 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne2Any: One-Reference 6D Pose Estimation for Any Object
May 07, 20256D object pose estimation remains challenging for many applications due to dependencies on complete 3D models, multi-view images, or training limited to specific object categories. These requirements make generalization to novel objects difficult for which neither 3D models nor multi-view images may be available. To address this, we propose a novel method One2Any that estimates the relative 6-degrees of freedom (DOF) object pose using only a single reference-single query RGB-D image, without prior knowledge of its 3D model, multi-view data, or category constraints. We treat object pose estimation as an encoding-decoding process, first, we obtain a comprehensive Reference Object Pose Embedding (ROPE) that encodes an object shape, orientation, and texture from a single reference view. Using this embedding, a U-Net-based pose decoding module produces Reference Object Coordinate (ROC) for new views, enabling fast and accurate pose estimation. This simple encoding-decoding framework allows our model to be trained on any pair-wise pose data, enabling large-scale training and demonstrating great scalability. Experiments on multiple benchmark datasets demonstrate that our model generalizes well to novel objects, achieving state-of-the-art accuracy and robustness even rivaling methods that require multi-view or CAD inputs, at a fraction of compute.
* accepted by CVPR 2025
Self-supervised Shape Completion via Involution and Implicit Correspondences
Sep 24, 2024



3D shape completion is traditionally solved using supervised training or by distribution learning on complete shape examples. Recently self-supervised learning approaches that do not require any complete 3D shape examples have gained more interests. In this paper, we propose a non-adversarial self-supervised approach for the shape completion task. Our first finding is that completion problems can be formulated as an involutory function trivially, which implies a special constraint on the completion function G, such that G(G(X)) = X. Our second constraint on self-supervised shape completion relies on the fact that shape completion becomes easier to solve with correspondences and similarly, completion can simplify the correspondences problem. We formulate a consistency measure in the canonical space in order to supervise the completion function. We efficiently optimize the completion and correspondence modules using "freeze and alternate" strategy. The overall approach performs well for rigid shapes in a category as well as dynamic non-rigid shapes. We ablate our design choices and compare our solution against state-of-the-art methods, showing remarkable accuracy approaching supervised accuracy in some cases.
VF-NeRF: Learning Neural Vector Fields for Indoor Scene Reconstruction
Aug 16, 2024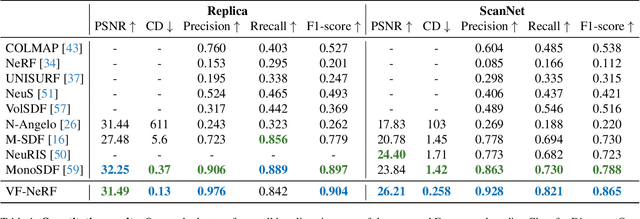
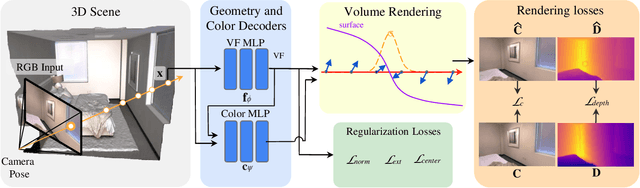
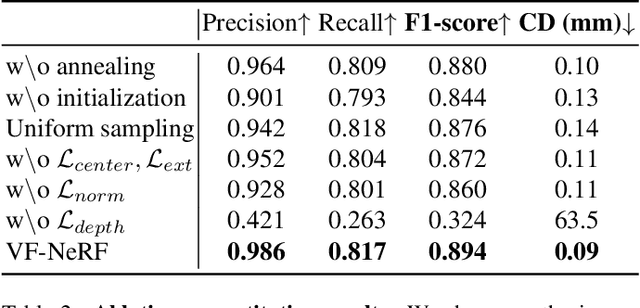
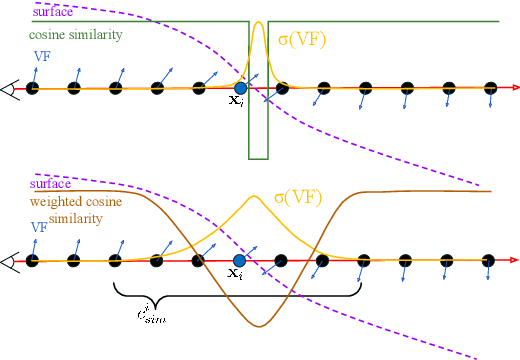
Implicit surfaces via neural radiance fields (NeRF) have shown surprising accuracy in surface reconstruction. Despite their success in reconstructing richly textured surfaces, existing methods struggle with planar regions with weak textures, which account for the majority of indoor scenes. In this paper, we address indoor dense surface reconstruction by revisiting key aspects of NeRF in order to use the recently proposed Vector Field (VF) as the implicit representation. VF is defined by the unit vector directed to the nearest surface point. It therefore flips direction at the surface and equals to the explicit surface normals. Except for this flip, VF remains constant along planar surfaces and provides a strong inductive bias in representing planar surfaces. Concretely, we develop a novel density-VF relationship and a training scheme that allows us to learn VF via volume rendering By doing this, VF-NeRF can model large planar surfaces and sharp corners accurately. We show that, when depth cues are available, our method further improves and achieves state-of-the-art results in reconstructing indoor scenes and rendering novel views. We extensively evaluate VF-NeRF on indoor datasets and run ablations of its components.
iHuman: Instant Animatable Digital Humans From Monocular Videos
Jul 15, 2024Personalized 3D avatars require an animatable representation of digital humans. Doing so instantly from monocular videos offers scalability to broad class of users and wide-scale applications. In this paper, we present a fast, simple, yet effective method for creating animatable 3D digital humans from monocular videos. Our method utilizes the efficiency of Gaussian splatting to model both 3D geometry and appearance. However, we observed that naively optimizing Gaussian splats results in inaccurate geometry, thereby leading to poor animations. This work achieves and illustrates the need of accurate 3D mesh-type modelling of the human body for animatable digitization through Gaussian splats. This is achieved by developing a novel pipeline that benefits from three key aspects: (a) implicit modelling of surface's displacements and the color's spherical harmonics; (b) binding of 3D Gaussians to the respective triangular faces of the body template; (c) a novel technique to render normals followed by their auxiliary supervision. Our exhaustive experiments on three different benchmark datasets demonstrates the state-of-the-art results of our method, in limited time settings. In fact, our method is faster by an order of magnitude (in terms of training time) than its closest competitor. At the same time, we achieve superior rendering and 3D reconstruction performance under the change of poses.
Residual Learning for Image Point Descriptors
Dec 24, 2023Local image feature descriptors have had a tremendous impact on the development and application of computer vision methods. It is therefore unsurprising that significant efforts are being made for learning-based image point descriptors. However, the advantage of learned methods over handcrafted methods in real applications is subtle and more nuanced than expected. Moreover, handcrafted descriptors such as SIFT and SURF still perform better point localization in Structure-from-Motion (SfM) compared to many learned counterparts. In this paper, we propose a very simple and effective approach to learning local image descriptors by using a hand-crafted detector and descriptor. Specifically, we choose to learn only the descriptors, supported by handcrafted descriptors while discarding the point localization head. We optimize the final descriptor by leveraging the knowledge already present in the handcrafted descriptor. Such an approach of optimization allows us to discard learning knowledge already present in non-differentiable functions such as the hand-crafted descriptors and only learn the residual knowledge in the main network branch. This offers 50X convergence speed compared to the standard baseline architecture of SuperPoint while at inference the combined descriptor provides superior performance over the learned and hand-crafted descriptors. This is done with minor increase in the computations over the baseline learned descriptor. Our approach has potential applications in ensemble learning and learning with non-differentiable functions. We perform experiments in matching, camera localization and Structure-from-Motion in order to showcase the advantages of our approach.
Continuous Pose for Monocular Cameras in Neural Implicit Representation
Nov 28, 2023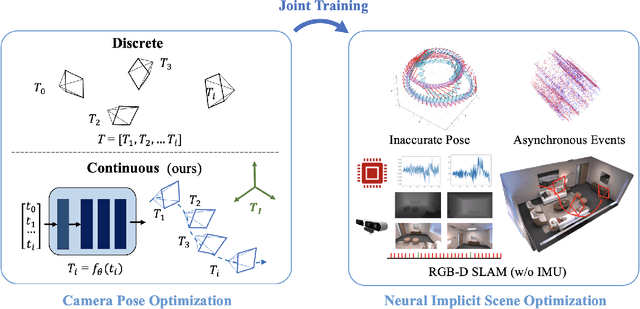
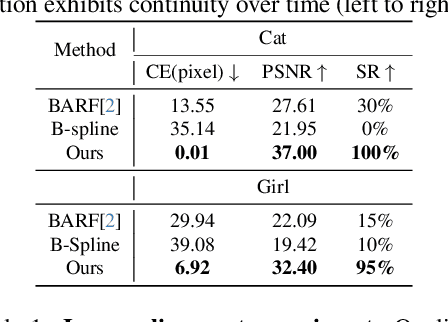


In this paper, we showcase the effectiveness of optimizing monocular camera poses as a continuous function of time. The camera poses are represented using an implicit neural function which maps the given time to the corresponding camera pose. The mapped camera poses are then used for the downstream tasks where joint camera pose optimization is also required. While doing so, the network parameters -- that implicitly represent camera poses -- are optimized. We exploit the proposed method in four diverse experimental settings, namely, (1) NeRF from noisy poses; (2) NeRF from asynchronous Events; (3) Visual Simultaneous Localization and Mapping (vSLAM); and (4) vSLAM with IMUs. In all four settings, the proposed method performs significantly better than the compared baselines and the state-of-the-art methods. Additionally, using the assumption of continuous motion, changes in pose may actually live in a manifold that has lower than 6 degrees of freedom (DOF) is also realized. We call this low DOF motion representation as the \emph{intrinsic motion} and use the approach in vSLAM settings, showing impressive camera tracking performance.
Deformable Neural Radiance Fields using RGB and Event Cameras
Sep 25, 2023Modeling Neural Radiance Fields for fast-moving deformable objects from visual data alone is a challenging problem. A major issue arises due to the high deformation and low acquisition rates. To address this problem, we propose to use event cameras that offer very fast acquisition of visual change in an asynchronous manner. In this work, we develop a novel method to model the deformable neural radiance fields using RGB and event cameras. The proposed method uses the asynchronous stream of events and calibrated sparse RGB frames. In our setup, the camera pose at the individual events required to integrate them into the radiance fields remains unknown. Our method jointly optimizes these poses and the radiance field. This happens efficiently by leveraging the collection of events at once and actively sampling the events during learning. Experiments conducted on both realistically rendered graphics and real-world datasets demonstrate a significant benefit of the proposed method over the state-of-the-art and the compared baseline. This shows a promising direction for modeling deformable neural radiance fields in real-world dynamic scenes.
Mining Relations among Cross-Frame Affinities for Video Semantic Segmentation
Jul 21, 2022



The essence of video semantic segmentation (VSS) is how to leverage temporal information for prediction. Previous efforts are mainly devoted to developing new techniques to calculate the cross-frame affinities such as optical flow and attention. Instead, this paper contributes from a different angle by mining relations among cross-frame affinities, upon which better temporal information aggregation could be achieved. We explore relations among affinities in two aspects: single-scale intrinsic correlations and multi-scale relations. Inspired by traditional feature processing, we propose Single-scale Affinity Refinement (SAR) and Multi-scale Affinity Aggregation (MAA). To make it feasible to execute MAA, we propose a Selective Token Masking (STM) strategy to select a subset of consistent reference tokens for different scales when calculating affinities, which also improves the efficiency of our method. At last, the cross-frame affinities strengthened by SAR and MAA are adopted for adaptively aggregating temporal information. Our experiments demonstrate that the proposed method performs favorably against state-of-the-art VSS methods. The code is publicly available at https://github.com/GuoleiSun/VSS-MRCFA
Neural Vector Fields for Surface Representation and Inference
Apr 13, 2022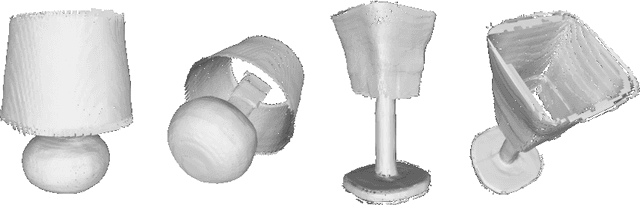
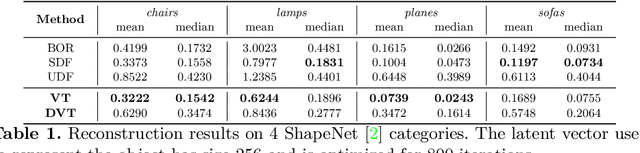
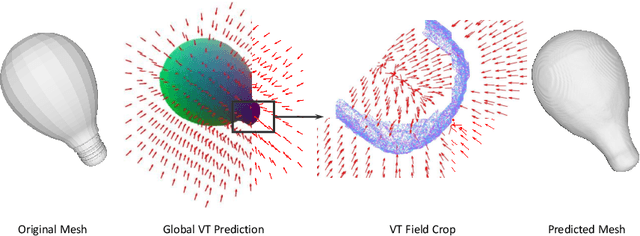
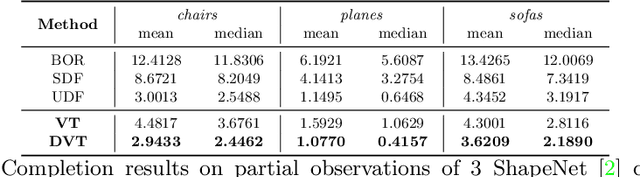
Neural implicit fields have recently been shown to represent 3D shapes accurately, opening up various applications in 3D shape analysis. Up to now, such implicit fields for 3D representation are scalar, encoding the signed distance or binary volume occupancy and more recently the unsigned distance. However, the first two can only represent closed shapes, while the unsigned distance has difficulties in accurate and fast shape inference. In this paper, we propose a Neural Vector Field for shape representation in order to overcome the two aforementioned problems. Mapping each point in space to the direction towards the closest surface, we can represent any type of shape. Similarly the shape mesh can be reconstructed by applying the marching cubes algorithm, with proposed small changes, on top of the inferred vector field. We compare the method on ShapeNet where the proposed new neural implicit field shows superior accuracy in representing both closed and open shapes outperforming previous methods.
Zero Pixel Directional Boundary by Vector Transform
Mar 16, 2022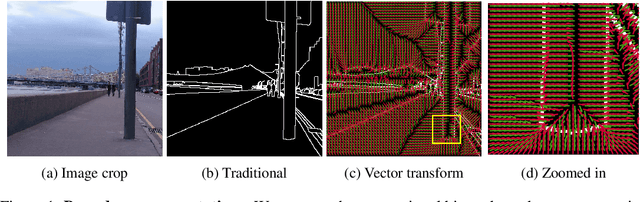
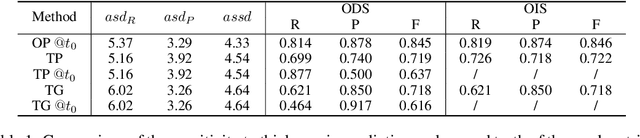

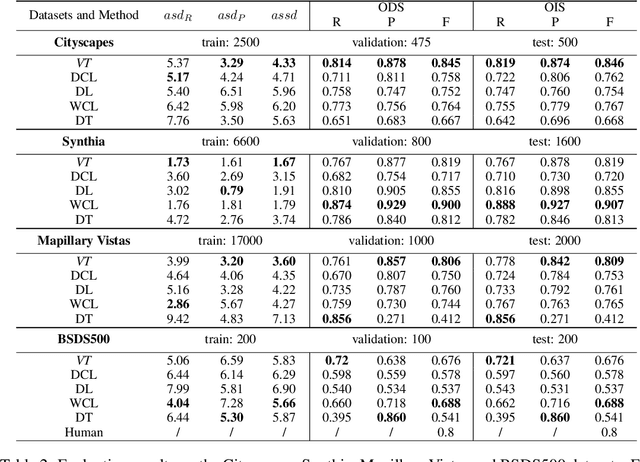
Boundaries are among the primary visual cues used by human and computer vision systems. One of the key problems in boundary detection is the label representation, which typically leads to class imbalance and, as a consequence, to thick boundaries that require non-differential post-processing steps to be thinned. In this paper, we re-interpret boundaries as 1-D surfaces and formulate a one-to-one vector transform function that allows for training of boundary prediction completely avoiding the class imbalance issue. Specifically, we define the boundary representation at any point as the unit vector pointing to the closest boundary surface. Our problem formulation leads to the estimation of direction as well as richer contextual information of the boundary, and, if desired, the availability of zero-pixel thin boundaries also at training time. Our method uses no hyper-parameter in the training loss and a fixed stable hyper-parameter at inference. We provide theoretical justification/discussions of the vector transform representation. We evaluate the proposed loss method using a standard architecture and show the excellent performance over other losses and representations on several datasets.