 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
ConceptPose: Training-Free Zero-Shot Object Pose Estimation using Concept Vectors
Dec 19, 2025Object pose estimation is a fundamental task in computer vision and robotics, yet most methods require extensive, dataset-specific training. Concurrently, large-scale vision language models show remarkable zero-shot capabilities. In this work, we bridge these two worlds by introducing ConceptPose, a framework for object pose estimation that is both training-free and model-free. ConceptPose leverages a vision-language-model (VLM) to create open-vocabulary 3D concept maps, where each point is tagged with a concept vector derived from saliency maps. By establishing robust 3D-3D correspondences across concept maps, our approach allows precise estimation of 6DoF relative pose. Without any object or dataset-specific training, our approach achieves state-of-the-art results on common zero shot relative pose estimation benchmarks, significantly outperforming existing methods by over 62% in ADD(-S) score, including those that utilize extensive dataset-specific training.
Autonomous Vehicle Path Planning by Searching With Differentiable Simulation
Nov 14, 2025



Planning allows an agent to safely refine its actions before executing them in the real world. In autonomous driving, this is crucial to avoid collisions and navigate in complex, dense traffic scenarios. One way to plan is to search for the best action sequence. However, this is challenging when all necessary components - policy, next-state predictor, and critic - have to be learned. Here we propose Differentiable Simulation for Search (DSS), a framework that leverages the differentiable simulator Waymax as both a next state predictor and a critic. It relies on the simulator's hardcoded dynamics, making state predictions highly accurate, while utilizing the simulator's differentiability to effectively search across action sequences. Our DSS agent optimizes its actions using gradient descent over imagined future trajectories. We show experimentally that DSS - the combination of planning gradients and stochastic search - significantly improves tracking and path planning accuracy compared to sequence prediction, imitation learning, model-free RL, and other planning methods.
From Scan to Action: Leveraging Realistic Scans for Embodied Scene Understanding
Jul 23, 2025Real-world 3D scene-level scans offer realism and can enable better real-world generalizability for downstream applications. However, challenges such as data volume, diverse annotation formats, and tool compatibility limit their use. This paper demonstrates a methodology to effectively leverage these scans and their annotations. We propose a unified annotation integration using USD, with application-specific USD flavors. We identify challenges in utilizing holistic real-world scan datasets and present mitigation strategies. The efficacy of our approach is demonstrated through two downstream applications: LLM-based scene editing, enabling effective LLM understanding and adaptation of the data (80% success), and robotic simulation, achieving an 87% success rate in policy learning.
GaussianVLM: Scene-centric 3D Vision-Language Models using Language-aligned Gaussian Splats for Embodied Reasoning and Beyond
Jul 01, 2025As multimodal language models advance, their application to 3D scene understanding is a fast-growing frontier, driving the development of 3D Vision-Language Models (VLMs). Current methods show strong dependence on object detectors, introducing processing bottlenecks and limitations in taxonomic flexibility. To address these limitations, we propose a scene-centric 3D VLM for 3D Gaussian splat scenes that employs language- and task-aware scene representations. Our approach directly embeds rich linguistic features into the 3D scene representation by associating language with each Gaussian primitive, achieving early modality alignment. To process the resulting dense representations, we introduce a dual sparsifier that distills them into compact, task-relevant tokens via task-guided and location-guided pathways, producing sparse, task-aware global and local scene tokens. Notably, we present the first Gaussian splatting-based VLM, leveraging photorealistic 3D representations derived from standard RGB images, demonstrating strong generalization: it improves performance of prior 3D VLM five folds, in out-of-the-domain settings.
Small-Scale Testbeds for Connected and Automated Vehicles and Robot Swarms: Challenges and a Roadmap
Mar 07, 2025This article proposes a roadmap to address the current challenges in small-scale testbeds for Connected and Automated Vehicles (CAVs) and robot swarms. The roadmap is a joint effort of participants in the workshop "1st Workshop on Small-Scale Testbeds for Connected and Automated Vehicles and Robot Swarms," held on June 2 at the IEEE Intelligent Vehicles Symposium (IV) 2024 in Jeju, South Korea. The roadmap contains three parts: 1) enhancing accessibility and diversity, especially for underrepresented communities, 2) sharing best practices for the development and maintenance of testbeds, and 3) connecting testbeds through an abstraction layer to support collaboration. The workshop features eight invited speakers, four contributed papers [1]-[4], and a presentation of a survey paper on testbeds [5]. The survey paper provides an online comparative table of more than 25 testbeds, available at https://bassamlab.github.io/testbeds-survey. The workshop's own website is available at https://cpm-remote.lrt.unibwmuenchen.de/iv24-workshop.
Holistic Understanding of 3D Scenes as Universal Scene Description
Dec 02, 2024



3D scene understanding is a long-standing challenge in computer vision and a key component in enabling mixed reality, wearable computing, and embodied AI. Providing a solution to these applications requires a multifaceted approach that covers scene-centric, object-centric, as well as interaction-centric capabilities. While there exist numerous datasets approaching the former two problems, the task of understanding interactable and articulated objects is underrepresented and only partly covered by current works. In this work, we address this shortcoming and introduce (1) an expertly curated dataset in the Universal Scene Description (USD) format, featuring high-quality manual annotations, for instance, segmentation and articulation on 280 indoor scenes; (2) a learning-based model together with a novel baseline capable of predicting part segmentation along with a full specification of motion attributes, including motion type, articulated and interactable parts, and motion parameters; (3) a benchmark serving to compare upcoming methods for the task at hand. Overall, our dataset provides 8 types of annotations - object and part segmentations, motion types, movable and interactable parts, motion parameters, connectivity, and object mass annotations. With its broad and high-quality annotations, the data provides the basis for holistic 3D scene understanding models. All data is provided in the USD format, allowing interoperability and easy integration with downstream tasks. We provide open access to our dataset, benchmark, and method's source code.
Occam's LGS: A Simple Approach for Language Gaussian Splatting
Dec 02, 2024



TL;DR: Gaussian Splatting is a widely adopted approach for 3D scene representation that offers efficient, high-quality 3D reconstruction and rendering. A major reason for the success of 3DGS is its simplicity of representing a scene with a set of Gaussians, which makes it easy to interpret and adapt. To enhance scene understanding beyond the visual representation, approaches have been developed that extend 3D Gaussian Splatting with semantic vision-language features, especially allowing for open-set tasks. In this setting, the language features of 3D Gaussian Splatting are often aggregated from multiple 2D views. Existing works address this aggregation problem using cumbersome techniques that lead to high computational cost and training time. In this work, we show that the sophisticated techniques for language-grounded 3D Gaussian Splatting are simply unnecessary. Instead, we apply Occam's razor to the task at hand and perform weighted multi-view feature aggregation using the weights derived from the standard rendering process, followed by a simple heuristic-based noisy Gaussian filtration. Doing so offers us state-of-the-art results with a speed-up of two orders of magnitude. We showcase our results in two commonly used benchmark datasets: LERF and 3D-OVS. Our simple approach allows us to perform reasoning directly in the language features, without any compression whatsoever. Such modeling in turn offers easy scene manipulation, unlike the existing methods -- which we illustrate using an application of object insertion in the scene. Furthermore, we provide a thorough discussion regarding the significance of our contributions within the context of the current literature. Project Page: https://insait-institute.github.io/OccamLGS/
Probabilistic Sampling of Balanced K-Means using Adiabatic Quantum Computing
Oct 18, 2023



Adiabatic quantum computing (AQC) is a promising quantum computing approach for discrete and often NP-hard optimization problems. Current AQCs allow to implement problems of research interest, which has sparked the development of quantum representations for many machine learning and computer vision tasks. Despite requiring multiple measurements from the noisy AQC, current approaches only utilize the best measurement, discarding information contained in the remaining ones. In this work, we explore the potential of using this information for probabilistic balanced k-means clustering. Instead of discarding non-optimal solutions, we propose to use them to compute calibrated posterior probabilities with little additional compute cost. This allows us to identify ambiguous solutions and data points, which we demonstrate on a D-Wave AQC on synthetic and real data.
Adiabatic Quantum Computing for Multi Object Tracking
Feb 17, 2022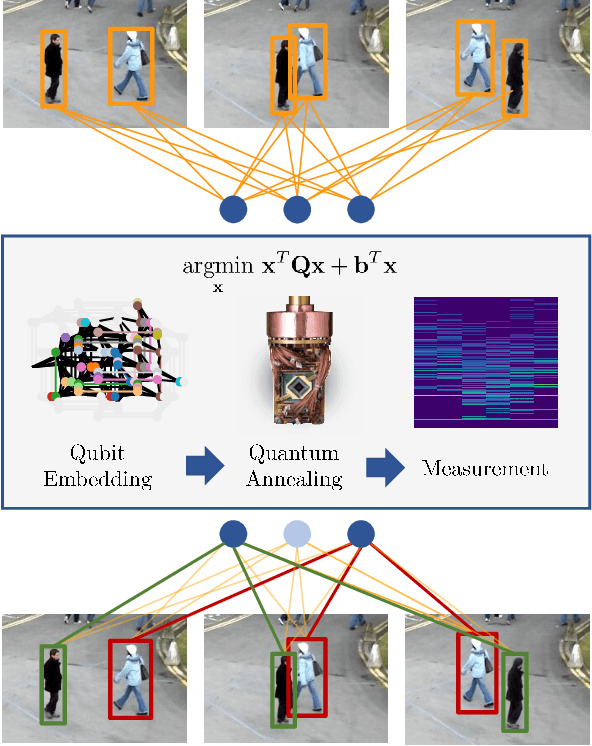

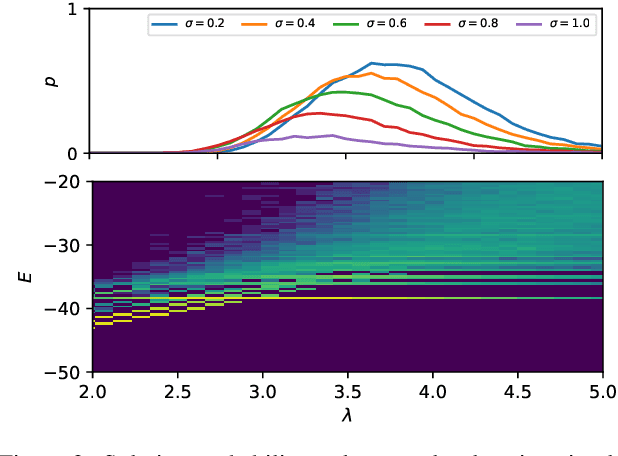

Multi-Object Tracking (MOT) is most often approached in the tracking-by-detection paradigm, where object detections are associated through time. The association step naturally leads to discrete optimization problems. As these optimization problems are often NP-hard, they can only be solved exactly for small instances on current hardware. Adiabatic quantum computing (AQC) offers a solution for this, as it has the potential to provide a considerable speedup on a range of NP-hard optimization problems in the near future. However, current MOT formulations are unsuitable for quantum computing due to their scaling properties. In this work, we therefore propose the first MOT formulation designed to be solved with AQC. We employ an Ising model that represents the quantum mechanical system implemented on the AQC. We show that our approach is competitive compared with state-of-the-art optimization-based approaches, even when using of-the-shelf integer programming solvers. Finally, we demonstrate that our MOT problem is already solvable on the current generation of real quantum computers for small examples, and analyze the properties of the measured solutions.