 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMP-SfM: Monocular Surface Priors for Robust Structure-from-Motion
Apr 28, 2025While Structure-from-Motion (SfM) has seen much progress over the years, state-of-the-art systems are prone to failure when facing extreme viewpoint changes in low-overlap, low-parallax or high-symmetry scenarios. Because capturing images that avoid these pitfalls is challenging, this severely limits the wider use of SfM, especially by non-expert users. We overcome these limitations by augmenting the classical SfM paradigm with monocular depth and normal priors inferred by deep neural networks. Thanks to a tight integration of monocular and multi-view constraints, our approach significantly outperforms existing ones under extreme viewpoint changes, while maintaining strong performance in standard conditions. We also show that monocular priors can help reject faulty associations due to symmetries, which is a long-standing problem for SfM. This makes our approach the first capable of reliably reconstructing challenging indoor environments from few images. Through principled uncertainty propagation, it is robust to errors in the priors, can handle priors inferred by different models with little tuning, and will thus easily benefit from future progress in monocular depth and normal estimation. Our code is publicly available at https://github.com/cvg/mpsfm.
Multi Activity Sequence Alignment via Implicit Clustering
Mar 16, 2025Self-supervised temporal sequence alignment can provide rich and effective representations for a wide range of applications. However, existing methods for achieving optimal performance are mostly limited to aligning sequences of the same activity only and require separate models to be trained for each activity. We propose a novel framework that overcomes these limitations using sequence alignment via implicit clustering. Specifically, our key idea is to perform implicit clip-level clustering while aligning frames in sequences. This coupled with our proposed dual augmentation technique enhances the network's ability to learn generalizable and discriminative representations. Our experiments show that our proposed method outperforms state-of-the-art results and highlight the generalization capability of our framework with multi activity and different modalities on three diverse datasets, H2O, PennAction, and IKEA ASM. We will release our code upon acceptance.
Global Localization: Utilizing Relative Spatio-Temporal Geometric Constraints from Adjacent and Distant Cameras
Dec 01, 2023



Re-localizing a camera from a single image in a previously mapped area is vital for many computer vision applications in robotics and augmented/virtual reality. In this work, we address the problem of estimating the 6 DoF camera pose relative to a global frame from a single image. We propose to leverage a novel network of relative spatial and temporal geometric constraints to guide the training of a Deep Network for localization. We employ simultaneously spatial and temporal relative pose constraints that are obtained not only from adjacent camera frames but also from camera frames that are distant in the spatio-temporal space of the scene. We show that our method, through these constraints, is capable of learning to localize when little or very sparse ground-truth 3D coordinates are available. In our experiments, this is less than 1% of available ground-truth data. We evaluate our method on 3 common visual localization datasets and show that it outperforms other direct pose estimation methods.
Long-Term Invariant Local Features via Implicit Cross-Domain Correspondences
Nov 06, 2023



Modern learning-based visual feature extraction networks perform well in intra-domain localization, however, their performance significantly declines when image pairs are captured across long-term visual domain variations, such as different seasonal and daytime variations. In this paper, our first contribution is a benchmark to investigate the performance impact of long-term variations on visual localization. We conduct a thorough analysis of the performance of current state-of-the-art feature extraction networks under various domain changes and find a significant performance gap between intra- and cross-domain localization. We investigate different methods to close this gap by improving the supervision of modern feature extractor networks. We propose a novel data-centric method, Implicit Cross-Domain Correspondences (iCDC). iCDC represents the same environment with multiple Neural Radiance Fields, each fitting the scene under individual visual domains. It utilizes the underlying 3D representations to generate accurate correspondences across different long-term visual conditions. Our proposed method enhances cross-domain localization performance, significantly reducing the performance gap. When evaluated on popular long-term localization benchmarks, our trained networks consistently outperform existing methods. This work serves as a substantial stride toward more robust visual localization pipelines for long-term deployments, and opens up research avenues in the development of long-term invariant descriptors.
LoopDA: Constructing Self-loops to Adapt Nighttime Semantic Segmentation
Nov 21, 2022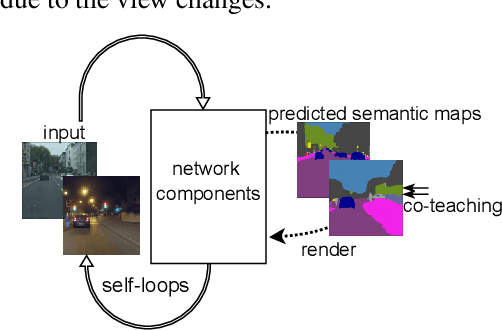
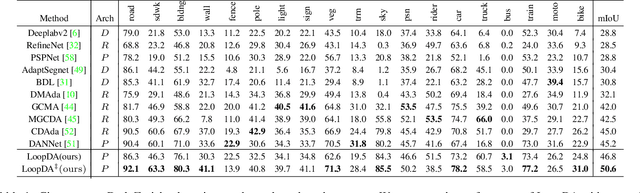
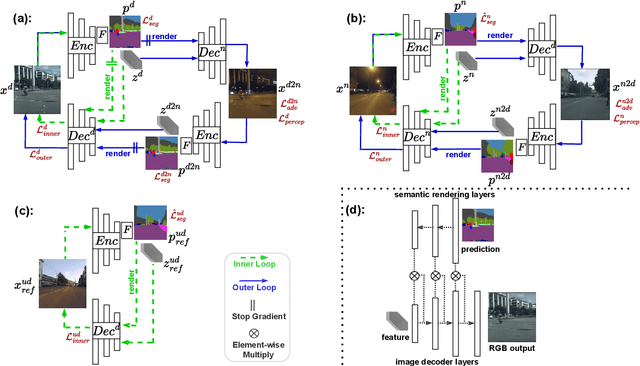
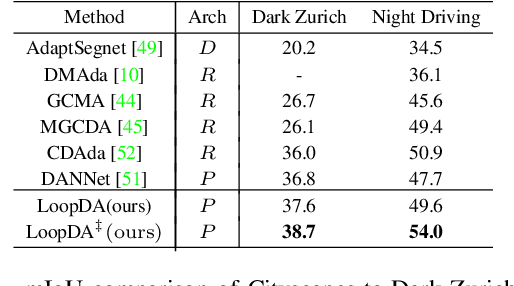
Due to the lack of training labels and the difficulty of annotating, dealing with adverse driving conditions such as nighttime has posed a huge challenge to the perception system of autonomous vehicles. Therefore, adapting knowledge from a labelled daytime domain to an unlabelled nighttime domain has been widely researched. In addition to labelled daytime datasets, existing nighttime datasets usually provide nighttime images with corresponding daytime reference images captured at nearby locations for reference. The key challenge is to minimize the performance gap between the two domains. In this paper, we propose LoopDA for domain adaptive nighttime semantic segmentation. It consists of self-loops that result in reconstructing the input data using predicted semantic maps, by rendering them into the encoded features. In a warm-up training stage, the self-loops comprise of an inner-loop and an outer-loop, which are responsible for intra-domain refinement and inter-domain alignment, respectively. To reduce the impact of day-night pose shifts, in the later self-training stage, we propose a co-teaching pipeline that involves an offline pseudo-supervision signal and an online reference-guided signal `DNA' (Day-Night Agreement), bringing substantial benefits to enhance nighttime segmentation. Our model outperforms prior methods on Dark Zurich and Nighttime Driving datasets for semantic segmentation. Code and pretrained models are available at https://github.com/fy-vision/LoopDA.
* Accepted to WACV2023