 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridSDF: Combining Free Form Shapes and Geometric Primitives for effective Shape Manipulation
Sep 24, 2021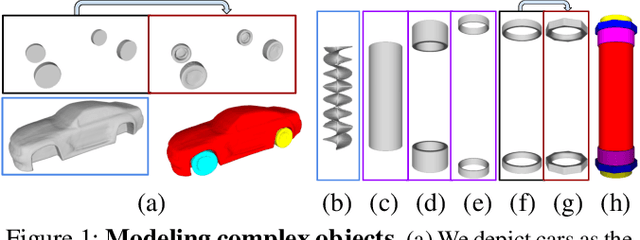
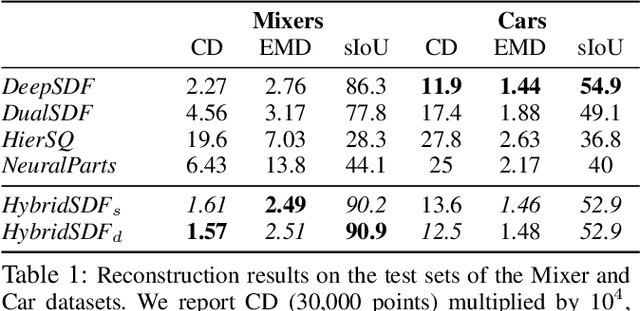
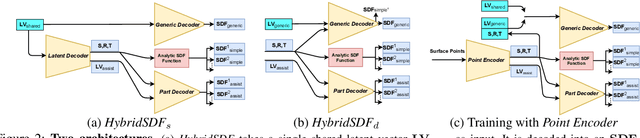
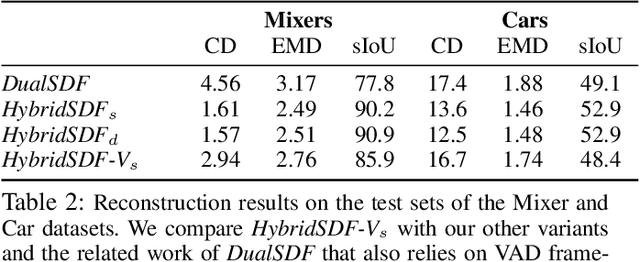
CAD modeling typically involves the use of simple geometric primitives whereas recent advances in deep-learning based 3D surface modeling have opened new shape design avenues. Unfortunately, these advances have not yet been accepted by the CAD community because they cannot be integrated into engineering workflows. To remedy this, we propose a novel approach to effectively combining geometric primitives and free-form surfaces represented by implicit surfaces for accurate modeling that preserves interpretability, enforces consistency, and enables easy manipulation.
TopoAL: An Adversarial Learning Approach for Topology-Aware Road Segmentation
Jul 17, 2020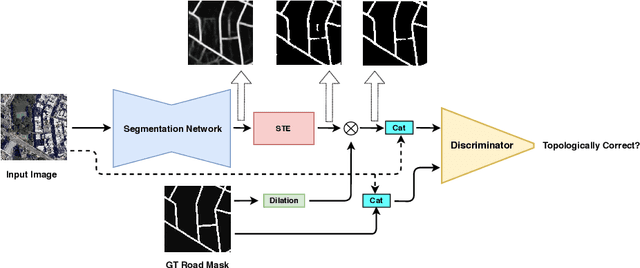



Most state-of-the-art approaches to road extraction from aerial images rely on a CNN trained to label road pixels as foreground and remainder of the image as background. The CNN is usually trained by minimizing pixel-wise losses, which is less than ideal to produce binary masks that preserve the road network's global connectivity. To address this issue, we introduce an Adversarial Learning (AL) strategy tailored for our purposes. A naive one would treat the segmentation network as a generator and would feed its output along with ground-truth segmentations to a discriminator. It would then train the generator and discriminator jointly. We will show that this is not enough because it does not capture the fact that most errors are local and need to be treated as such. Instead, we use a more sophisticated discriminator that returns a label pyramid describing what portions of the road network are correct at several different scales. This discriminator and the structured labels it returns are what gives our approach its edge and we will show that it outperforms state-of-the-art ones on the challenging RoadTracer dataset.
Planar Geometry and Latest Scene Recovery from a Single Motion Blurred Image
Apr 15, 2019



Existing works on motion deblurring either ignore the effects of depth-dependent blur or work with the assumption of a multi-layered scene wherein each layer is modeled in the form of fronto-parallel plane. In this work, we consider the case of 3D scenes with piecewise planar structure i.e., a scene that can be modeled as a combination of multiple planes with arbitrary orientations. We first propose an approach for estimation of normal of a planar scene from a single motion blurred observation. We then develop an algorithm for automatic recovery of a number of planes, the parameters corresponding to each plane, and camera motion from a single motion blurred image of a multiplanar 3D scene. Finally, we propose a first-of-its-kind approach to recover the planar geometry and latent image of the scene by adopting an alternating minimization framework built on our findings. Experiments on synthetic and real data reveal that our proposed method achieves state-of-the-art results.
Analyzing Perception-Distortion Tradeoff using Enhanced Perceptual Super-resolution Network
Nov 04, 2018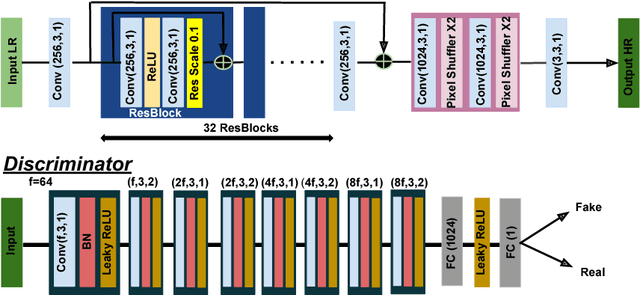
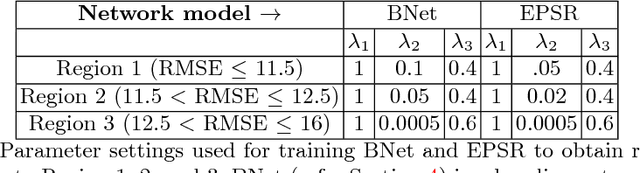
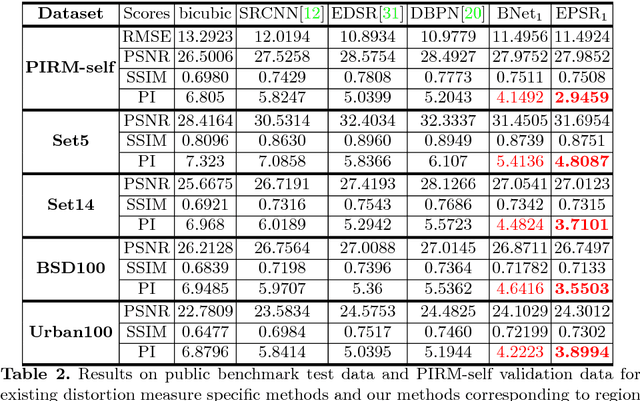

Convolutional neural network (CNN) based methods have recently achieved great success for image super-resolution (SR). However, most deep CNN based SR models attempt to improve distortion measures (e.g. PSNR, SSIM, IFC, VIF) while resulting in poor quantified perceptual quality (e.g. human opinion score, no-reference quality measures such as NIQE). Few works have attempted to improve the perceptual quality at the cost of performance reduction in distortion measures. A very recent study has revealed that distortion and perceptual quality are at odds with each other and there is always a trade-off between the two. Often the restoration algorithms that are superior in terms of perceptual quality, are inferior in terms of distortion measures. Our work attempts to analyze the trade-off between distortion and perceptual quality for the problem of single image SR. To this end, we use the well-known SR architecture-enhanced deep super-resolution (EDSR) network and show that it can be adapted to achieve better perceptual quality for a specific range of the distortion measure. While the original network of EDSR was trained to minimize the error defined based on per-pixel accuracy alone, we train our network using a generative adversarial network framework with EDSR as the generator module. Our proposed network, called enhanced perceptual super-resolution network (EPSR), is trained with a combination of mean squared error loss, perceptual loss, and adversarial loss. Our experiments reveal that EPSR achieves the state-of-the-art trade-off between distortion and perceptual quality while the existing methods perform well in either of these measures alone.
PIRM Challenge on Perceptual Image Enhancement on Smartphones: Report
Oct 03, 2018
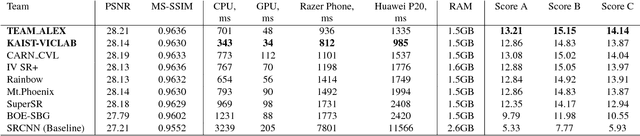

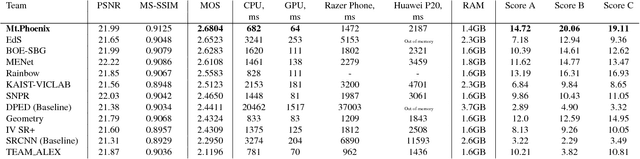
This paper reviews the first challenge on efficient perceptual image enhancement with the focus on deploying deep learning models on smartphones. The challenge consisted of two tracks. In the first one, participants were solving the classical image super-resolution problem with a bicubic downscaling factor of 4. The second track was aimed at real-world photo enhancement, and the goal was to map low-quality photos from the iPhone 3GS device to the same photos captured with a DSLR camera. The target metric used in this challenge combined the runtime, PSNR scores and solutions' perceptual results measured in the user study. To ensure the efficiency of the submitted models, we additionally measured their runtime and memory requirements on Android smartphones. The proposed solutions significantly improved baseline results defining the state-of-the-art for image enhancement on smartphones.