 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKSAFE-MM: A Multimodal Safety Benchmark via Localized Contextualization for Korean Cultural Risks
May 27, 2026Multimodal Large Language Models (MLLMs) exacerbate safety risks by introducing vulnerabilities across multiple modalities, such as language and vision. Current MLLM safety evaluation tools, however, suffer from major limitations: 1) English-centric dataset construction, and 2) a focus on generic risks that are not tied to local cultural contexts. This paper introduces KSAFE-MM, a benchmark for Korean multimodal safety evaluation that covers both general safety risks and culture-specific vulnerabilities. KSAFE-MM consists of two parts, KSAFE-MM-G and KSAFE-MM-C. KSAFE-MM-G evaluates globally shared risks in Korean contexts through linguistic contextualization, which transforms generic safety queries into contextually grounded multimodal samples. KSAFE-MM-C targets culture-dependent MLLM safety vulnerabilities using localized visual queries derived from real-world contexts. It pairs these visual queries with jailbreak-style textual queries to cover multimodal safety risks involving cultural visual cues and malicious textual intent. Together, these components provide a general-to-local construction pipeline for evaluating both globally shared safety risks and culture-specific vulnerabilities. We evaluate 12 state-of-the-art MLLMs on KSAFE-MM and reveal that models exhibit greater vulnerability to culturally grounded attacks than to generic ones. Notably, jailbreaking strategies substantially amplify attack success rates, with ProgramExecution yielding up to 74.2% ASR compared to 13.4% for standard queries. Furthermore, we identify a systematic trade-off between safety and over-refusal, where models achieving low ASR tend to exhibit excessive refusal behavior on benign queries. These findings highlight the urgent need for culturally grounded safety evaluation beyond English-centric benchmarks.
Consistency-Preserving Concept Erasure via Unsafe-Safe Pairing and Directional Fisher-weighted Adaptation
Feb 05, 2026With the increasing versatility of text-to-image diffusion models, the ability to selectively erase undesirable concepts (e.g., harmful content) has become indispensable. However, existing concept erasure approaches primarily focus on removing unsafe concepts without providing guidance toward corresponding safe alternatives, which often leads to failure in preserving the structural and semantic consistency between the original and erased generations. In this paper, we propose a novel framework, PAIRed Erasing (PAIR), which reframes concept erasure from simple removal to consistency-preserving semantic realignment using unsafe-safe pairs. We first generate safe counterparts from unsafe inputs while preserving structural and semantic fidelity, forming paired unsafe-safe multimodal data. Leveraging these pairs, we introduce two key components: (1) Paired Semantic Realignment, a guided objective that uses unsafe-safe pairs to explicitly map target concepts to semantically aligned safe anchors; and (2) Fisher-weighted Initialization for DoRA, which initializes parameter-efficient low-rank adaptation matrices using unsafe-safe pairs, encouraging the generation of safe alternatives while selectively suppressing unsafe concepts. Together, these components enable fine-grained erasure that removes only the targeted concepts while maintaining overall semantic consistency. Extensive experiments demonstrate that our approach significantly outperforms state-of-the-art baselines, achieving effective concept erasure while preserving structural integrity, semantic coherence, and generation quality.
Erase at the Core: Representation Unlearning for Machine Unlearning
Feb 05, 2026Many approximate machine unlearning methods demonstrate strong logit-level forgetting -- such as near-zero accuracy on the forget set -- yet continue to preserve substantial information within their internal feature representations. We refer to this discrepancy as superficial forgetting. Recent studies indicate that most existing unlearning approaches primarily alter the final classifier, leaving intermediate representations largely unchanged and highly similar to those of the original model. To address this limitation, we introduce the Erase at the Core (EC), a framework designed to enforce forgetting throughout the entire network hierarchy. EC integrates multi-layer contrastive unlearning on the forget set with retain set preservation through deeply supervised learning. Concretely, EC attaches auxiliary modules to intermediate layers and applies both contrastive unlearning and cross-entropy losses at each supervision point, with layer-wise weighted losses. Experimental results show that EC not only achieves effective logit-level forgetting, but also substantially reduces representational similarity to the original model across intermediate layers. Furthermore, EC is model-agnostic and can be incorporated as a plug-in module into existing unlearning methods, improving representation-level forgetting while maintaining performance on the retain set.
Are We Truly Forgetting? A Critical Re-examination of Machine Unlearning Evaluation Protocols
Mar 10, 2025



Machine unlearning is a process to remove specific data points from a trained model while maintaining the performance on retain data, addressing privacy or legal requirements. Despite its importance, existing unlearning evaluations tend to focus on logit-based metrics (i.e., accuracy) under small-scale scenarios. We observe that this could lead to a false sense of security in unlearning approaches under real-world scenarios. In this paper, we conduct a new comprehensive evaluation that employs representation-based evaluations of the unlearned model under large-scale scenarios to verify whether the unlearning approaches genuinely eliminate the targeted forget data from the model's representation perspective. Our analysis reveals that current state-of-the-art unlearning approaches either completely degrade the representational quality of the unlearned model or merely modify the classifier (i.e., the last layer), thereby achieving superior logit-based evaluation metrics while maintaining significant representational similarity to the original model. Furthermore, we introduce a novel unlearning evaluation setup from a transfer learning perspective, in which the forget set classes exhibit semantic similarity to downstream task classes, necessitating that feature representations diverge significantly from those of the original model. Our comprehensive benchmark not only addresses a critical gap between theoretical machine unlearning and practical scenarios, but also establishes a foundation to inspire future research directions in developing genuinely effective unlearning methodologies.
Multi-Attention Based Ultra Lightweight Image Super-Resolution
Sep 21, 2020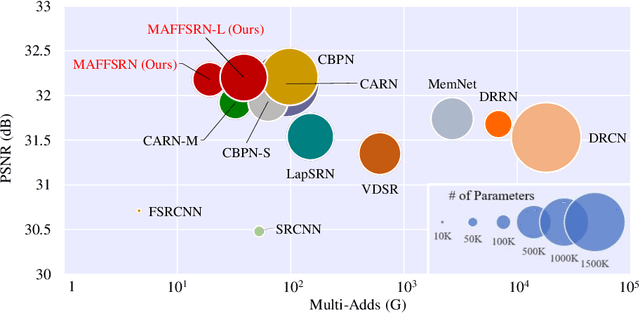
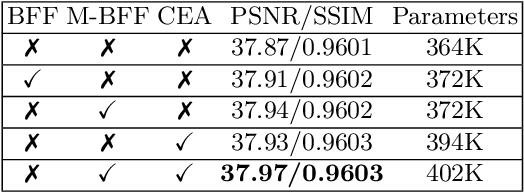
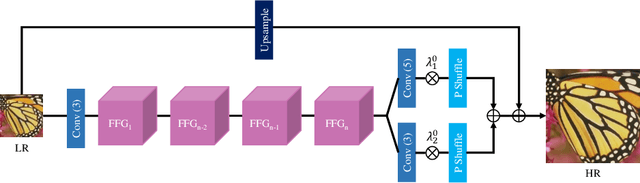

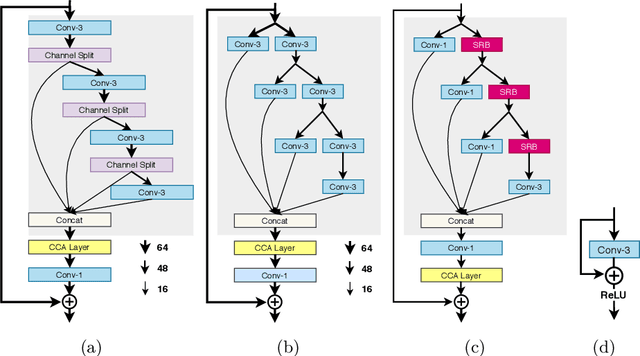
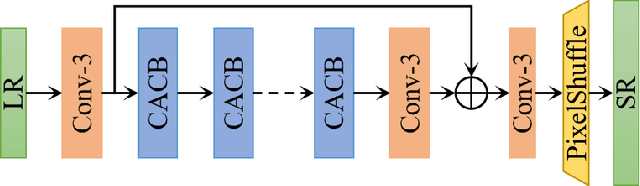
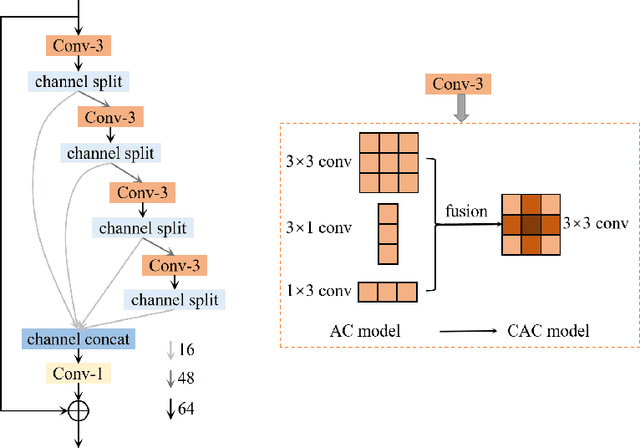
Lightweight image super-resolution (SR) networks have the utmost significance for real-world applications. There are several deep learning based SR methods with remarkable performance, but their memory and computational cost are hindrances in practical usage. To tackle this problem, we propose a Multi-Attentive Feature Fusion Super-Resolution Network (MAFFSRN). MAFFSRN consists of proposed feature fusion groups (FFGs) that serve as a feature extraction block. Each FFG contains a stack of proposed multi-attention blocks (MAB) that are combined in a novel feature fusion structure. Further, the MAB with a cost-efficient attention mechanism (CEA) helps us to refine and extract the features using multiple attention mechanisms. The comprehensive experiments show the superiority of our model over the existing state-of-the-art. We participated in AIM 2020 efficient SR challenge with our MAFFSRN model and won 1st, 3rd, and 4th places in memory usage, floating-point operations (FLOPs) and number of parameters, respectively.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020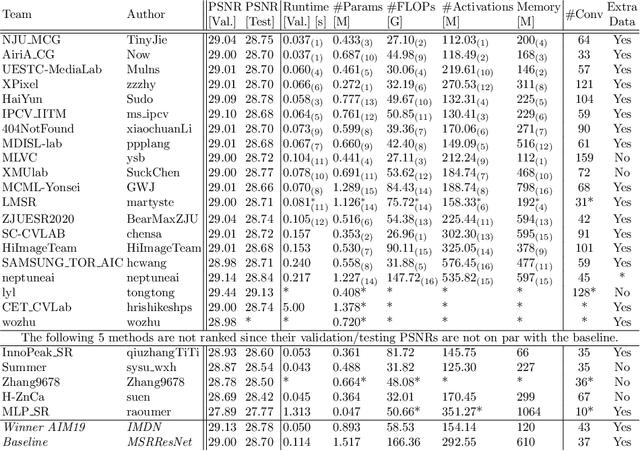
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
S3: A Spectral-Spatial Structure Loss for Pan-Sharpening Networks
Jun 13, 2019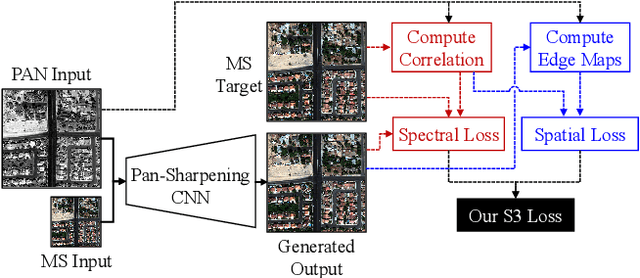



Recently, many deep-learning-based pan-sharpening methods have been proposed for generating high-quality pan-sharpened (PS) satellite images. These methods focused on various types of convolutional neural network (CNN) structures, which were trained by simply minimizing L1 or L2 losses between network outputs and the corresponding high-resolution multi-spectral (MS) target images. However, due to different sensor characteristics and acquisition times, high-resolution panchromatic (PAN) and low-resolution MS image pairs tend to have large pixel misalignments, especially for moving objects in the images. Conventional CNNs trained with L1 or L2 losses with these satellite image datasets often produce PS images of low visual quality including double-edge artifacts along strong edges and ghosting artifacts on moving objects. In this letter, we propose a novel loss function, called a spectral-spatial structure (S3) loss, based on the correlation maps between MS targets and PAN inputs. Our proposed S3 loss can be very effectively utilized for pan-sharpening with various types of CNN structures, resulting in significant visual improvements on PS images with suppressed artifacts.
PIRM Challenge on Perceptual Image Enhancement on Smartphones: Report
Oct 03, 2018
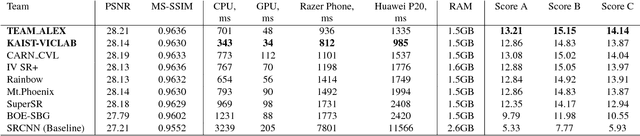

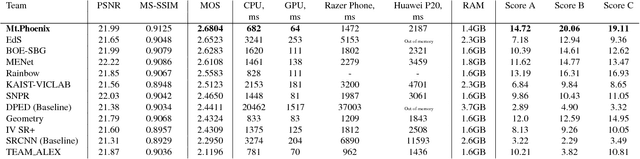
This paper reviews the first challenge on efficient perceptual image enhancement with the focus on deploying deep learning models on smartphones. The challenge consisted of two tracks. In the first one, participants were solving the classical image super-resolution problem with a bicubic downscaling factor of 4. The second track was aimed at real-world photo enhancement, and the goal was to map low-quality photos from the iPhone 3GS device to the same photos captured with a DSLR camera. The target metric used in this challenge combined the runtime, PSNR scores and solutions' perceptual results measured in the user study. To ensure the efficiency of the submitted models, we additionally measured their runtime and memory requirements on Android smartphones. The proposed solutions significantly improved baseline results defining the state-of-the-art for image enhancement on smartphones.