 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-VIS: Sparse frame Annotations for training Video Instance Segmentation
Jun 18, 2026Recent online video instance segmentation (VIS) methods have achieved impressive results, thus becoming the preferred approach to segment instances in videos. Despite the resurgence of impressive single image models, the online (or semi-online) VIS approaches outperform single-image models (e.g., based on SAM) by using long sequences of densely annotated frames during training. However,such a training setup of VIS is expensive in the sense of compute as well as dense annotations required. In order to solve these major flaws, we argue that the effective modeling of the instances and their evolution in videos do not require densely annotated frames. To that end, we propose a simple and effective module, called Past-frames Feature Propagation (PFP) which aggregates low-dimensional features from the image encoder of multiple frames. This simple low-compute module provides tremendous learning capability in using sparse video frame labels for end-to-end training. Combined with a light-weight frame-specific Instance Queries, our Sparse frame Annotation VIS (SA-VIS) significantly improves performance over its baseline. Most interestingly, our simple design that avoids complexities effectively bridges the gap in accuracy between training on sparsely and densely annotated video sequences. This translates to a mere 0.4% drop in performance of SA-VIS when using annotations for only 1/5 of the images in the dataset. Empirically, SA-VIS shows strong improvements over the baseline on YouTube-VIS 2019/2021/2022 and Occluded VIS (OVIS) and an over 1% improvement in AP on the state-of-the-art in a limited annotations scenario.
VF-NeRF: Learning Neural Vector Fields for Indoor Scene Reconstruction
Aug 16, 2024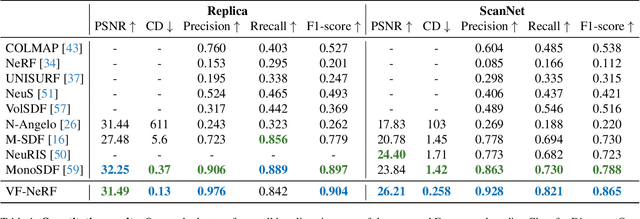
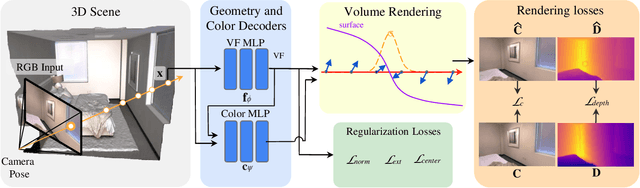
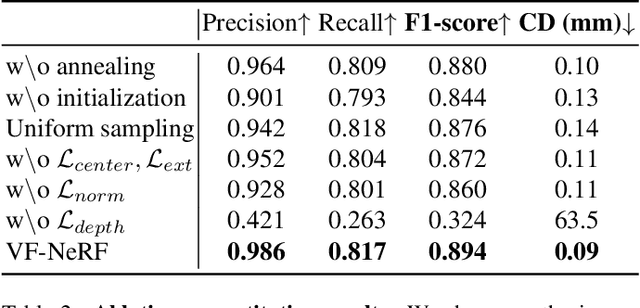
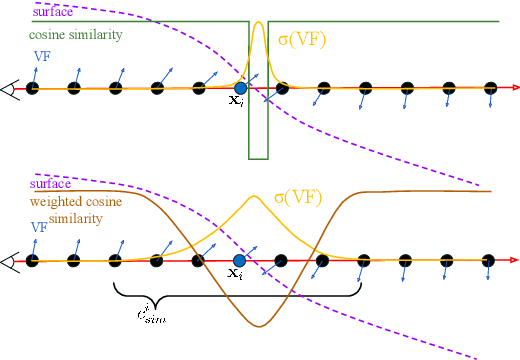
Implicit surfaces via neural radiance fields (NeRF) have shown surprising accuracy in surface reconstruction. Despite their success in reconstructing richly textured surfaces, existing methods struggle with planar regions with weak textures, which account for the majority of indoor scenes. In this paper, we address indoor dense surface reconstruction by revisiting key aspects of NeRF in order to use the recently proposed Vector Field (VF) as the implicit representation. VF is defined by the unit vector directed to the nearest surface point. It therefore flips direction at the surface and equals to the explicit surface normals. Except for this flip, VF remains constant along planar surfaces and provides a strong inductive bias in representing planar surfaces. Concretely, we develop a novel density-VF relationship and a training scheme that allows us to learn VF via volume rendering By doing this, VF-NeRF can model large planar surfaces and sharp corners accurately. We show that, when depth cues are available, our method further improves and achieves state-of-the-art results in reconstructing indoor scenes and rendering novel views. We extensively evaluate VF-NeRF on indoor datasets and run ablations of its components.
Neural Vector Fields for Surface Representation and Inference
Apr 13, 2022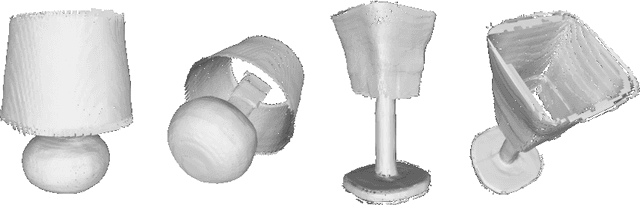
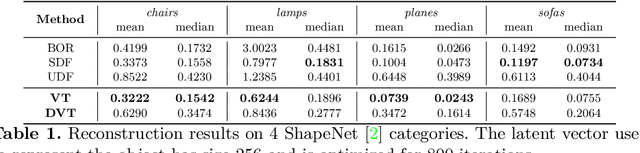
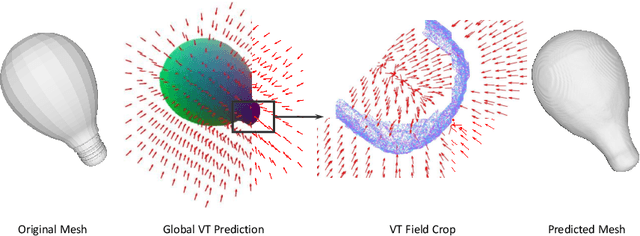
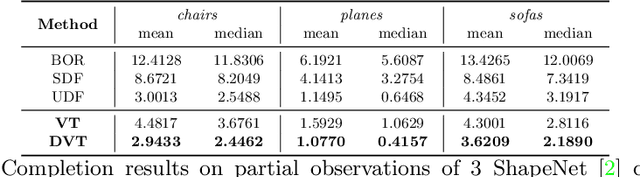
Neural implicit fields have recently been shown to represent 3D shapes accurately, opening up various applications in 3D shape analysis. Up to now, such implicit fields for 3D representation are scalar, encoding the signed distance or binary volume occupancy and more recently the unsigned distance. However, the first two can only represent closed shapes, while the unsigned distance has difficulties in accurate and fast shape inference. In this paper, we propose a Neural Vector Field for shape representation in order to overcome the two aforementioned problems. Mapping each point in space to the direction towards the closest surface, we can represent any type of shape. Similarly the shape mesh can be reconstructed by applying the marching cubes algorithm, with proposed small changes, on top of the inferred vector field. We compare the method on ShapeNet where the proposed new neural implicit field shows superior accuracy in representing both closed and open shapes outperforming previous methods.
Zero Pixel Directional Boundary by Vector Transform
Mar 16, 2022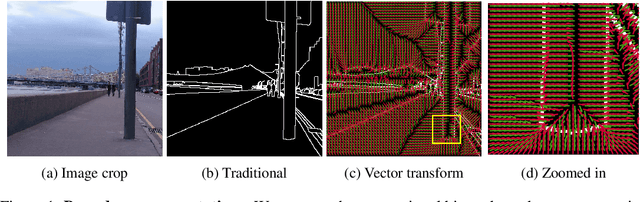
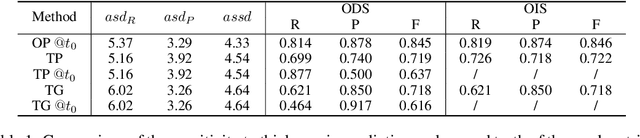

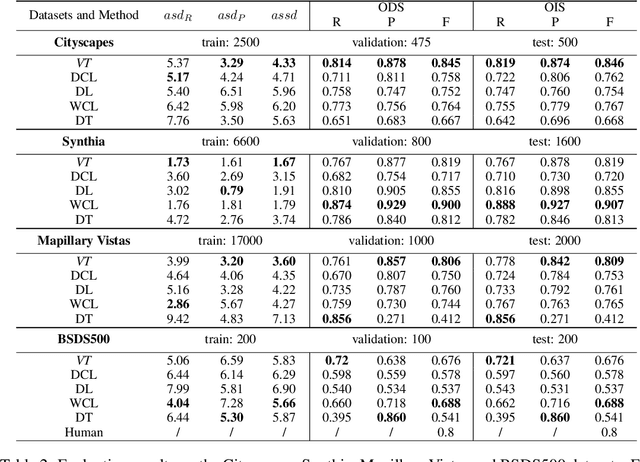
Boundaries are among the primary visual cues used by human and computer vision systems. One of the key problems in boundary detection is the label representation, which typically leads to class imbalance and, as a consequence, to thick boundaries that require non-differential post-processing steps to be thinned. In this paper, we re-interpret boundaries as 1-D surfaces and formulate a one-to-one vector transform function that allows for training of boundary prediction completely avoiding the class imbalance issue. Specifically, we define the boundary representation at any point as the unit vector pointing to the closest boundary surface. Our problem formulation leads to the estimation of direction as well as richer contextual information of the boundary, and, if desired, the availability of zero-pixel thin boundaries also at training time. Our method uses no hyper-parameter in the training loss and a fixed stable hyper-parameter at inference. We provide theoretical justification/discussions of the vector transform representation. We evaluate the proposed loss method using a standard architecture and show the excellent performance over other losses and representations on several datasets.
Decoder Fusion RNN: Context and Interaction Aware Decoders for Trajectory Prediction
Aug 12, 2021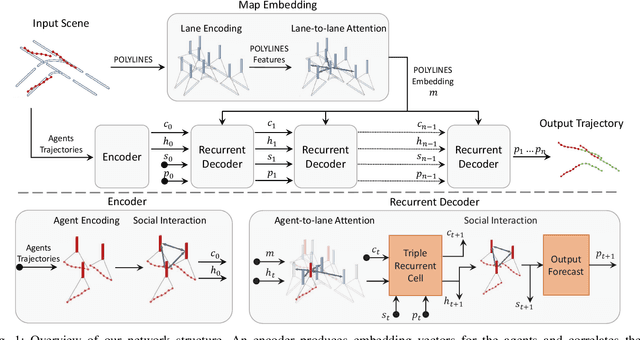
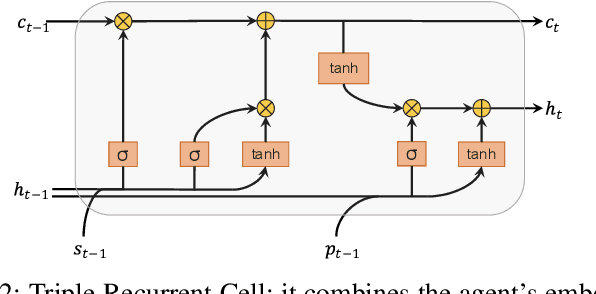
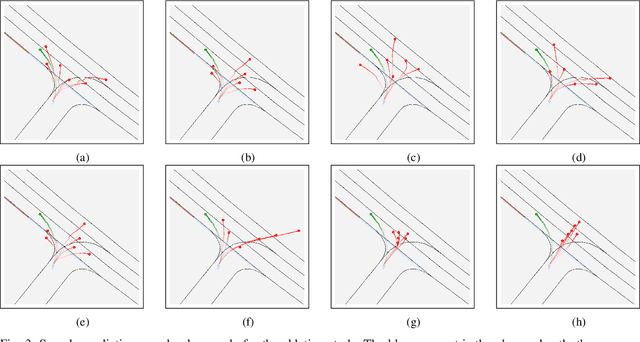
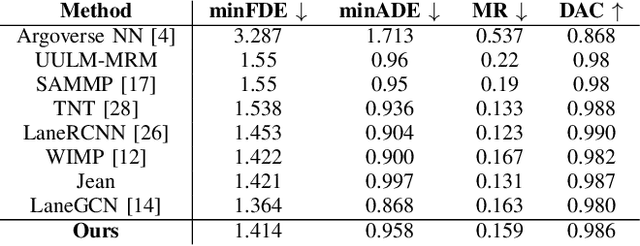
Forecasting the future behavior of all traffic agents in the vicinity is a key task to achieve safe and reliable autonomous driving systems. It is a challenging problem as agents adjust their behavior depending on their intentions, the others' actions, and the road layout. In this paper, we propose Decoder Fusion RNN (DF-RNN), a recurrent, attention-based approach for motion forecasting. Our network is composed of a recurrent behavior encoder, an inter-agent multi-headed attention module, and a context-aware decoder. We design a map encoder that embeds polyline segments, combines them to create a graph structure, and merges their relevant parts with the agents' embeddings. We fuse the encoded map information with further inter-agent interactions only inside the decoder and propose to use explicit training as a method to effectively utilize the information available. We demonstrate the efficacy of our method by testing it on the Argoverse motion forecasting dataset and show its state-of-the-art performance on the public benchmark.