 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAck: Semantic, Location, and Appearance Aware Open-Vocabulary Tracking
Sep 17, 2024
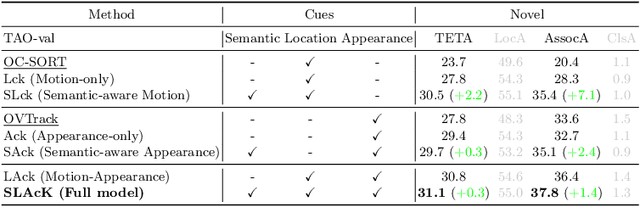
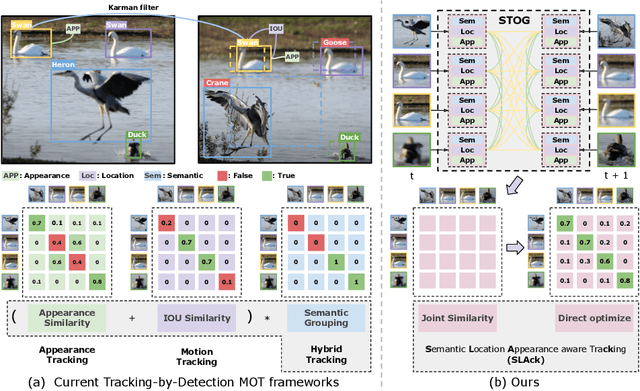

Open-vocabulary Multiple Object Tracking (MOT) aims to generalize trackers to novel categories not in the training set. Currently, the best-performing methods are mainly based on pure appearance matching. Due to the complexity of motion patterns in the large-vocabulary scenarios and unstable classification of the novel objects, the motion and semantics cues are either ignored or applied based on heuristics in the final matching steps by existing methods. In this paper, we present a unified framework SLAck that jointly considers semantics, location, and appearance priors in the early steps of association and learns how to integrate all valuable information through a lightweight spatial and temporal object graph. Our method eliminates complex post-processing heuristics for fusing different cues and boosts the association performance significantly for large-scale open-vocabulary tracking. Without bells and whistles, we outperform previous state-of-the-art methods for novel classes tracking on the open-vocabulary MOT and TAO TETA benchmarks. Our code is available at \href{https://github.com/siyuanliii/SLAck}{github.com/siyuanliii/SLAck}.
PIV3CAMS: a multi-camera dataset for multiple computer vision problems and its application to novel view-point synthesis
Jul 26, 2024



The modern approaches for computer vision tasks significantly rely on machine learning, which requires a large number of quality images. While there is a plethora of image datasets with a single type of images, there is a lack of datasets collected from multiple cameras. In this thesis, we introduce Paired Image and Video data from three CAMeraS, namely PIV3CAMS, aimed at multiple computer vision tasks. The PIV3CAMS dataset consists of 8385 pairs of images and 82 pairs of videos taken from three different cameras: Canon D5 Mark IV, Huawei P20, and ZED stereo camera. The dataset includes various indoor and outdoor scenes from different locations in Zurich (Switzerland) and Cheonan (South Korea). Some of the computer vision applications that can benefit from the PIV3CAMS dataset are image/video enhancement, view interpolation, image matching, and much more. We provide a careful explanation of the data collection process and detailed analysis of the data. The second part of this thesis studies the usage of depth information in the view synthesizing task. In addition to the regeneration of a current state-of-the-art algorithm, we investigate several proposed alternative models that integrate depth information geometrically. Through extensive experiments, we show that the effect of depth is crucial in small view changes. Finally, we apply our model to the introduced PIV3CAMS dataset to synthesize novel target views as an example application of PIV3CAMS.
Matching Anything by Segmenting Anything
Jun 06, 2024



The robust association of the same objects across video frames in complex scenes is crucial for many applications, especially Multiple Object Tracking (MOT). Current methods predominantly rely on labeled domain-specific video datasets, which limits the cross-domain generalization of learned similarity embeddings. We propose MASA, a novel method for robust instance association learning, capable of matching any objects within videos across diverse domains without tracking labels. Leveraging the rich object segmentation from the Segment Anything Model (SAM), MASA learns instance-level correspondence through exhaustive data transformations. We treat the SAM outputs as dense object region proposals and learn to match those regions from a vast image collection. We further design a universal MASA adapter which can work in tandem with foundational segmentation or detection models and enable them to track any detected objects. Those combinations present strong zero-shot tracking ability in complex domains. Extensive tests on multiple challenging MOT and MOTS benchmarks indicate that the proposed method, using only unlabeled static images, achieves even better performance than state-of-the-art methods trained with fully annotated in-domain video sequences, in zero-shot association. Project Page: https://matchinganything.github.io/
Efficient Video Object Segmentation via Modulated Cross-Attention Memory
Mar 26, 2024



Recently, transformer-based approaches have shown promising results for semi-supervised video object segmentation. However, these approaches typically struggle on long videos due to increased GPU memory demands, as they frequently expand the memory bank every few frames. We propose a transformer-based approach, named MAVOS, that introduces an optimized and dynamic long-term modulated cross-attention (MCA) memory to model temporal smoothness without requiring frequent memory expansion. The proposed MCA effectively encodes both local and global features at various levels of granularity while efficiently maintaining consistent speed regardless of the video length. Extensive experiments on multiple benchmarks, LVOS, Long-Time Video, and DAVIS 2017, demonstrate the effectiveness of our proposed contributions leading to real-time inference and markedly reduced memory demands without any degradation in segmentation accuracy on long videos. Compared to the best existing transformer-based approach, our MAVOS increases the speed by 7.6x, while significantly reducing the GPU memory by 87% with comparable segmentation performance on short and long video datasets. Notably on the LVOS dataset, our MAVOS achieves a J&F score of 63.3% while operating at 37 frames per second (FPS) on a single V100 GPU. Our code and models will be publicly available at: https://github.com/Amshaker/MAVOS.
Analyzing Local Representations of Self-supervised Vision Transformers
Dec 31, 2023



In this paper, we present a comparative analysis of various self-supervised Vision Transformers (ViTs), focusing on their local representative power. Inspired by large language models, we examine the abilities of ViTs to perform various computer vision tasks with little to no fine-tuning. We design an evaluation framework to analyze the quality of local, i.e. patch-level, representations in the context of few-shot semantic segmentation, instance identification, object retrieval, and tracking. We discover that contrastive learning based methods like DINO produce more universal patch representations that can be immediately applied for downstream tasks with no parameter tuning, compared to masked image modeling. The embeddings learned using the latter approach, e.g. in masked autoencoders, have high variance features that harm distance-based algorithms, such as k-NN, and do not contain useful information for most downstream tasks. Furthermore, we demonstrate that removing these high-variance features enhances k-NN by providing an analysis of the benchmarks for this work and for Scale-MAE, a recent extension of masked autoencoders. Finally, we find an object instance retrieval setting where DINOv2, a model pretrained on two orders of magnitude more data, performs worse than its less compute-intensive counterpart DINO.
Diffusion-Based Particle-DETR for BEV Perception
Dec 18, 2023



The Bird-Eye-View (BEV) is one of the most widely-used scene representations for visual perception in Autonomous Vehicles (AVs) due to its well suited compatibility to downstream tasks. For the enhanced safety of AVs, modeling perception uncertainty in BEV is crucial. Recent diffusion-based methods offer a promising approach to uncertainty modeling for visual perception but fail to effectively detect small objects in the large coverage of the BEV. Such degradation of performance can be attributed primarily to the specific network architectures and the matching strategy used when training. Here, we address this problem by combining the diffusion paradigm with current state-of-the-art 3D object detectors in BEV. We analyze the unique challenges of this approach, which do not exist with deterministic detectors, and present a simple technique based on object query interpolation that allows the model to learn positional dependencies even in the presence of the diffusion noise. Based on this, we present a diffusion-based DETR model for object detection that bears similarities to particle methods. Abundant experimentation on the NuScenes dataset shows equal or better performance for our generative approach, compared to deterministic state-of-the-art methods. Our source code will be made publicly available.
Gaussian Grouping: Segment and Edit Anything in 3D Scenes
Dec 01, 2023
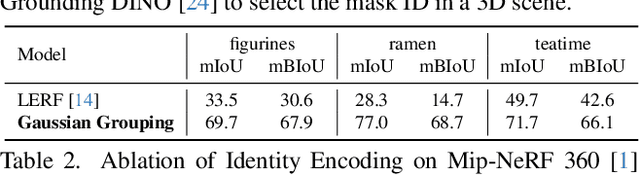


The recent Gaussian Splatting achieves high-quality and real-time novel-view synthesis of the 3D scenes. However, it is solely concentrated on the appearance and geometry modeling, while lacking in fine-grained object-level scene understanding. To address this issue, we propose Gaussian Grouping, which extends Gaussian Splatting to jointly reconstruct and segment anything in open-world 3D scenes. We augment each Gaussian with a compact Identity Encoding, allowing the Gaussians to be grouped according to their object instance or stuff membership in the 3D scene. Instead of resorting to expensive 3D labels, we supervise the Identity Encodings during the differentiable rendering by leveraging the 2D mask predictions by SAM, along with introduced 3D spatial consistency regularization. Comparing to the implicit NeRF representation, we show that the discrete and grouped 3D Gaussians can reconstruct, segment and edit anything in 3D with high visual quality, fine granularity and efficiency. Based on Gaussian Grouping, we further propose a local Gaussian Editing scheme, which shows efficacy in versatile scene editing applications, including 3D object removal, inpainting, colorization and scene recomposition. Our code and models will be at https://github.com/lkeab/gaussian-grouping.
Probabilistic Sampling of Balanced K-Means using Adiabatic Quantum Computing
Oct 18, 2023



Adiabatic quantum computing (AQC) is a promising quantum computing approach for discrete and often NP-hard optimization problems. Current AQCs allow to implement problems of research interest, which has sparked the development of quantum representations for many machine learning and computer vision tasks. Despite requiring multiple measurements from the noisy AQC, current approaches only utilize the best measurement, discarding information contained in the remaining ones. In this work, we explore the potential of using this information for probabilistic balanced k-means clustering. Instead of discarding non-optimal solutions, we propose to use them to compute calibrated posterior probabilities with little additional compute cost. This allows us to identify ambiguous solutions and data points, which we demonstrate on a D-Wave AQC on synthetic and real data.
R3D3: Dense 3D Reconstruction of Dynamic Scenes from Multiple Cameras
Aug 28, 2023



Dense 3D reconstruction and ego-motion estimation are key challenges in autonomous driving and robotics. Compared to the complex, multi-modal systems deployed today, multi-camera systems provide a simpler, low-cost alternative. However, camera-based 3D reconstruction of complex dynamic scenes has proven extremely difficult, as existing solutions often produce incomplete or incoherent results. We propose R3D3, a multi-camera system for dense 3D reconstruction and ego-motion estimation. Our approach iterates between geometric estimation that exploits spatial-temporal information from multiple cameras, and monocular depth refinement. We integrate multi-camera feature correlation and dense bundle adjustment operators that yield robust geometric depth and pose estimates. To improve reconstruction where geometric depth is unreliable, e.g. for moving objects or low-textured regions, we introduce learnable scene priors via a depth refinement network. We show that this design enables a dense, consistent 3D reconstruction of challenging, dynamic outdoor environments. Consequently, we achieve state-of-the-art dense depth prediction on the DDAD and NuScenes benchmarks.
MolGrapher: Graph-based Visual Recognition of Chemical Structures
Aug 23, 2023The automatic analysis of chemical literature has immense potential to accelerate the discovery of new materials and drugs. Much of the critical information in patent documents and scientific articles is contained in figures, depicting the molecule structures. However, automatically parsing the exact chemical structure is a formidable challenge, due to the amount of detailed information, the diversity of drawing styles, and the need for training data. In this work, we introduce MolGrapher to recognize chemical structures visually. First, a deep keypoint detector detects the atoms. Second, we treat all candidate atoms and bonds as nodes and put them in a graph. This construct allows a natural graph representation of the molecule. Last, we classify atom and bond nodes in the graph with a Graph Neural Network. To address the lack of real training data, we propose a synthetic data generation pipeline producing diverse and realistic results. In addition, we introduce a large-scale benchmark of annotated real molecule images, USPTO-30K, to spur research on this critical topic. Extensive experiments on five datasets show that our approach significantly outperforms classical and learning-based methods in most settings. Code, models, and datasets are available.