 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Learning for Image Point Descriptors
Dec 24, 2023Local image feature descriptors have had a tremendous impact on the development and application of computer vision methods. It is therefore unsurprising that significant efforts are being made for learning-based image point descriptors. However, the advantage of learned methods over handcrafted methods in real applications is subtle and more nuanced than expected. Moreover, handcrafted descriptors such as SIFT and SURF still perform better point localization in Structure-from-Motion (SfM) compared to many learned counterparts. In this paper, we propose a very simple and effective approach to learning local image descriptors by using a hand-crafted detector and descriptor. Specifically, we choose to learn only the descriptors, supported by handcrafted descriptors while discarding the point localization head. We optimize the final descriptor by leveraging the knowledge already present in the handcrafted descriptor. Such an approach of optimization allows us to discard learning knowledge already present in non-differentiable functions such as the hand-crafted descriptors and only learn the residual knowledge in the main network branch. This offers 50X convergence speed compared to the standard baseline architecture of SuperPoint while at inference the combined descriptor provides superior performance over the learned and hand-crafted descriptors. This is done with minor increase in the computations over the baseline learned descriptor. Our approach has potential applications in ensemble learning and learning with non-differentiable functions. We perform experiments in matching, camera localization and Structure-from-Motion in order to showcase the advantages of our approach.
Long-Term Invariant Local Features via Implicit Cross-Domain Correspondences
Nov 06, 2023



Modern learning-based visual feature extraction networks perform well in intra-domain localization, however, their performance significantly declines when image pairs are captured across long-term visual domain variations, such as different seasonal and daytime variations. In this paper, our first contribution is a benchmark to investigate the performance impact of long-term variations on visual localization. We conduct a thorough analysis of the performance of current state-of-the-art feature extraction networks under various domain changes and find a significant performance gap between intra- and cross-domain localization. We investigate different methods to close this gap by improving the supervision of modern feature extractor networks. We propose a novel data-centric method, Implicit Cross-Domain Correspondences (iCDC). iCDC represents the same environment with multiple Neural Radiance Fields, each fitting the scene under individual visual domains. It utilizes the underlying 3D representations to generate accurate correspondences across different long-term visual conditions. Our proposed method enhances cross-domain localization performance, significantly reducing the performance gap. When evaluated on popular long-term localization benchmarks, our trained networks consistently outperform existing methods. This work serves as a substantial stride toward more robust visual localization pipelines for long-term deployments, and opens up research avenues in the development of long-term invariant descriptors.
Breathing New Life into 3D Assets with Generative Repainting
Sep 15, 2023



Diffusion-based text-to-image models ignited immense attention from the vision community, artists, and content creators. Broad adoption of these models is due to significant improvement in the quality of generations and efficient conditioning on various modalities, not just text. However, lifting the rich generative priors of these 2D models into 3D is challenging. Recent works have proposed various pipelines powered by the entanglement of diffusion models and neural fields. We explore the power of pretrained 2D diffusion models and standard 3D neural radiance fields as independent, standalone tools and demonstrate their ability to work together in a non-learned fashion. Such modularity has the intrinsic advantage of eased partial upgrades, which became an important property in such a fast-paced domain. Our pipeline accepts any legacy renderable geometry, such as textured or untextured meshes, orchestrates the interaction between 2D generative refinement and 3D consistency enforcement tools, and outputs a painted input geometry in several formats. We conduct a large-scale study on a wide range of objects and categories from the ShapeNetSem dataset and demonstrate the advantages of our approach, both qualitatively and quantitatively. Project page: https://www.obukhov.ai/repainting_3d_assets
Composite Learning for Robust and Effective Dense Predictions
Oct 13, 2022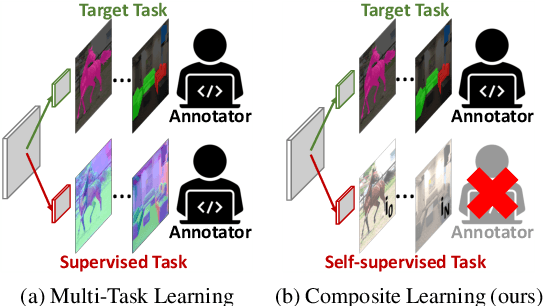
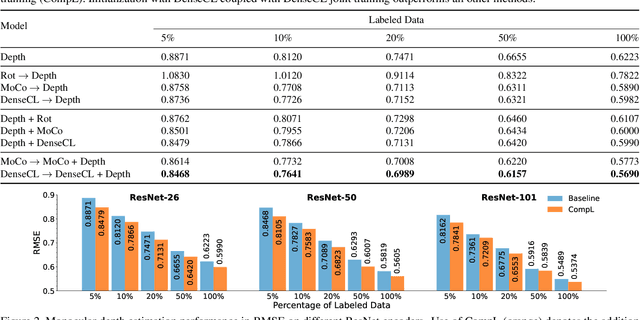
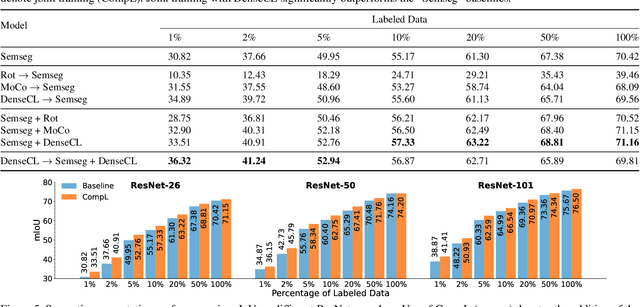
Multi-task learning promises better model generalization on a target task by jointly optimizing it with an auxiliary task. However, the current practice requires additional labeling efforts for the auxiliary task, while not guaranteeing better model performance. In this paper, we find that jointly training a dense prediction (target) task with a self-supervised (auxiliary) task can consistently improve the performance of the target task, while eliminating the need for labeling auxiliary tasks. We refer to this joint training as Composite Learning (CompL). Experiments of CompL on monocular depth estimation, semantic segmentation, and boundary detection show consistent performance improvements in fully and partially labeled datasets. Further analysis on depth estimation reveals that joint training with self-supervision outperforms most labeled auxiliary tasks. We also find that CompL can improve model robustness when the models are evaluated in new domains. These results demonstrate the benefits of self-supervision as an auxiliary task, and establish the design of novel task-specific self-supervised methods as a new axis of investigation for future multi-task learning research.
ZippyPoint: Fast Interest Point Detection, Description, and Matching through Mixed Precision Discretization
Mar 07, 2022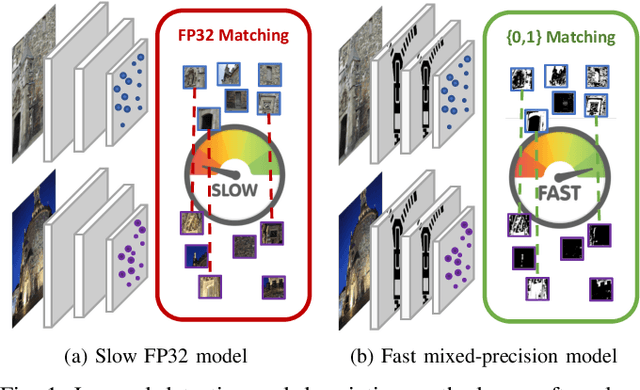
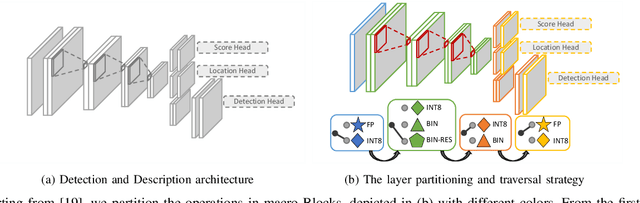
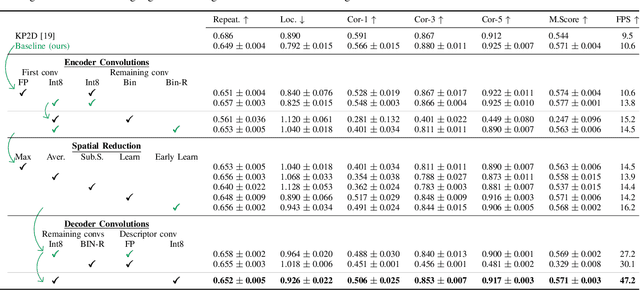

The design of more complex and powerful neural network models has significantly advanced the state-of-the-art in local feature detection and description. These advances can be attributed to deeper networks, improved training methodologies through self-supervision, or the introduction of new building blocks, such as graph neural networks for feature matching. However, in the pursuit of increased performance, efficient architectures that generate lightweight descriptors have received surprisingly little attention. In this paper, we investigate the adaptations neural networks for detection and description require in order to enable their use in embedded platforms. To that end, we investigate and adapt network quantization techniques for use in real-time applications. In addition, we revisit common practices in descriptor quantization and propose the use of a binary descriptor normalization layer, enabling the generation of distinctive length-invariant binary descriptors. ZippyPoint, our efficient network, runs at 47.2 fps on the Apple M1 CPU. This is up to 5x faster than other learned detection and description models, making it the only real-time learned network. ZippyPoint consistently outperforms all other binary detection and descriptor methods in visual localization and homography estimation tasks. Code and trained models will be released upon publication.
Efficient Visual Tracking with Exemplar Transformers
Dec 17, 2021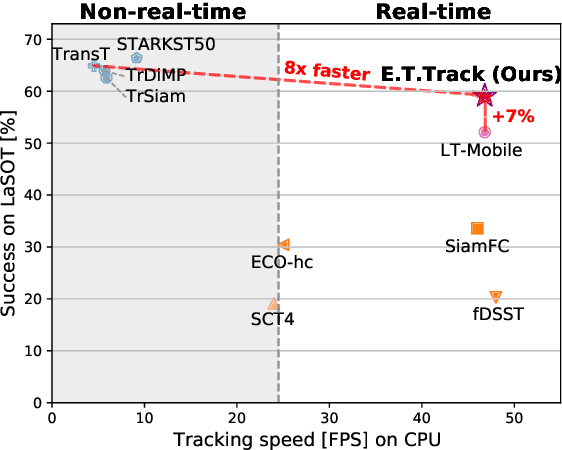


The design of more complex and powerful neural network models has significantly advanced the state-of-the-art in visual object tracking. These advances can be attributed to deeper networks, or to the introduction of new building blocks, such as transformers. However, in the pursuit of increased tracking performance, efficient tracking architectures have received surprisingly little attention. In this paper, we introduce the Exemplar Transformer, an efficient transformer for real-time visual object tracking. E.T.Track, our visual tracker that incorporates Exemplar Transformer layers, runs at 47 fps on a CPU. This is up to 8 times faster than other transformer-based models, making it the only real-time transformer-based tracker. When compared to lightweight trackers that can operate in real-time on standard CPUs, E.T.Track consistently outperforms all other methods on the LaSOT, OTB-100, NFS, TrackingNet and VOT-ST2020 datasets. The code will soon be released on https://github.com/visionml/pytracking.
Learning to Relate Depth and Semantics for Unsupervised Domain Adaptation
May 17, 2021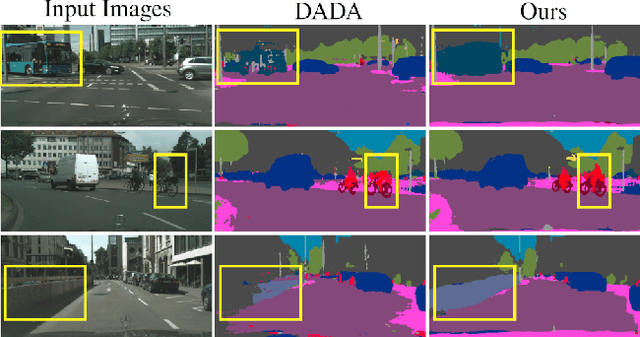
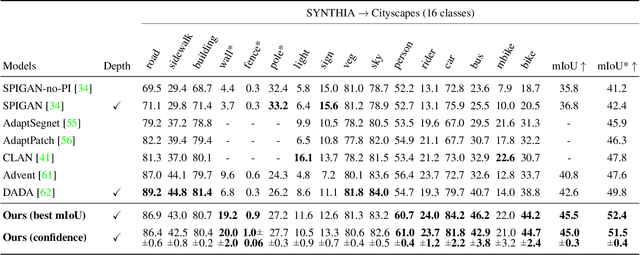

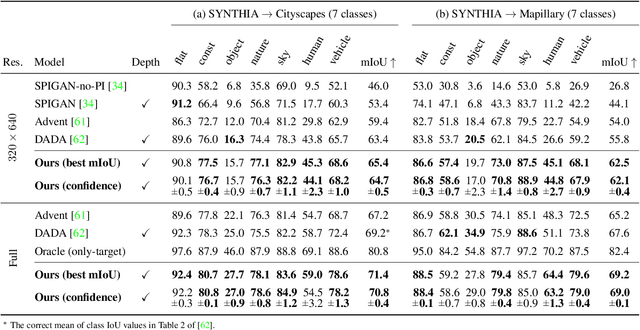
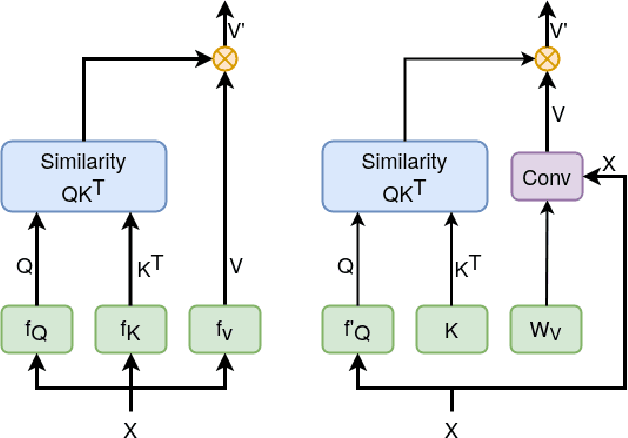
We present an approach for encoding visual task relationships to improve model performance in an Unsupervised Domain Adaptation (UDA) setting. Semantic segmentation and monocular depth estimation are shown to be complementary tasks; in a multi-task learning setting, a proper encoding of their relationships can further improve performance on both tasks. Motivated by this observation, we propose a novel Cross-Task Relation Layer (CTRL), which encodes task dependencies between the semantic and depth predictions. To capture the cross-task relationships, we propose a neural network architecture that contains task-specific and cross-task refinement heads. Furthermore, we propose an Iterative Self-Learning (ISL) training scheme, which exploits semantic pseudo-labels to provide extra supervision on the target domain. We experimentally observe improvements in both tasks' performance because the complementary information present in these tasks is better captured. Specifically, we show that: (1) our approach improves performance on all tasks when they are complementary and mutually dependent; (2) the CTRL helps to improve both semantic segmentation and depth estimation tasks performance in the challenging UDA setting; (3) the proposed ISL training scheme further improves the semantic segmentation performance. The implementation is available at https://github.com/susaha/ctrl-uda.
Exploring Relational Context for Multi-Task Dense Prediction
Apr 28, 2021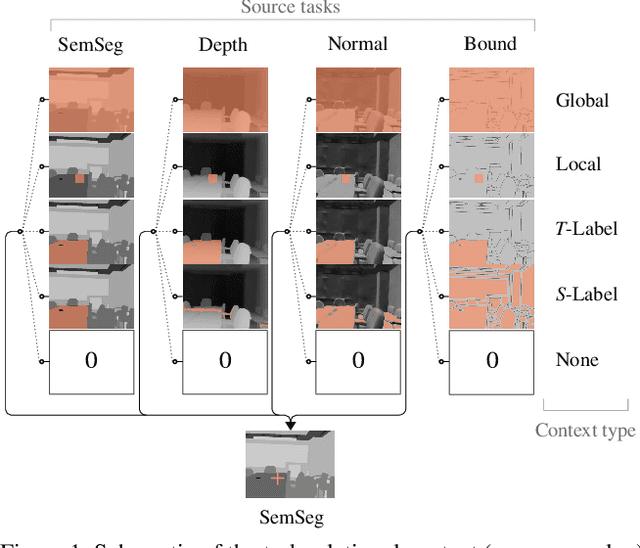
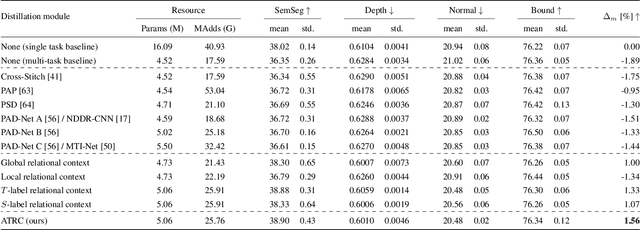
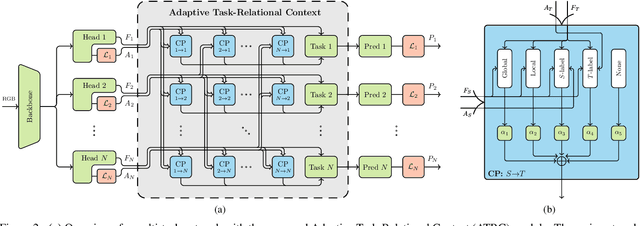
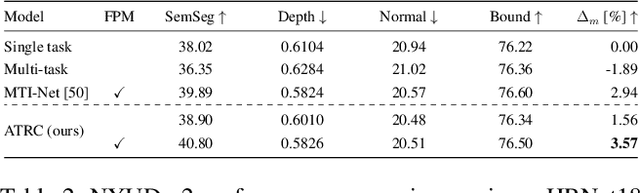
The timeline of computer vision research is marked with advances in learning and utilizing efficient contextual representations. Most of them, however, are targeted at improving model performance on a single downstream task. We consider a multi-task environment for dense prediction tasks, represented by a common backbone and independent task-specific heads. Our goal is to find the most efficient way to refine each task prediction by capturing cross-task contexts dependent on tasks' relations. We explore various attention-based contexts, such as global and local, in the multi-task setting and analyze their behavior when applied to refine each task independently. Empirical findings confirm that different source-target task pairs benefit from different context types. To automate the selection process, we propose an Adaptive Task-Relational Context (ATRC) module, which samples the pool of all available contexts for each task pair using neural architecture search and outputs the optimal configuration for deployment. Our method achieves state-of-the-art performance on two important multi-task benchmarks, namely NYUD-v2 and PASCAL-Context. The proposed ATRC has a low computational toll and can be used as a drop-in refinement module for any supervised multi-task architecture.
Automated Search for Resource-Efficient Branched Multi-Task Networks
Aug 24, 2020
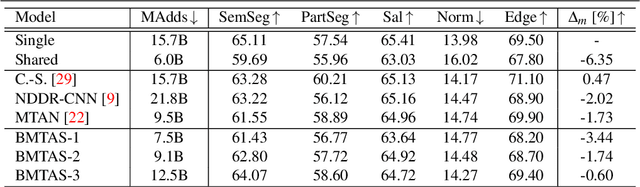

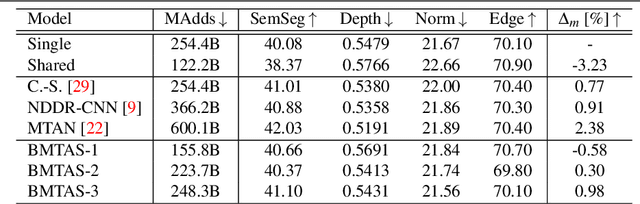
The multi-modal nature of many vision problems calls for neural network architectures that can perform multiple tasks concurrently. Typically, such architectures have been handcrafted in the literature. However, given the size and complexity of the problem, this manual architecture exploration likely exceeds human design abilities. In this paper, we propose a principled approach, rooted in differentiable neural architecture search, to automatically define branching (tree-like) structures in the encoding stage of a multi-task neural network. To allow flexibility within resource-constrained environments, we introduce a proxyless, resource-aware loss that dynamically controls the model size. Evaluations across a variety of dense prediction tasks show that our approach consistently finds high-performing branching structures within limited resource budgets.
Reparameterizing Convolutions for Incremental Multi-Task Learning without Task Interference
Jul 24, 2020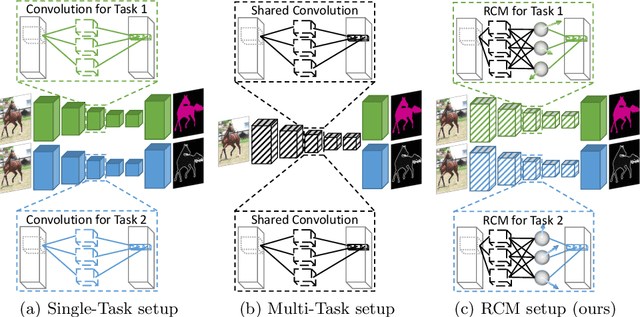

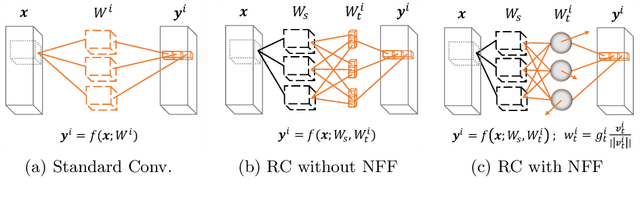
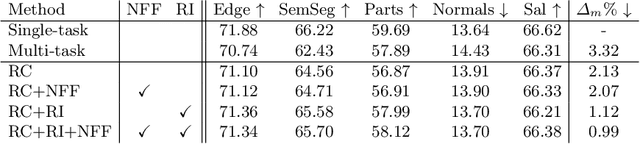
Multi-task networks are commonly utilized to alleviate the need for a large number of highly specialized single-task networks. However, two common challenges in developing multi-task models are often overlooked in literature. First, enabling the model to be inherently incremental, continuously incorporating information from new tasks without forgetting the previously learned ones (incremental learning). Second, eliminating adverse interactions amongst tasks, which has been shown to significantly degrade the single-task performance in a multi-task setup (task interference). In this paper, we show that both can be achieved simply by reparameterizing the convolutions of standard neural network architectures into a non-trainable shared part (filter bank) and task-specific parts (modulators), where each modulator has a fraction of the filter bank parameters. Thus, our reparameterization enables the model to learn new tasks without adversely affecting the performance of existing ones. The results of our ablation study attest the efficacy of the proposed reparameterization. Moreover, our method achieves state-of-the-art on two challenging multi-task learning benchmarks, PASCAL-Context and NYUD, and also demonstrates superior incremental learning capability as compared to its close competitors.