 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Guidance for LiDAR-based Unsupervised 3D Object Detection
Paper and Code

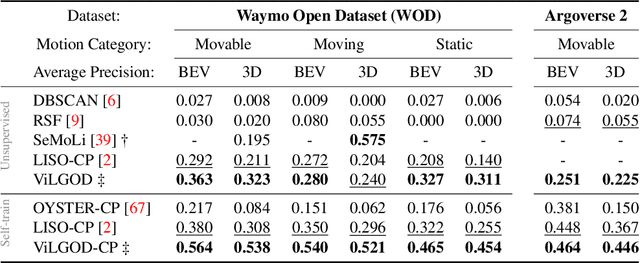
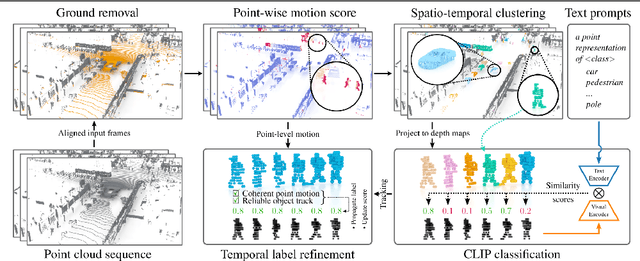
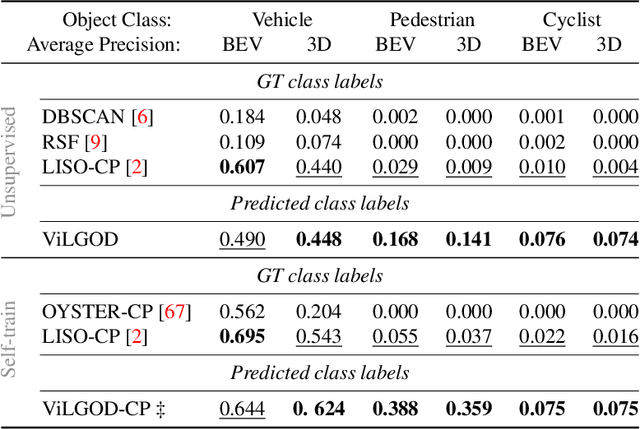
Accurate 3D object detection in LiDAR point clouds is crucial for autonomous driving systems. To achieve state-of-the-art performance, the supervised training of detectors requires large amounts of human-annotated data, which is expensive to obtain and restricted to predefined object categories. To mitigate manual labeling efforts, recent unsupervised object detection approaches generate class-agnostic pseudo-labels for moving objects, subsequently serving as supervision signal to bootstrap a detector. Despite promising results, these approaches do not provide class labels or generalize well to static objects. Furthermore, they are mostly restricted to data containing multiple drives from the same scene or images from a precisely calibrated and synchronized camera setup. To overcome these limitations, we propose a vision-language-guided unsupervised 3D detection approach that operates exclusively on LiDAR point clouds. We transfer CLIP knowledge to classify point clusters of static and moving objects, which we discover by exploiting the inherent spatio-temporal information of LiDAR point clouds for clustering, tracking, as well as box and label refinement. Our approach outperforms state-of-the-art unsupervised 3D object detectors on the Waymo Open Dataset ($+23~\text{AP}_{3D}$) and Argoverse 2 ($+7.9~\text{AP}_{3D}$) and provides class labels not solely based on object size assumptions, marking a significant advancement in the field.