 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTSBench: A Spatio-temporal Scenario Benchmark for Multi-modal Large Language Models in Autonomous Driving
Jun 06, 2025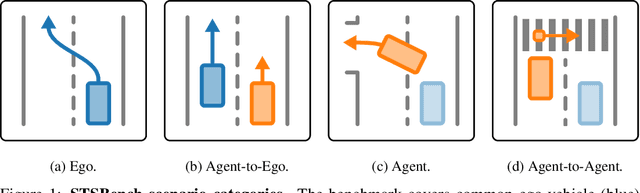
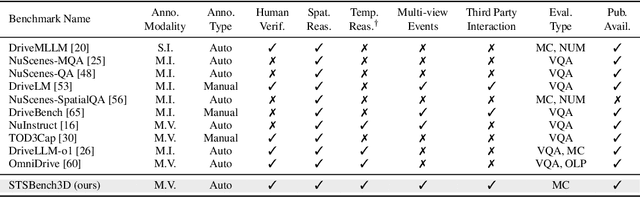
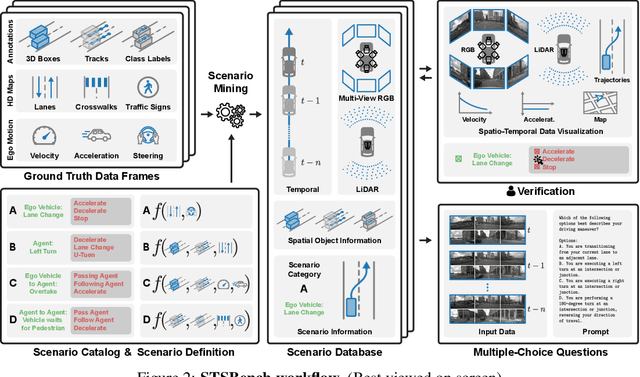
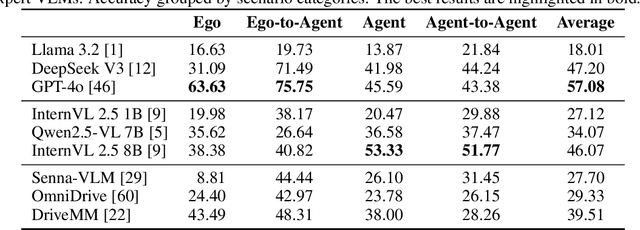
We introduce STSBench, a scenario-based framework to benchmark the holistic understanding of vision-language models (VLMs) for autonomous driving. The framework automatically mines pre-defined traffic scenarios from any dataset using ground-truth annotations, provides an intuitive user interface for efficient human verification, and generates multiple-choice questions for model evaluation. Applied to the NuScenes dataset, we present STSnu, the first benchmark that evaluates the spatio-temporal reasoning capabilities of VLMs based on comprehensive 3D perception. Existing benchmarks typically target off-the-shelf or fine-tuned VLMs for images or videos from a single viewpoint and focus on semantic tasks such as object recognition, dense captioning, risk assessment, or scene understanding. In contrast, STSnu evaluates driving expert VLMs for end-to-end driving, operating on videos from multi-view cameras or LiDAR. It specifically assesses their ability to reason about both ego-vehicle actions and complex interactions among traffic participants, a crucial capability for autonomous vehicles. The benchmark features 43 diverse scenarios spanning multiple views and frames, resulting in 971 human-verified multiple-choice questions. A thorough evaluation uncovers critical shortcomings in existing models' ability to reason about fundamental traffic dynamics in complex environments. These findings highlight the urgent need for architectural advances that explicitly model spatio-temporal reasoning. By addressing a core gap in spatio-temporal evaluation, STSBench enables the development of more robust and explainable VLMs for autonomous driving.
LiSu: A Dataset and Method for LiDAR Surface Normal Estimation
Mar 11, 2025
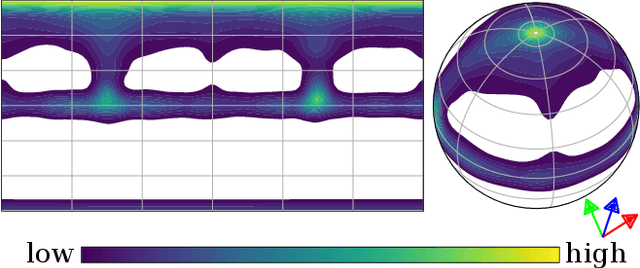


While surface normals are widely used to analyse 3D scene geometry, surface normal estimation from LiDAR point clouds remains severely underexplored. This is caused by the lack of large-scale annotated datasets on the one hand, and lack of methods that can robustly handle the sparse and often noisy LiDAR data in a reasonable time on the other hand. We address these limitations using a traffic simulation engine and present LiSu, the first large-scale, synthetic LiDAR point cloud dataset with ground truth surface normal annotations, eliminating the need for tedious manual labeling. Additionally, we propose a novel method that exploits the spatiotemporal characteristics of autonomous driving data to enhance surface normal estimation accuracy. By incorporating two regularization terms, we enforce spatial consistency among neighboring points and temporal smoothness across consecutive LiDAR frames. These regularizers are particularly effective in self-training settings, where they mitigate the impact of noisy pseudo-labels, enabling robust real-world deployment. We demonstrate the effectiveness of our method on LiSu, achieving state-of-the-art performance in LiDAR surface normal estimation. Moreover, we showcase its full potential in addressing the challenging task of synthetic-to-real domain adaptation, leading to improved neural surface reconstruction on real-world data.
GBlobs: Explicit Local Structure via Gaussian Blobs for Improved Cross-Domain LiDAR-based 3D Object Detection
Mar 11, 2025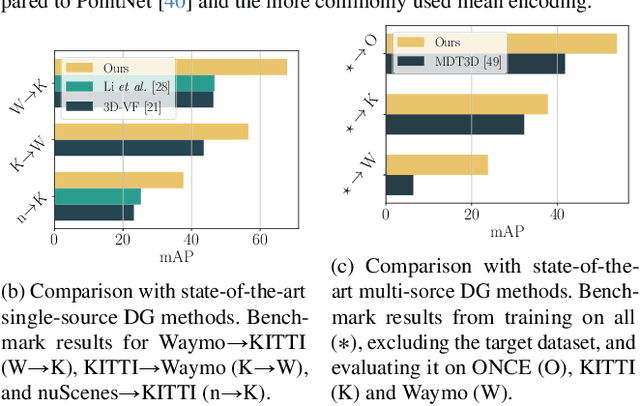
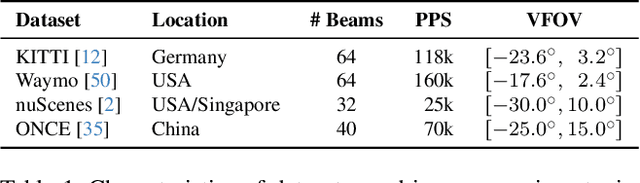
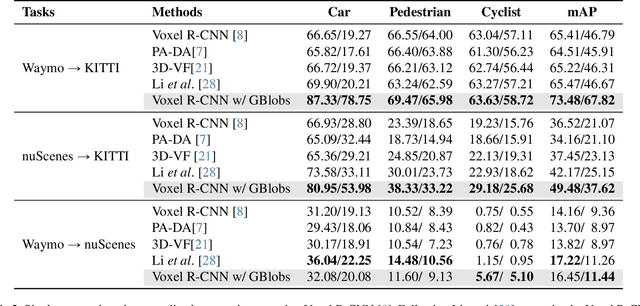
LiDAR-based 3D detectors need large datasets for training, yet they struggle to generalize to novel domains. Domain Generalization (DG) aims to mitigate this by training detectors that are invariant to such domain shifts. Current DG approaches exclusively rely on global geometric features (point cloud Cartesian coordinates) as input features. Over-reliance on these global geometric features can, however, cause 3D detectors to prioritize object location and absolute position, resulting in poor cross-domain performance. To mitigate this, we propose to exploit explicit local point cloud structure for DG, in particular by encoding point cloud neighborhoods with Gaussian blobs, GBlobs. Our proposed formulation is highly efficient and requires no additional parameters. Without any bells and whistles, simply by integrating GBlobs in existing detectors, we beat the current state-of-the-art in challenging single-source DG benchmarks by over 21 mAP (Waymo->KITTI), 13 mAP (KITTI->Waymo), and 12 mAP (nuScenes->KITTI), without sacrificing in-domain performance. Additionally, GBlobs demonstrate exceptional performance in multi-source DG, surpassing the current state-of-the-art by 17, 12, and 5 mAP on Waymo, KITTI, and ONCE, respectively.
Vision-Language Guidance for LiDAR-based Unsupervised 3D Object Detection
Aug 07, 2024
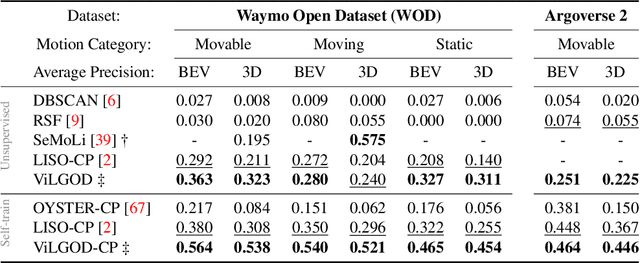
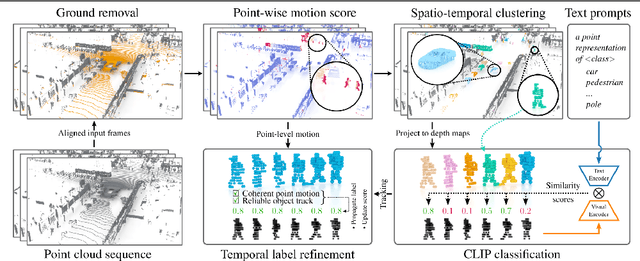
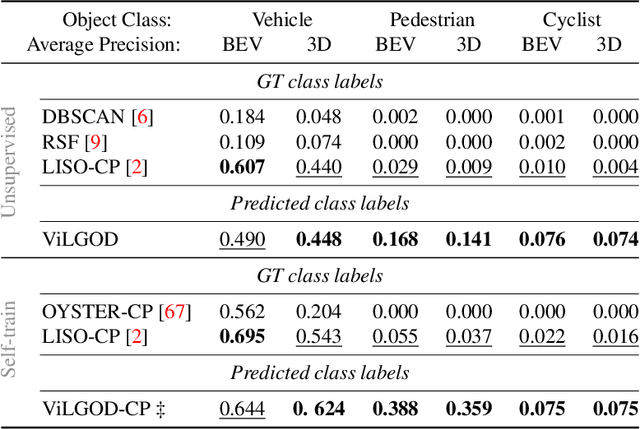
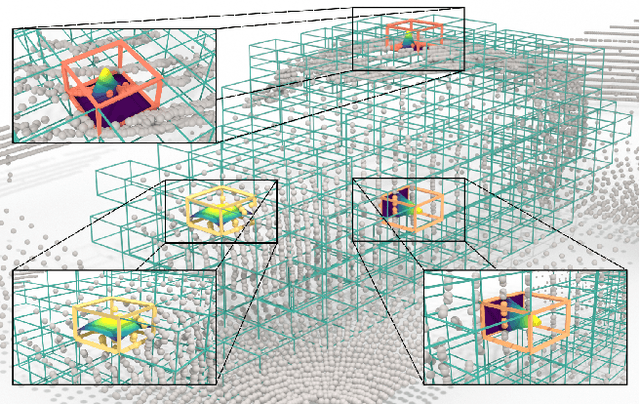
Accurate 3D object detection in LiDAR point clouds is crucial for autonomous driving systems. To achieve state-of-the-art performance, the supervised training of detectors requires large amounts of human-annotated data, which is expensive to obtain and restricted to predefined object categories. To mitigate manual labeling efforts, recent unsupervised object detection approaches generate class-agnostic pseudo-labels for moving objects, subsequently serving as supervision signal to bootstrap a detector. Despite promising results, these approaches do not provide class labels or generalize well to static objects. Furthermore, they are mostly restricted to data containing multiple drives from the same scene or images from a precisely calibrated and synchronized camera setup. To overcome these limitations, we propose a vision-language-guided unsupervised 3D detection approach that operates exclusively on LiDAR point clouds. We transfer CLIP knowledge to classify point clusters of static and moving objects, which we discover by exploiting the inherent spatio-temporal information of LiDAR point clouds for clustering, tracking, as well as box and label refinement. Our approach outperforms state-of-the-art unsupervised 3D object detectors on the Waymo Open Dataset ($+23~\text{AP}_{3D}$) and Argoverse 2 ($+7.9~\text{AP}_{3D}$) and provides class labels not solely based on object size assumptions, marking a significant advancement in the field.
SAILOR: Scaling Anchors via Insights into Latent Object Representation
Oct 17, 2022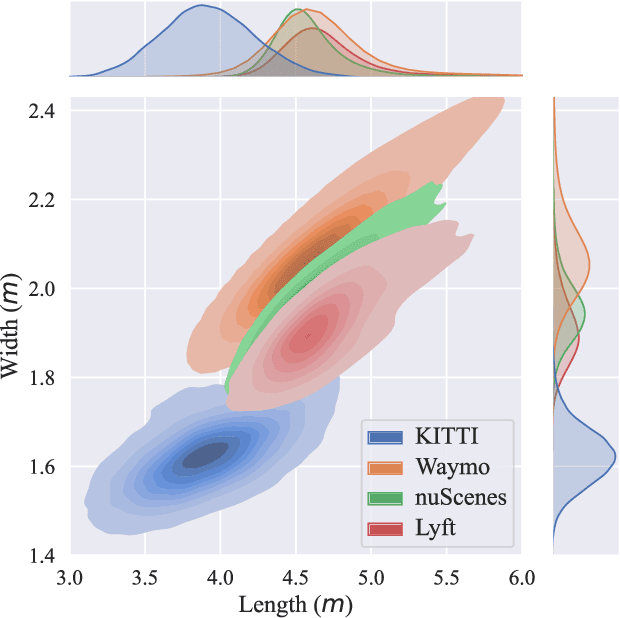

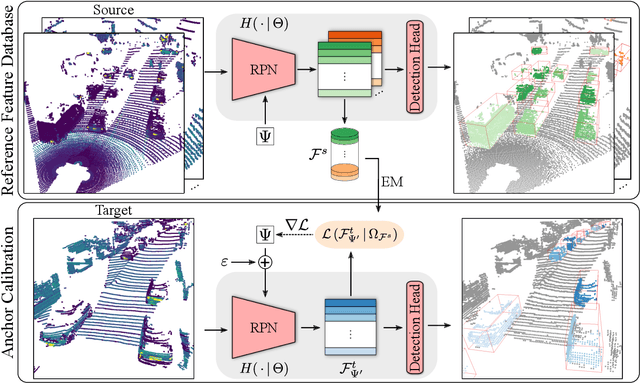
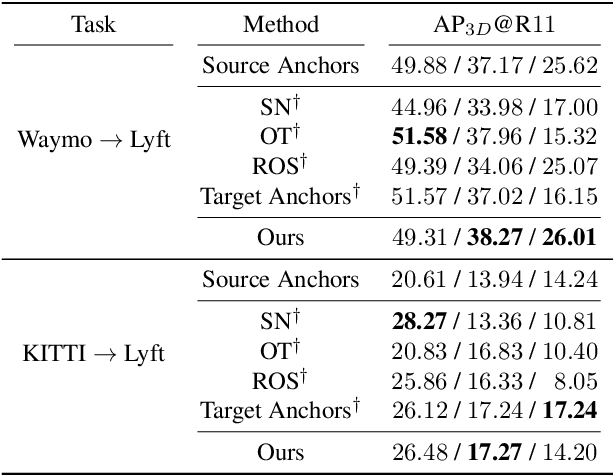
LiDAR 3D object detection models are inevitably biased towards their training dataset. The detector clearly exhibits this bias when employed on a target dataset, particularly towards object sizes. However, object sizes vary heavily between domains due to, for instance, different labeling policies or geographical locations. State-of-the-art unsupervised domain adaptation approaches outsource methods to overcome the object size bias. Mainstream size adaptation approaches exploit target domain statistics, contradicting the original unsupervised assumption. Our novel unsupervised anchor calibration method addresses this limitation. Given a model trained on the source data, we estimate the optimal target anchors in a completely unsupervised manner. The main idea stems from an intuitive observation: by varying the anchor sizes for the target domain, we inevitably introduce noise or even remove valuable object cues. The latent object representation, perturbed by the anchor size, is closest to the learned source features only under the optimal target anchors. We leverage this observation for anchor size optimization. Our experimental results show that, without any retraining, we achieve competitive results even compared to state-of-the-art weakly-supervised size adaptation approaches. In addition, our anchor calibration can be combined with such existing methods, making them completely unsupervised.