



Most state-of-the-art approaches to road extraction from aerial images rely on a CNN trained to label road pixels as foreground and remainder of the image as background. The CNN is usually trained by minimizing pixel-wise losses, which is less than ideal to produce binary masks that preserve the road network's global connectivity. To address this issue, we introduce an Adversarial Learning (AL) strategy tailored for our purposes. A naive one would treat the segmentation network as a generator and would feed its output along with ground-truth segmentations to a discriminator. It would then train the generator and discriminator jointly. We will show that this is not enough because it does not capture the fact that most errors are local and need to be treated as such. Instead, we use a more sophisticated discriminator that returns a label pyramid describing what portions of the road network are correct at several different scales. This discriminator and the structured labels it returns are what gives our approach its edge and we will show that it outperforms state-of-the-art ones on the challenging RoadTracer dataset.