 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoVAR: Co-generation of Video and Action for Robotic Manipulation via Multi-Modal Diffusion
Dec 17, 2025We present a method to generate video-action pairs that follow text instructions, starting from an initial image observation and the robot's joint states. Our approach automatically provides action labels for video diffusion models, overcoming the common lack of action annotations and enabling their full use for robotic policy learning. Existing methods either adopt two-stage pipelines, which limit tightly coupled cross-modal information sharing, or rely on adapting a single-modal diffusion model for a joint distribution that cannot fully leverage pretrained video knowledge. To overcome these limitations, we (1) extend a pretrained video diffusion model with a parallel, dedicated action diffusion model that preserves pretrained knowledge, (2) introduce a Bridge Attention mechanism to enable effective cross-modal interaction, and (3) design an action refinement module to convert coarse actions into precise controls for low-resolution datasets. Extensive evaluations on multiple public benchmarks and real-world datasets demonstrate that our method generates higher-quality videos, more accurate actions, and significantly outperforms existing baselines, offering a scalable framework for leveraging large-scale video data for robotic learning.
DRAW2ACT: Turning Depth-Encoded Trajectories into Robotic Demonstration Videos
Dec 16, 2025Video diffusion models provide powerful real-world simulators for embodied AI but remain limited in controllability for robotic manipulation. Recent works on trajectory-conditioned video generation address this gap but often rely on 2D trajectories or single modality conditioning, which restricts their ability to produce controllable and consistent robotic demonstrations. We present DRAW2ACT, a depth-aware trajectory-conditioned video generation framework that extracts multiple orthogonal representations from the input trajectory, capturing depth, semantics, shape and motion, and injects them into the diffusion model. Moreover, we propose to jointly generate spatially aligned RGB and depth videos, leveraging cross-modality attention mechanisms and depth supervision to enhance the spatio-temporal consistency. Finally, we introduce a multimodal policy model conditioned on the generated RGB and depth sequences to regress the robot's joint angles. Experiments on Bridge V2, Berkeley Autolab, and simulation benchmarks show that DRAW2ACT achieves superior visual fidelity and consistency while yielding higher manipulation success rates compared to existing baselines.
RoboSwap: A GAN-driven Video Diffusion Framework For Unsupervised Robot Arm Swapping
Jun 10, 2025Recent advancements in generative models have revolutionized video synthesis and editing. However, the scarcity of diverse, high-quality datasets continues to hinder video-conditioned robotic learning, limiting cross-platform generalization. In this work, we address the challenge of swapping a robotic arm in one video with another: a key step for crossembodiment learning. Unlike previous methods that depend on paired video demonstrations in the same environmental settings, our proposed framework, RoboSwap, operates on unpaired data from diverse environments, alleviating the data collection needs. RoboSwap introduces a novel video editing pipeline integrating both GANs and diffusion models, combining their isolated advantages. Specifically, we segment robotic arms from their backgrounds and train an unpaired GAN model to translate one robotic arm to another. The translated arm is blended with the original video background and refined with a diffusion model to enhance coherence, motion realism and object interaction. The GAN and diffusion stages are trained independently. Our experiments demonstrate that RoboSwap outperforms state-of-the-art video and image editing models on three benchmarks in terms of both structural coherence and motion consistency, thereby offering a robust solution for generating reliable, cross-embodiment data in robotic learning.
CE-NPBG: Connectivity Enhanced Neural Point-Based Graphics for Novel View Synthesis in Autonomous Driving Scenes
Apr 28, 2025Current point-based approaches encounter limitations in scalability and rendering quality when using large 3D point cloud maps because using them directly for novel view synthesis (NVS) leads to degraded visualizations. We identify the primary issue behind these low-quality renderings as a visibility mismatch between geometry and appearance, stemming from using these two modalities together. To address this problem, we present CE-NPBG, a new approach for novel view synthesis (NVS) in large-scale autonomous driving scenes. Our method is a neural point-based technique that leverages two modalities: posed images (cameras) and synchronized raw 3D point clouds (LiDAR). We first employ a connectivity relationship graph between appearance and geometry, which retrieves points from a large 3D point cloud map observed from the current camera perspective and uses them for rendering. By leveraging this connectivity, our method significantly improves rendering quality and enhances run-time and scalability by using only a small subset of points from the large 3D point cloud map. Our approach associates neural descriptors with the points and uses them to synthesize views. To enhance the encoding of these descriptors and elevate rendering quality, we propose a joint adversarial and point rasterization training. During training, we pair an image-synthesizer network with a multi-resolution discriminator. At inference, we decouple them and use the image-synthesizer to generate novel views. We also integrate our proposal into the recent 3D Gaussian Splatting work to highlight its benefits for improved rendering and scalability.
ControlUDA: Controllable Diffusion-assisted Unsupervised Domain Adaptation for Cross-Weather Semantic Segmentation
Feb 09, 2024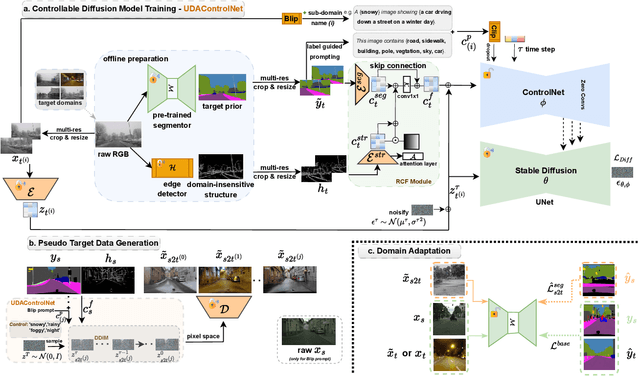



Data generation is recognized as a potent strategy for unsupervised domain adaptation (UDA) pertaining semantic segmentation in adverse weathers. Nevertheless, these adverse weather scenarios encompass multiple possibilities, and high-fidelity data synthesis with controllable weather is under-researched in previous UDA works. The recent strides in large-scale text-to-image diffusion models (DM) have ushered in a novel avenue for research, enabling the generation of realistic images conditioned on semantic labels. This capability proves instrumental for cross-domain data synthesis from source to target domain owing to their shared label space. Thus, source domain labels can be paired with those generated pseudo target data for training UDA. However, from the UDA perspective, there exists several challenges for DM training: (i) ground-truth labels from target domain are missing; (ii) the prompt generator may produce vague or noisy descriptions of images from adverse weathers; (iii) existing arts often struggle to well handle the complex scene structure and geometry of urban scenes when conditioned only on semantic labels. To tackle the above issues, we propose ControlUDA, a diffusion-assisted framework tailored for UDA segmentation under adverse weather conditions. It first leverages target prior from a pre-trained segmentor for tuning the DM, compensating the missing target domain labels; It also contains UDAControlNet, a condition-fused multi-scale and prompt-enhanced network targeted at high-fidelity data generation in adverse weathers. Training UDA with our generated data brings the model performances to a new milestone (72.0 mIoU) on the popular Cityscapes-to-ACDC benchmark for adverse weathers. Furthermore, ControlUDA helps to achieve good model generalizability on unseen data.
Long-Term Invariant Local Features via Implicit Cross-Domain Correspondences
Nov 06, 2023



Modern learning-based visual feature extraction networks perform well in intra-domain localization, however, their performance significantly declines when image pairs are captured across long-term visual domain variations, such as different seasonal and daytime variations. In this paper, our first contribution is a benchmark to investigate the performance impact of long-term variations on visual localization. We conduct a thorough analysis of the performance of current state-of-the-art feature extraction networks under various domain changes and find a significant performance gap between intra- and cross-domain localization. We investigate different methods to close this gap by improving the supervision of modern feature extractor networks. We propose a novel data-centric method, Implicit Cross-Domain Correspondences (iCDC). iCDC represents the same environment with multiple Neural Radiance Fields, each fitting the scene under individual visual domains. It utilizes the underlying 3D representations to generate accurate correspondences across different long-term visual conditions. Our proposed method enhances cross-domain localization performance, significantly reducing the performance gap. When evaluated on popular long-term localization benchmarks, our trained networks consistently outperform existing methods. This work serves as a substantial stride toward more robust visual localization pipelines for long-term deployments, and opens up research avenues in the development of long-term invariant descriptors.
DiGA: Distil to Generalize and then Adapt for Domain Adaptive Semantic Segmentation
Apr 05, 2023



Domain adaptive semantic segmentation methods commonly utilize stage-wise training, consisting of a warm-up and a self-training stage. However, this popular approach still faces several challenges in each stage: for warm-up, the widely adopted adversarial training often results in limited performance gain, due to blind feature alignment; for self-training, finding proper categorical thresholds is very tricky. To alleviate these issues, we first propose to replace the adversarial training in the warm-up stage by a novel symmetric knowledge distillation module that only accesses the source domain data and makes the model domain generalizable. Surprisingly, this domain generalizable warm-up model brings substantial performance improvement, which can be further amplified via our proposed cross-domain mixture data augmentation technique. Then, for the self-training stage, we propose a threshold-free dynamic pseudo-label selection mechanism to ease the aforementioned threshold problem and make the model better adapted to the target domain. Extensive experiments demonstrate that our framework achieves remarkable and consistent improvements compared to the prior arts on popular benchmarks. Codes and models are available at https://github.com/fy-vision/DiGA
* CVPR2023
LoopDA: Constructing Self-loops to Adapt Nighttime Semantic Segmentation
Nov 21, 2022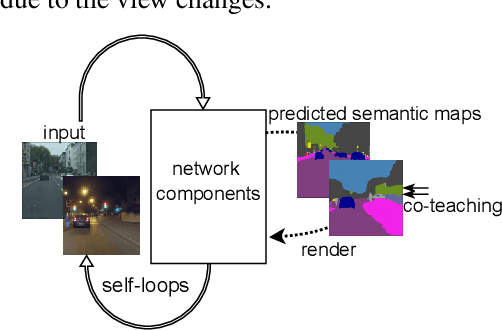
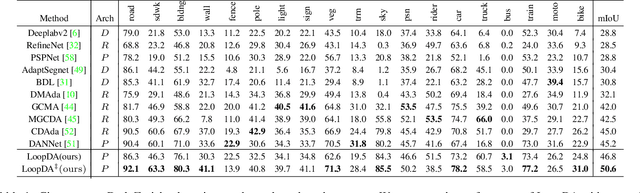
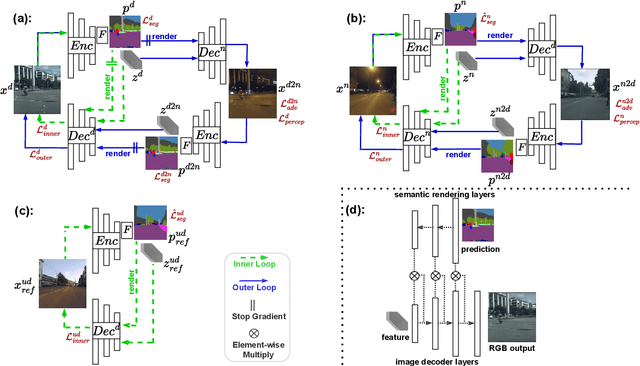
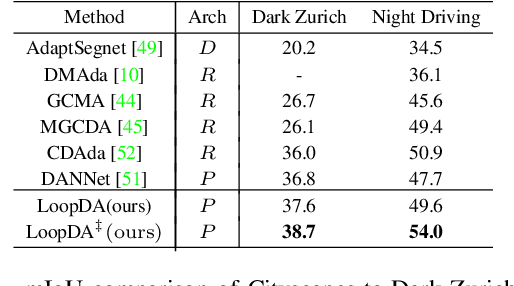
Due to the lack of training labels and the difficulty of annotating, dealing with adverse driving conditions such as nighttime has posed a huge challenge to the perception system of autonomous vehicles. Therefore, adapting knowledge from a labelled daytime domain to an unlabelled nighttime domain has been widely researched. In addition to labelled daytime datasets, existing nighttime datasets usually provide nighttime images with corresponding daytime reference images captured at nearby locations for reference. The key challenge is to minimize the performance gap between the two domains. In this paper, we propose LoopDA for domain adaptive nighttime semantic segmentation. It consists of self-loops that result in reconstructing the input data using predicted semantic maps, by rendering them into the encoded features. In a warm-up training stage, the self-loops comprise of an inner-loop and an outer-loop, which are responsible for intra-domain refinement and inter-domain alignment, respectively. To reduce the impact of day-night pose shifts, in the later self-training stage, we propose a co-teaching pipeline that involves an offline pseudo-supervision signal and an online reference-guided signal `DNA' (Day-Night Agreement), bringing substantial benefits to enhance nighttime segmentation. Our model outperforms prior methods on Dark Zurich and Nighttime Driving datasets for semantic segmentation. Code and pretrained models are available at https://github.com/fy-vision/LoopDA.
* Accepted to WACV2023
TridentAdapt: Learning Domain-invariance via Source-Target Confrontation and Self-induced Cross-domain Augmentation
Nov 30, 2021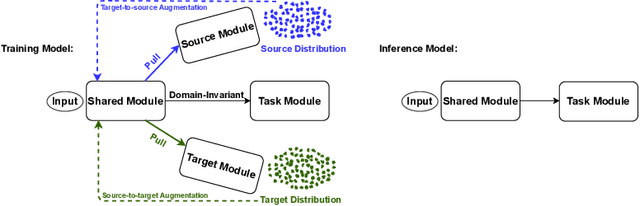
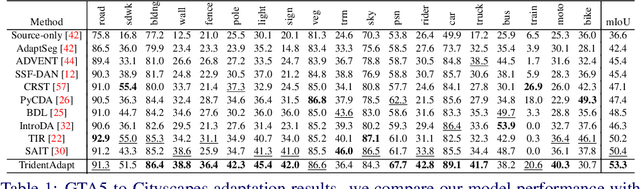
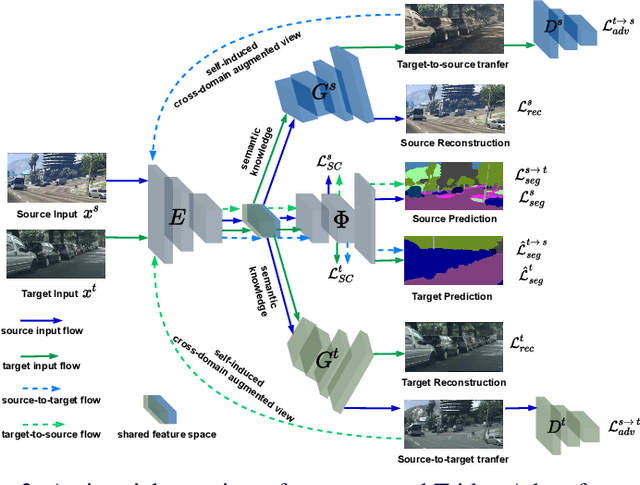
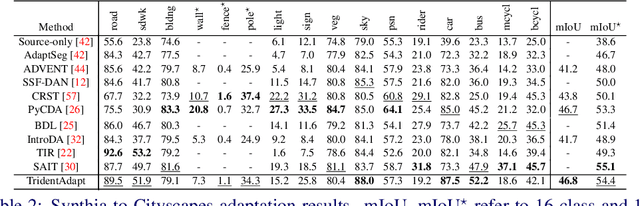
Due to the difficulty of obtaining ground-truth labels, learning from virtual-world datasets is of great interest for real-world applications like semantic segmentation. From domain adaptation perspective, the key challenge is to learn domain-agnostic representation of the inputs in order to benefit from virtual data. In this paper, we propose a novel trident-like architecture that enforces a shared feature encoder to satisfy confrontational source and target constraints simultaneously, thus learning a domain-invariant feature space. Moreover, we also introduce a novel training pipeline enabling self-induced cross-domain data augmentation during the forward pass. This contributes to a further reduction of the domain gap. Combined with a self-training process, we obtain state-of-the-art results on benchmark datasets (e.g. GTA5 or Synthia to Cityscapes adaptation). Code and pre-trained models are available at https://github.com/HMRC-AEL/TridentAdapt
Monocular Depth Estimation through Virtual-world Supervision and Real-world SfM Self-Supervision
Mar 22, 2021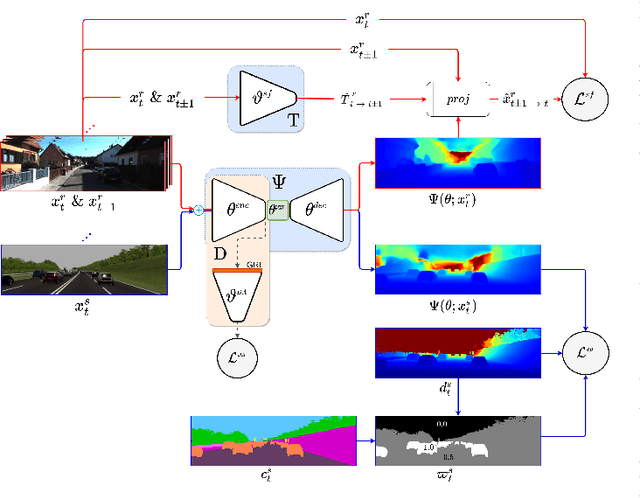
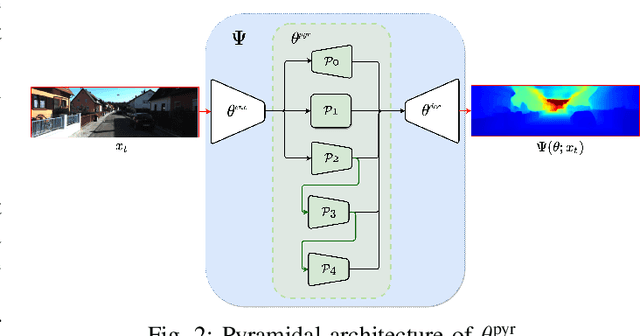
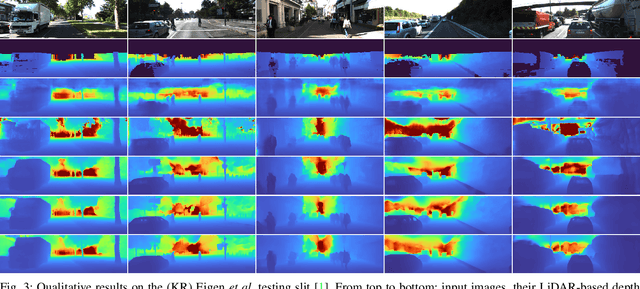
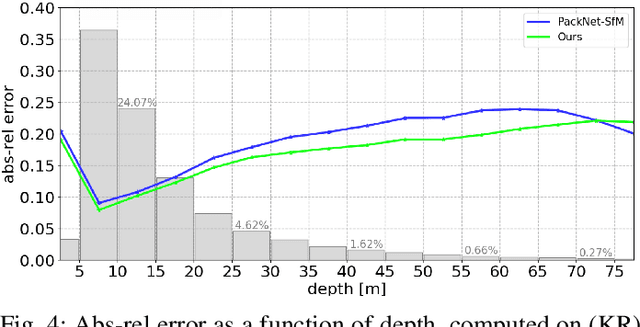
Depth information is essential for on-board perception in autonomous driving and driver assistance. Monocular depth estimation (MDE) is very appealing since it allows for appearance and depth being on direct pixelwise correspondence without further calibration. Best MDE models are based on Convolutional Neural Networks (CNNs) trained in a supervised manner, i.e., assuming pixelwise ground truth (GT). Usually, this GT is acquired at training time through a calibrated multi-modal suite of sensors. However, also using only a monocular system at training time is cheaper and more scalable. This is possible by relying on structure-from-motion (SfM) principles to generate self-supervision. Nevertheless, problems of camouflaged objects, visibility changes, static-camera intervals, textureless areas, and scale ambiguity, diminish the usefulness of such self-supervision. In this paper, we perform monocular depth estimation by virtual-world supervision (MonoDEVS) and real-world SfM self-supervision. We compensate the SfM self-supervision limitations by leveraging virtual-world images with accurate semantic and depth supervision and addressing the virtual-to-real domain gap. Our MonoDEVSNet outperforms previous MDE CNNs trained on monocular and even stereo sequences.