 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Motion Prediction: A Lightweight & Accurate Trajectory Prediction Model With Fast Training and Inference Speed
Sep 25, 2024



For efficient and safe autonomous driving, it is essential that autonomous vehicles can predict the motion of other traffic agents. While highly accurate, current motion prediction models often impose significant challenges in terms of training resource requirements and deployment on embedded hardware. We propose a new efficient motion prediction model, which achieves highly competitive benchmark results while training only a few hours on a single GPU. Due to our lightweight architectural choices and the focus on reducing the required training resources, our model can easily be applied to custom datasets. Furthermore, its low inference latency makes it particularly suitable for deployment in autonomous applications with limited computing resources.
Enhanced Expressivity in Graph Neural Networks with Lanczos-Based Linear Constraints
Aug 22, 2024Graph Neural Networks (GNNs) excel in handling graph-structured data but often underperform in link prediction tasks compared to classical methods, mainly due to the limitations of the commonly used Message Passing GNNs (MPNNs). Notably, their ability to distinguish non-isomorphic graphs is limited by the 1-dimensional Weisfeiler-Lehman test. Our study presents a novel method to enhance the expressivity of GNNs by embedding induced subgraphs into the graph Laplacian matrix's eigenbasis. We introduce a Learnable Lanczos algorithm with Linear Constraints (LLwLC), proposing two novel subgraph extraction strategies: encoding vertex-deleted subgraphs and applying Neumann eigenvalue constraints. For the former, we conjecture that LLwLC establishes a universal approximator, offering efficient time complexity. The latter focuses on link representations enabling differentiation between $k$-regular graphs and node automorphism, a vital aspect for link prediction tasks. Our approach results in an extremely lightweight architecture, reducing the need for extensive training datasets. Empirically, our method improves performance in challenging link prediction tasks across benchmark datasets, establishing its practical utility and supporting our theoretical findings. Notably, LLwLC achieves 20x and 10x speedup by only requiring 5% and 10% data from the PubMed and OGBL-Vessel datasets while comparing to the state-of-the-art.
Vision-Language Guidance for LiDAR-based Unsupervised 3D Object Detection
Aug 07, 2024
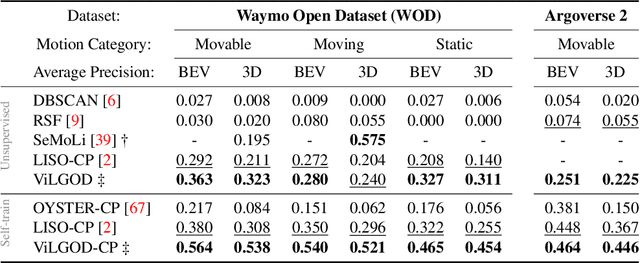
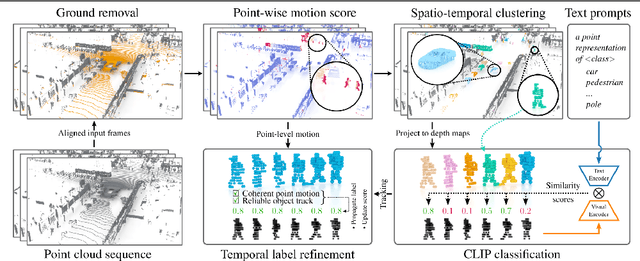
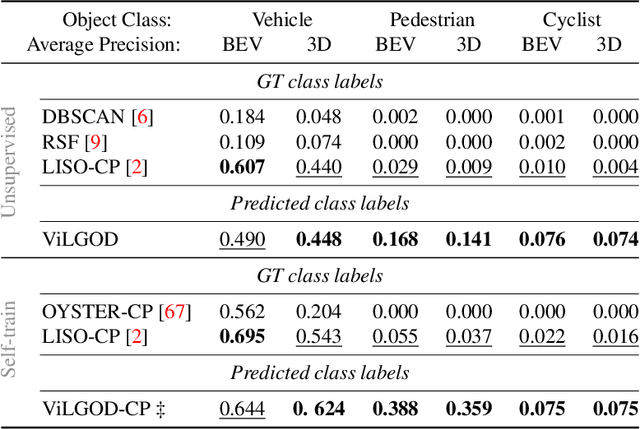
Accurate 3D object detection in LiDAR point clouds is crucial for autonomous driving systems. To achieve state-of-the-art performance, the supervised training of detectors requires large amounts of human-annotated data, which is expensive to obtain and restricted to predefined object categories. To mitigate manual labeling efforts, recent unsupervised object detection approaches generate class-agnostic pseudo-labels for moving objects, subsequently serving as supervision signal to bootstrap a detector. Despite promising results, these approaches do not provide class labels or generalize well to static objects. Furthermore, they are mostly restricted to data containing multiple drives from the same scene or images from a precisely calibrated and synchronized camera setup. To overcome these limitations, we propose a vision-language-guided unsupervised 3D detection approach that operates exclusively on LiDAR point clouds. We transfer CLIP knowledge to classify point clusters of static and moving objects, which we discover by exploiting the inherent spatio-temporal information of LiDAR point clouds for clustering, tracking, as well as box and label refinement. Our approach outperforms state-of-the-art unsupervised 3D object detectors on the Waymo Open Dataset ($+23~\text{AP}_{3D}$) and Argoverse 2 ($+7.9~\text{AP}_{3D}$) and provides class labels not solely based on object size assumptions, marking a significant advancement in the field.
Occlusion Handling in 3D Human Pose Estimation with Perturbed Positional Encoding
May 27, 2024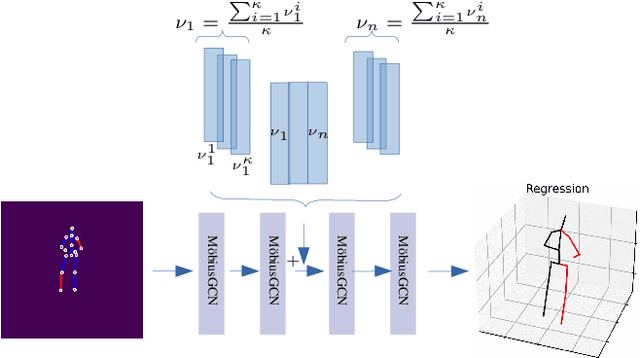
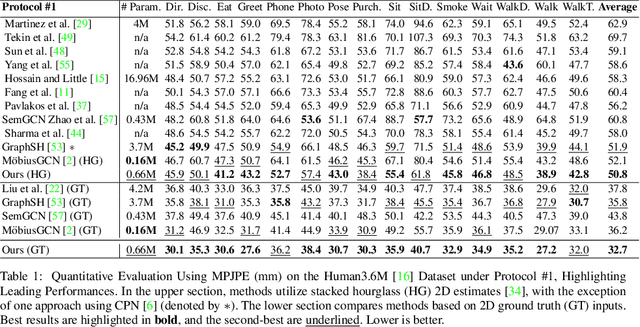
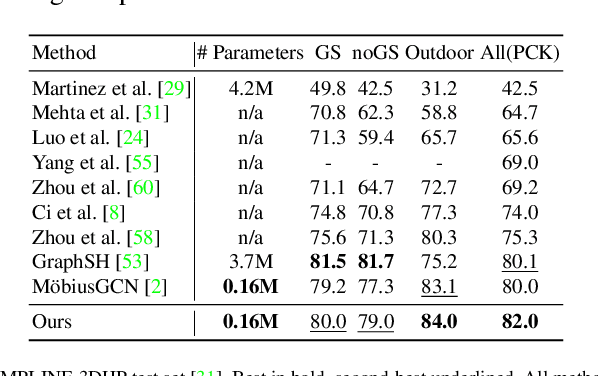
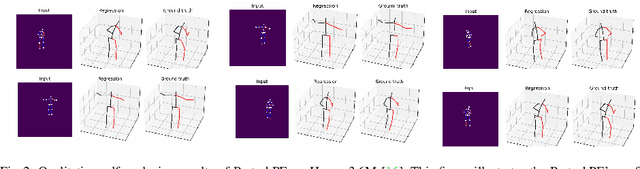
Understanding human behavior fundamentally relies on accurate 3D human pose estimation. Graph Convolutional Networks (GCNs) have recently shown promising advancements, delivering state-of-the-art performance with rather lightweight architectures. In the context of graph-structured data, leveraging the eigenvectors of the graph Laplacian matrix for positional encoding is effective. Yet, the approach does not specify how to handle scenarios where edges in the input graph are missing. To this end, we propose a novel positional encoding technique, PerturbPE, that extracts consistent and regular components from the eigenbasis. Our method involves applying multiple perturbations and taking their average to extract the consistent and regular component from the eigenbasis. PerturbPE leverages the Rayleigh-Schrodinger Perturbation Theorem (RSPT) for calculating the perturbed eigenvectors. Employing this labeling technique enhances the robustness and generalizability of the model. Our results support our theoretical findings, e.g. our experimental analysis observed a performance enhancement of up to $12\%$ on the Human3.6M dataset in instances where occlusion resulted in the absence of one edge. Furthermore, our novel approach significantly enhances performance in scenarios where two edges are missing, setting a new benchmark for state-of-the-art.
Into the Fog: Evaluating Multiple Object Tracking Robustness
Apr 12, 2024



State-of-the-art (SOTA) trackers have shown remarkable Multiple Object Tracking (MOT) performance when trained and evaluated on current benchmarks. However, these benchmarks primarily consist of clear scenarios, overlooking adverse atmospheric conditions such as fog, haze, smoke and dust. As a result, the robustness of SOTA trackers remains underexplored. To address these limitations, we propose a pipeline for physic-based volumetric fog simulation in arbitrary real-world MOT dataset utilizing frame-by-frame monocular depth estimation and a fog formation optical model. Moreover, we enhance our simulation by rendering of both homogeneous and heterogeneous fog effects. We propose to use the dark channel prior method to estimate fog (smoke) color, which shows promising results even in night and indoor scenes. We present the leading tracking benchmark MOTChallenge (MOT17 dataset) overlaid by fog (smoke for indoor scenes) of various intensity levels and conduct a comprehensive evaluation of SOTA MOT methods, revealing their limitations under fog and fog-similar challenges.
MULDE: Multiscale Log-Density Estimation via Denoising Score Matching for Video Anomaly Detection
Mar 21, 2024



We propose a novel approach to video anomaly detection: we treat feature vectors extracted from videos as realizations of a random variable with a fixed distribution and model this distribution with a neural network. This lets us estimate the likelihood of test videos and detect video anomalies by thresholding the likelihood estimates. We train our video anomaly detector using a modification of denoising score matching, a method that injects training data with noise to facilitate modeling its distribution. To eliminate hyperparameter selection, we model the distribution of noisy video features across a range of noise levels and introduce a regularizer that tends to align the models for different levels of noise. At test time, we combine anomaly indications at multiple noise scales with a Gaussian mixture model. Running our video anomaly detector induces minimal delays as inference requires merely extracting the features and forward-propagating them through a shallow neural network and a Gaussian mixture model. Our experiments on five popular video anomaly detection benchmarks demonstrate state-of-the-art performance, both in the object-centric and in the frame-centric setup.
Identifying and Extracting Pedestrian Behavior in Critical Traffic Situations
Feb 04, 2024A better understanding of interactive pedestrian behavior in critical traffic situations is essential for the development of enhanced pedestrian safety systems. Real-world traffic observations play a decisive role in this, since they represent behavior in an unbiased way. In this work, we present an approach of how a subset of very considerable pedestrian-vehicle interactions can be derived from a camera-based observation system. For this purpose, we have examined road user trajectories automatically for establishing temporal and spatial relationships, using 110h hours of video recordings. In order to identify critical interactions, our approach combines the metric post-encroachment time with a newly introduced motion adaption metric. From more than 11,000 reconstructed pedestrian trajectories, 259 potential scenarios remained, using a post-encroachment time threshold of 2s. However, in 95% of cases, no adaptation of the pedestrian behavior was observed due to avoiding criticality. Applying the proposed motion adaption metric, only 21 critical scenarios remained. Manual investigations revealed that critical pedestrian vehicle interactions were present in 7 of those. They were further analyzed and made publicly available for developing pedestrian behavior models3. The results indicate that critical interactions in which the pedestrian perceives and reacts to the vehicle at a relatively late stage can be extracted using the proposed method.
Robust Localization of Key Fob Using Channel Impulse Response of Ultra Wide Band Sensors for Keyless Entry Systems
Jan 16, 2024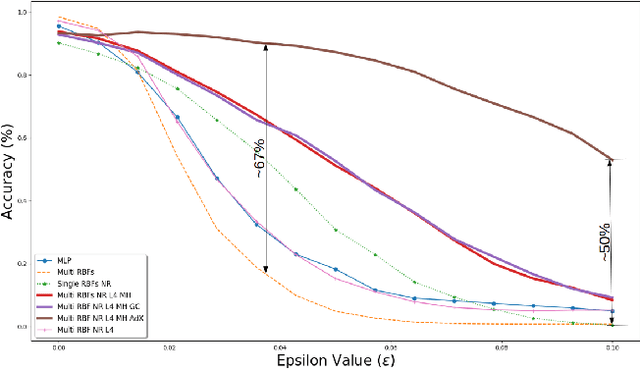
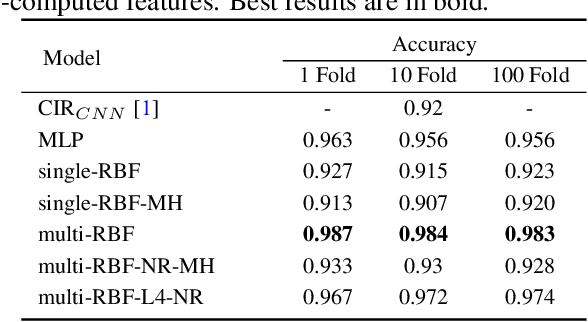
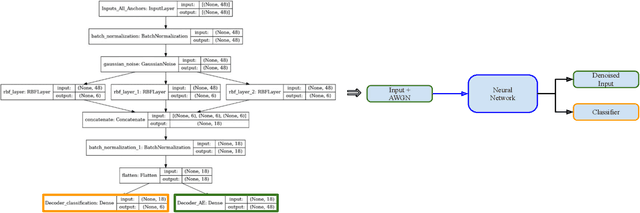
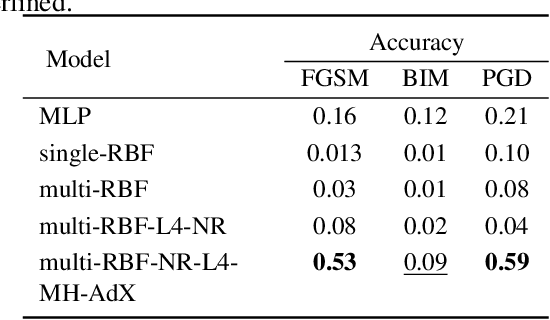
Using neural networks for localization of key fob within and surrounding a car as a security feature for keyless entry is fast emerging. In this paper we study: 1) the performance of pre-computed features of neural networks based UWB (ultra wide band) localization classification forming the baseline of our experiments. 2) Investigate the inherent robustness of various neural networks; therefore, we include the study of robustness of the adversarial examples without any adversarial training in this work. 3) Propose a multi-head self-supervised neural network architecture which outperforms the baseline neural networks without any adversarial training. The model's performance improved by 67% at certain ranges of adversarial magnitude for fast gradient sign method and 37% each for basic iterative method and projected gradient descent method.
GACE: Geometry Aware Confidence Enhancement for Black-Box 3D Object Detectors on LiDAR-Data
Oct 31, 2023



Widely-used LiDAR-based 3D object detectors often neglect fundamental geometric information readily available from the object proposals in their confidence estimation. This is mostly due to architectural design choices, which were often adopted from the 2D image domain, where geometric context is rarely available. In 3D, however, considering the object properties and its surroundings in a holistic way is important to distinguish between true and false positive detections, e.g. occluded pedestrians in a group. To address this, we present GACE, an intuitive and highly efficient method to improve the confidence estimation of a given black-box 3D object detector. We aggregate geometric cues of detections and their spatial relationships, which enables us to properly assess their plausibility and consequently, improve the confidence estimation. This leads to consistent performance gains over a variety of state-of-the-art detectors. Across all evaluated detectors, GACE proves to be especially beneficial for the vulnerable road user classes, i.e. pedestrians and cyclists.
TAP: Targeted Prompting for Task Adaptive Generation of Textual Training Instances for Visual Classification
Sep 13, 2023



Vision and Language Models (VLMs), such as CLIP, have enabled visual recognition of a potentially unlimited set of categories described by text prompts. However, for the best visual recognition performance, these models still require tuning to better fit the data distributions of the downstream tasks, in order to overcome the domain shift from the web-based pre-training data. Recently, it has been shown that it is possible to effectively tune VLMs without any paired data, and in particular to effectively improve VLMs visual recognition performance using text-only training data generated by Large Language Models (LLMs). In this paper, we dive deeper into this exciting text-only VLM training approach and explore ways it can be significantly further improved taking the specifics of the downstream task into account when sampling text data from LLMs. In particular, compared to the SOTA text-only VLM training approach, we demonstrate up to 8.4% performance improvement in (cross) domain-specific adaptation, up to 8.7% improvement in fine-grained recognition, and 3.1% overall average improvement in zero-shot classification compared to strong baselines.