 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToonAging: Face Re-Aging upon Artistic Portrait Style Transfer
Feb 05, 2024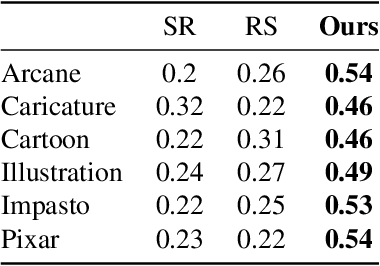

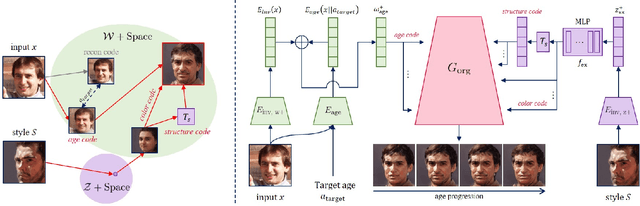
Face re-aging is a prominent field in computer vision and graphics, with significant applications in photorealistic domains such as movies, advertising, and live streaming. Recently, the need to apply face re-aging to non-photorealistic images, like comics, illustrations, and animations, has emerged as an extension in various entertainment sectors. However, the absence of a network capable of seamlessly editing the apparent age on NPR images means that these tasks have been confined to a naive approach, applying each task sequentially. This often results in unpleasant artifacts and a loss of facial attributes due to domain discrepancies. In this paper, we introduce a novel one-stage method for face re-aging combined with portrait style transfer, executed in a single generative step. We leverage existing face re-aging and style transfer networks, both trained within the same PR domain. Our method uniquely fuses distinct latent vectors, each responsible for managing aging-related attributes and NPR appearance. Adopting an exemplar-based approach, our method offers greater flexibility than domain-level fine-tuning approaches, which typically require separate training or fine-tuning for each domain. This effectively addresses the limitation of requiring paired datasets for re-aging and domain-level, data-driven approaches for stylization. Our experiments show that our model can effortlessly generate re-aged images while simultaneously transferring the style of examples, maintaining both natural appearance and controllability.
Video Face Re-Aging: Toward Temporally Consistent Face Re-Aging
Dec 07, 2023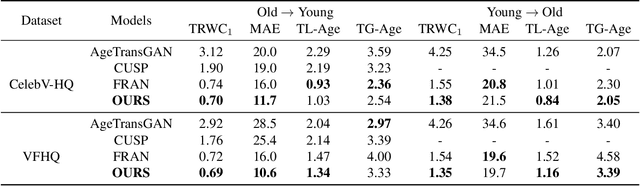
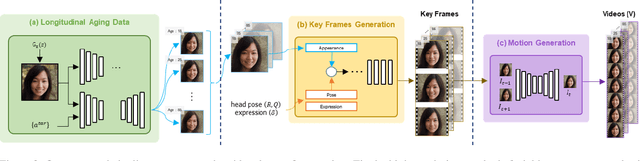
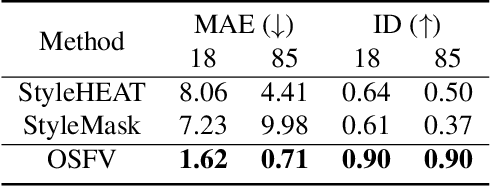
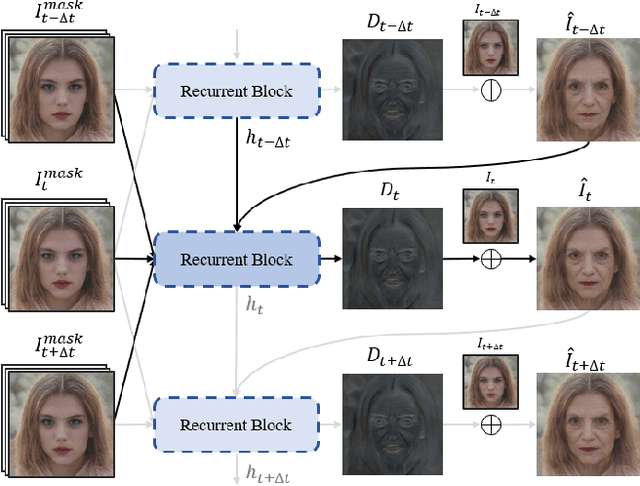
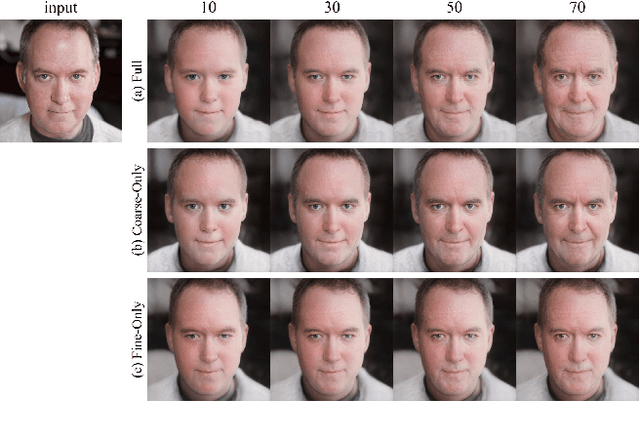
Video face re-aging deals with altering the apparent age of a person to the target age in videos. This problem is challenging due to the lack of paired video datasets maintaining temporal consistency in identity and age. Most re-aging methods process each image individually without considering the temporal consistency of videos. While some existing works address the issue of temporal coherence through video facial attribute manipulation in latent space, they often fail to deliver satisfactory performance in age transformation. To tackle the issues, we propose (1) a novel synthetic video dataset that features subjects across a diverse range of age groups; (2) a baseline architecture designed to validate the effectiveness of our proposed dataset, and (3) the development of three novel metrics tailored explicitly for evaluating the temporal consistency of video re-aging techniques. Our comprehensive experiments on public datasets, such as VFHQ and CelebV-HQ, show that our method outperforms the existing approaches in terms of both age transformation and temporal consistency.
Multi-Attention Based Ultra Lightweight Image Super-Resolution
Sep 21, 2020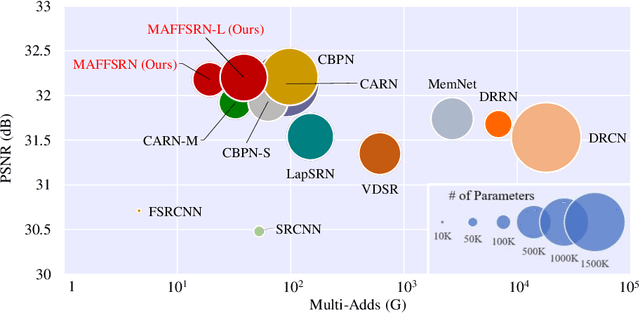
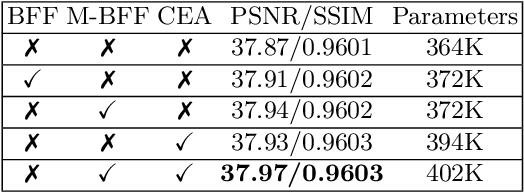
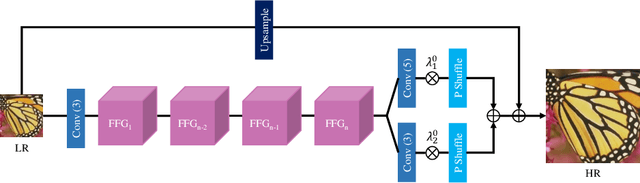

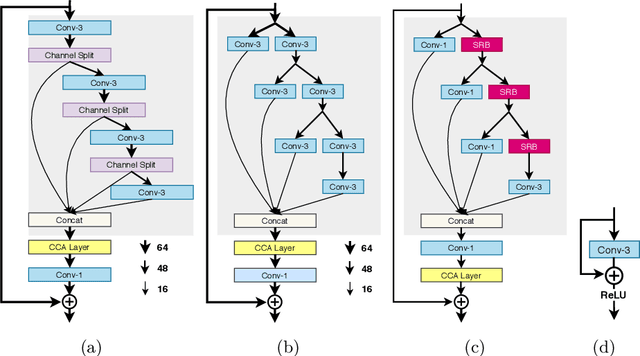
Lightweight image super-resolution (SR) networks have the utmost significance for real-world applications. There are several deep learning based SR methods with remarkable performance, but their memory and computational cost are hindrances in practical usage. To tackle this problem, we propose a Multi-Attentive Feature Fusion Super-Resolution Network (MAFFSRN). MAFFSRN consists of proposed feature fusion groups (FFGs) that serve as a feature extraction block. Each FFG contains a stack of proposed multi-attention blocks (MAB) that are combined in a novel feature fusion structure. Further, the MAB with a cost-efficient attention mechanism (CEA) helps us to refine and extract the features using multiple attention mechanisms. The comprehensive experiments show the superiority of our model over the existing state-of-the-art. We participated in AIM 2020 efficient SR challenge with our MAFFSRN model and won 1st, 3rd, and 4th places in memory usage, floating-point operations (FLOPs) and number of parameters, respectively.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020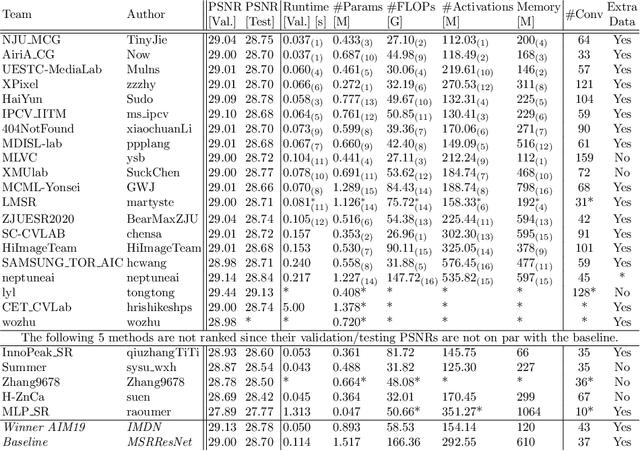
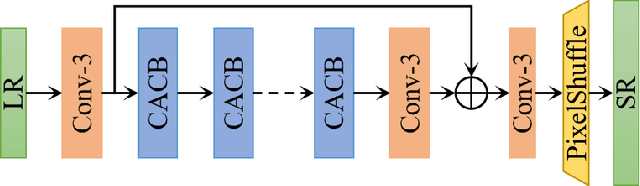
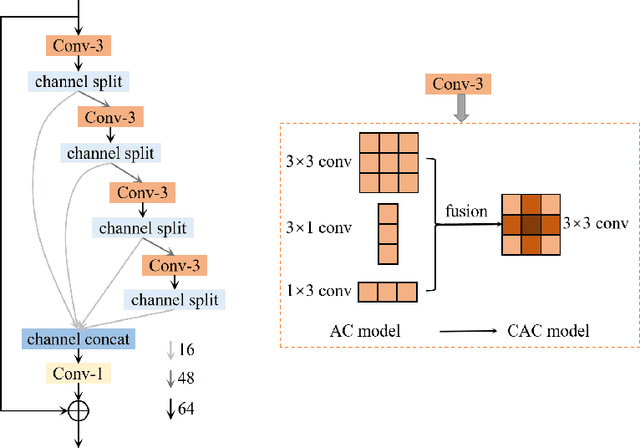
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
A Novel Image Dehazing and Assessment Method
Jan 20, 2020



Images captured in hazy weather conditions often suffer from color contrast and color fidelity. This degradation is represented by transmission map which represents the amount of attenuation and airlight which represents the color of additive noise. In this paper, we have proposed a method to estimate the transmission map using haze levels instead of airlight color since there are some ambiguities in estimation of airlight. Qualitative and quantitative results of proposed method show competitiveness of the method given. In addition we have proposed two metrics which are based on statistics of natural outdoor images for assessment of haze removal algorithms.
Hybrid Residual Attention Network for Single Image Super Resolution
Jul 11, 2019
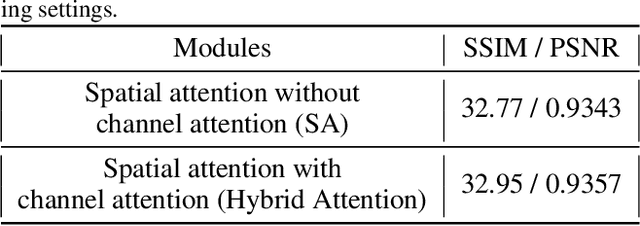


The extraction and proper utilization of convolution neural network (CNN) features have a significant impact on the performance of image super-resolution (SR). Although CNN features contain both the spatial and channel information, current deep techniques on SR often suffer to maximize performance due to using either the spatial or channel information. Moreover, they integrate such information within a deep or wide network rather than exploiting all the available features, eventually resulting in high computational complexity. To address these issues, we present a binarized feature fusion (BFF) structure that utilizes the extracted features from residual groups (RG) in an effective way. Each residual group (RG) consists of multiple hybrid residual attention blocks (HRAB) that effectively integrates the multiscale feature extraction module and channel attention mechanism in a single block. Furthermore, we use dilated convolutions with different dilation factors to extract multiscale features. We also propose to adopt global, short and long skip connections and residual groups (RG) structure to ease the flow of information without losing important features details. In the paper, we call this overall network architecture as hybrid residual attention network (HRAN). In the experiment, we have observed the efficacy of our method against the state-of-the-art methods for both the quantitative and qualitative comparisons.