 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Pose for Monocular Cameras in Neural Implicit Representation
Paper and Code
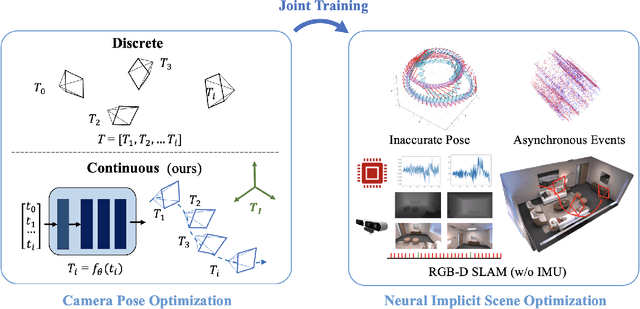
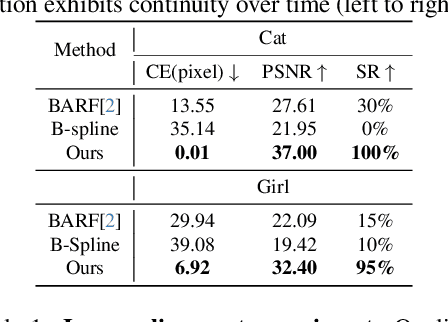


In this paper, we showcase the effectiveness of optimizing monocular camera poses as a continuous function of time. The camera poses are represented using an implicit neural function which maps the given time to the corresponding camera pose. The mapped camera poses are then used for the downstream tasks where joint camera pose optimization is also required. While doing so, the network parameters -- that implicitly represent camera poses -- are optimized. We exploit the proposed method in four diverse experimental settings, namely, (1) NeRF from noisy poses; (2) NeRF from asynchronous Events; (3) Visual Simultaneous Localization and Mapping (vSLAM); and (4) vSLAM with IMUs. In all four settings, the proposed method performs significantly better than the compared baselines and the state-of-the-art methods. Additionally, using the assumption of continuous motion, changes in pose may actually live in a manifold that has lower than 6 degrees of freedom (DOF) is also realized. We call this low DOF motion representation as the \emph{intrinsic motion} and use the approach in vSLAM settings, showing impressive camera tracking performance.