 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelationship-Aware Hierarchical 3D Scene Graph for Task Reasoning
Feb 02, 2026Representing and understanding 3D environments in a structured manner is crucial for autonomous agents to navigate and reason about their surroundings. While traditional Simultaneous Localization and Mapping (SLAM) methods generate metric reconstructions and can be extended to metric-semantic mapping, they lack a higher level of abstraction and relational reasoning. To address this gap, 3D scene graphs have emerged as a powerful representation for capturing hierarchical structures and object relationships. In this work, we propose an enhanced hierarchical 3D scene graph that integrates open-vocabulary features across multiple abstraction levels and supports object-relational reasoning. Our approach leverages a Vision Language Model (VLM) to infer semantic relationships. Notably, we introduce a task reasoning module that combines Large Language Models (LLM) and a VLM to interpret the scene graph's semantic and relational information, enabling agents to reason about tasks and interact with their environment more intelligently. We validate our method by deploying it on a quadruped robot in multiple environments and tasks, highlighting its ability to reason about them.
Performance-driven Constrained Optimal Auto-Tuner for MPC
Mar 10, 2025A key challenge in tuning Model Predictive Control (MPC) cost function parameters is to ensure that the system performance stays consistently above a certain threshold. To address this challenge, we propose a novel method, COAT-MPC, Constrained Optimal Auto-Tuner for MPC. With every tuning iteration, COAT-MPC gathers performance data and learns by updating its posterior belief. It explores the tuning parameters' domain towards optimistic parameters in a goal-directed fashion, which is key to its sample efficiency. We theoretically analyze COAT-MPC, showing that it satisfies performance constraints with arbitrarily high probability at all times and provably converges to the optimum performance within finite time. Through comprehensive simulations and comparative analyses with a hardware platform, we demonstrate the effectiveness of COAT-MPC in comparison to classical Bayesian Optimization (BO) and other state-of-the-art methods. When applied to autonomous racing, our approach outperforms baselines in terms of constraint violations and cumulative regret over time.
Augmented Reality without Borders: Achieving Precise Localization Without Maps
Sep 04, 2024



Visual localization is crucial for Computer Vision and Augmented Reality (AR) applications, where determining the camera or device's position and orientation is essential to accurately interact with the physical environment. Traditional methods rely on detailed 3D maps constructed using Structure from Motion (SfM) or Simultaneous Localization and Mapping (SLAM), which is computationally expensive and impractical for dynamic or large-scale environments. We introduce MARLoc, a novel localization framework for AR applications that uses known relative transformations within image sequences to perform intra-sequence triangulation, generating 3D-2D correspondences for pose estimation and refinement. MARLoc eliminates the need for pre-built SfM maps, providing accurate and efficient localization suitable for dynamic outdoor environments. Evaluation with benchmark datasets and real-world experiments demonstrates MARLoc's state-of-the-art performance and robustness. By integrating MARLoc into an AR device, we highlight its capability to achieve precise localization in real-world outdoor scenarios, showcasing its practical effectiveness and potential to enhance visual localization in AR applications.
VF-NeRF: Learning Neural Vector Fields for Indoor Scene Reconstruction
Aug 16, 2024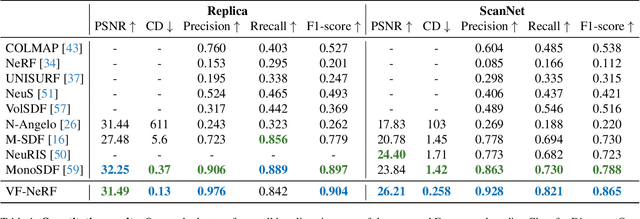
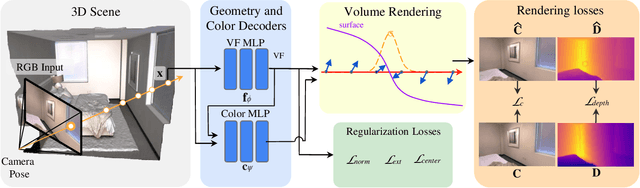
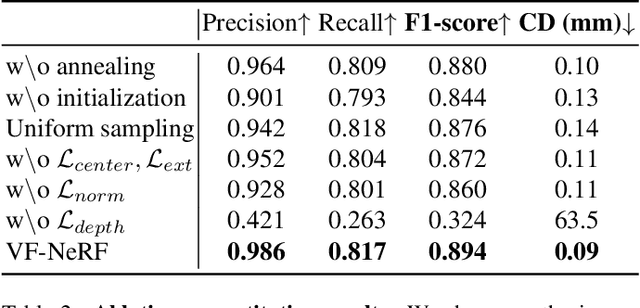
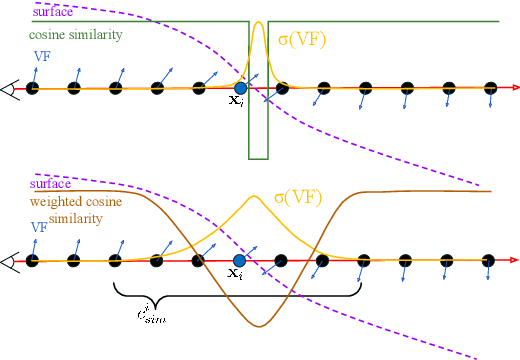
Implicit surfaces via neural radiance fields (NeRF) have shown surprising accuracy in surface reconstruction. Despite their success in reconstructing richly textured surfaces, existing methods struggle with planar regions with weak textures, which account for the majority of indoor scenes. In this paper, we address indoor dense surface reconstruction by revisiting key aspects of NeRF in order to use the recently proposed Vector Field (VF) as the implicit representation. VF is defined by the unit vector directed to the nearest surface point. It therefore flips direction at the surface and equals to the explicit surface normals. Except for this flip, VF remains constant along planar surfaces and provides a strong inductive bias in representing planar surfaces. Concretely, we develop a novel density-VF relationship and a training scheme that allows us to learn VF via volume rendering By doing this, VF-NeRF can model large planar surfaces and sharp corners accurately. We show that, when depth cues are available, our method further improves and achieves state-of-the-art results in reconstructing indoor scenes and rendering novel views. We extensively evaluate VF-NeRF on indoor datasets and run ablations of its components.