 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiGA: Distil to Generalize and then Adapt for Domain Adaptive Semantic Segmentation
Apr 05, 2023



Domain adaptive semantic segmentation methods commonly utilize stage-wise training, consisting of a warm-up and a self-training stage. However, this popular approach still faces several challenges in each stage: for warm-up, the widely adopted adversarial training often results in limited performance gain, due to blind feature alignment; for self-training, finding proper categorical thresholds is very tricky. To alleviate these issues, we first propose to replace the adversarial training in the warm-up stage by a novel symmetric knowledge distillation module that only accesses the source domain data and makes the model domain generalizable. Surprisingly, this domain generalizable warm-up model brings substantial performance improvement, which can be further amplified via our proposed cross-domain mixture data augmentation technique. Then, for the self-training stage, we propose a threshold-free dynamic pseudo-label selection mechanism to ease the aforementioned threshold problem and make the model better adapted to the target domain. Extensive experiments demonstrate that our framework achieves remarkable and consistent improvements compared to the prior arts on popular benchmarks. Codes and models are available at https://github.com/fy-vision/DiGA
* CVPR2023
On the Metrics for Evaluating Monocular Depth Estimation
Feb 20, 2023



Monocular Depth Estimation (MDE) is performed to produce 3D information that can be used in downstream tasks such as those related to on-board perception for Autonomous Vehicles (AVs) or driver assistance. Therefore, a relevant arising question is whether the standard metrics for MDE assessment are a good indicator of the accuracy of future MDE-based driving-related perception tasks. We address this question in this paper. In particular, we take the task of 3D object detection on point clouds as a proxy of on-board perception. We train and test state-of-the-art 3D object detectors using 3D point clouds coming from MDE models. We confront the ranking of object detection results with the ranking given by the depth estimation metrics of the MDE models. We conclude that, indeed, MDE evaluation metrics give rise to a ranking of methods that reflects relatively well the 3D object detection results we may expect. Among the different metrics, the absolute relative (abs-rel) error seems to be the best for that purpose.
LoopDA: Constructing Self-loops to Adapt Nighttime Semantic Segmentation
Nov 21, 2022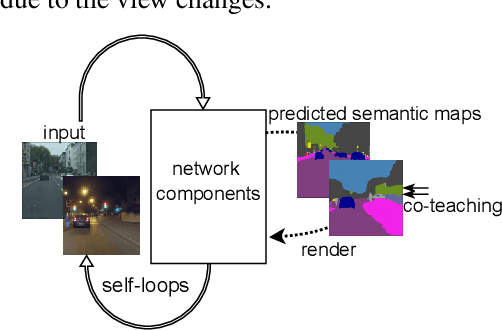
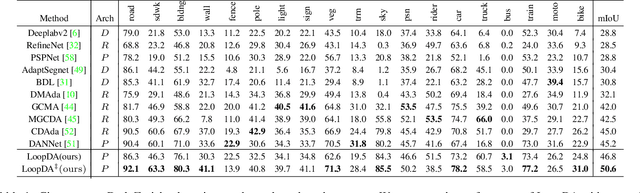
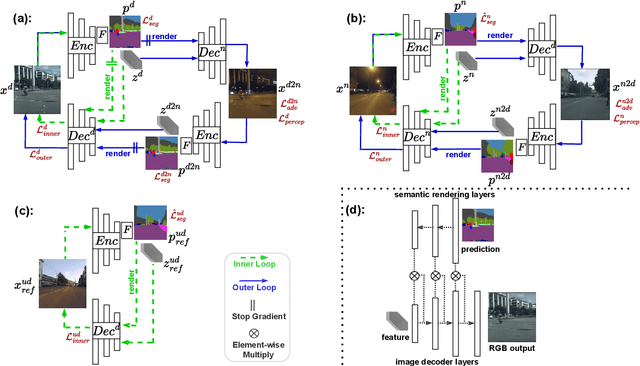
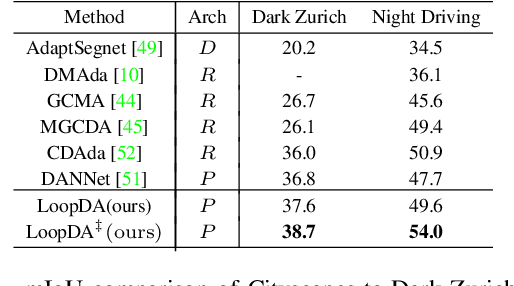
Due to the lack of training labels and the difficulty of annotating, dealing with adverse driving conditions such as nighttime has posed a huge challenge to the perception system of autonomous vehicles. Therefore, adapting knowledge from a labelled daytime domain to an unlabelled nighttime domain has been widely researched. In addition to labelled daytime datasets, existing nighttime datasets usually provide nighttime images with corresponding daytime reference images captured at nearby locations for reference. The key challenge is to minimize the performance gap between the two domains. In this paper, we propose LoopDA for domain adaptive nighttime semantic segmentation. It consists of self-loops that result in reconstructing the input data using predicted semantic maps, by rendering them into the encoded features. In a warm-up training stage, the self-loops comprise of an inner-loop and an outer-loop, which are responsible for intra-domain refinement and inter-domain alignment, respectively. To reduce the impact of day-night pose shifts, in the later self-training stage, we propose a co-teaching pipeline that involves an offline pseudo-supervision signal and an online reference-guided signal `DNA' (Day-Night Agreement), bringing substantial benefits to enhance nighttime segmentation. Our model outperforms prior methods on Dark Zurich and Nighttime Driving datasets for semantic segmentation. Code and pretrained models are available at https://github.com/fy-vision/LoopDA.
* Accepted to WACV2023
TridentAdapt: Learning Domain-invariance via Source-Target Confrontation and Self-induced Cross-domain Augmentation
Nov 30, 2021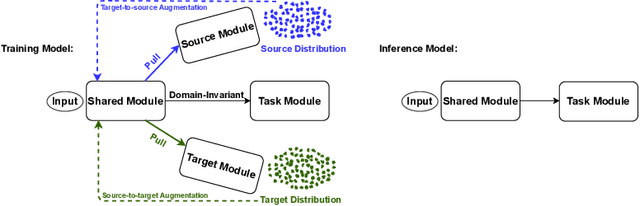
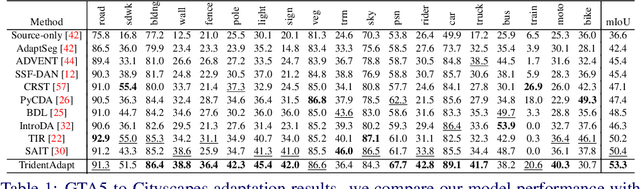
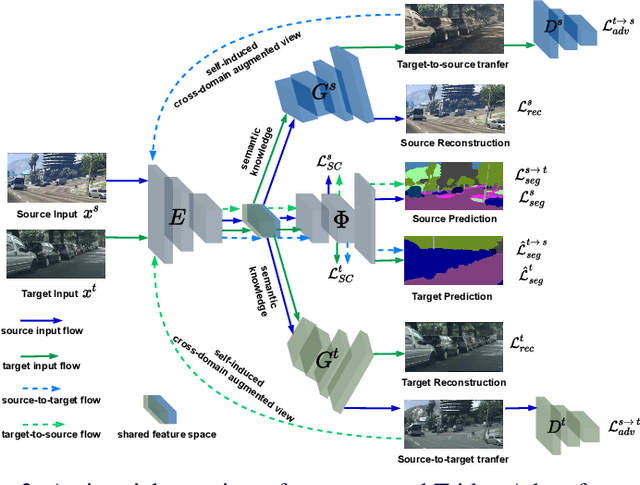
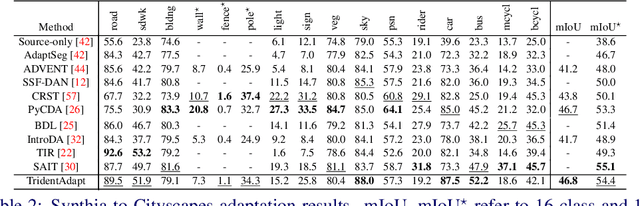
Due to the difficulty of obtaining ground-truth labels, learning from virtual-world datasets is of great interest for real-world applications like semantic segmentation. From domain adaptation perspective, the key challenge is to learn domain-agnostic representation of the inputs in order to benefit from virtual data. In this paper, we propose a novel trident-like architecture that enforces a shared feature encoder to satisfy confrontational source and target constraints simultaneously, thus learning a domain-invariant feature space. Moreover, we also introduce a novel training pipeline enabling self-induced cross-domain data augmentation during the forward pass. This contributes to a further reduction of the domain gap. Combined with a self-training process, we obtain state-of-the-art results on benchmark datasets (e.g. GTA5 or Synthia to Cityscapes adaptation). Code and pre-trained models are available at https://github.com/HMRC-AEL/TridentAdapt
Monocular Depth Estimation through Virtual-world Supervision and Real-world SfM Self-Supervision
Mar 22, 2021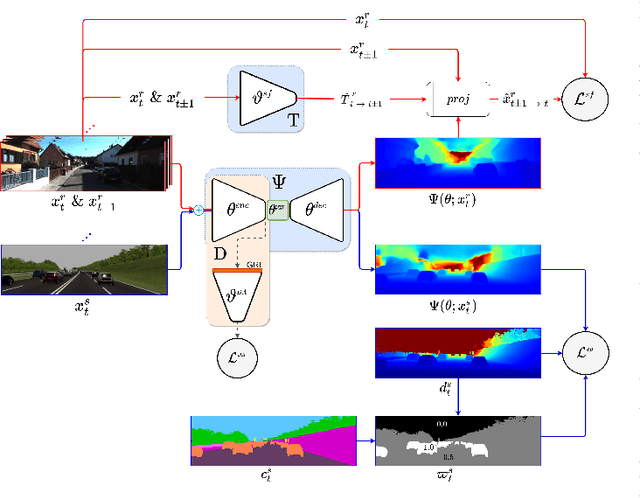
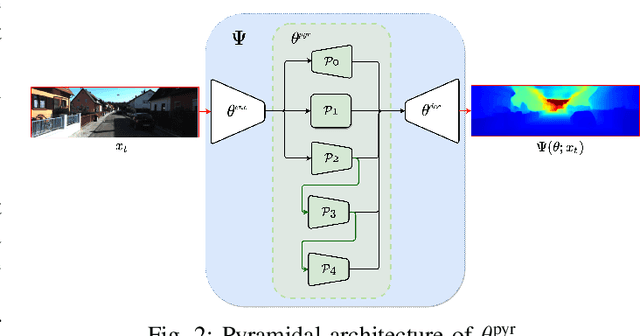
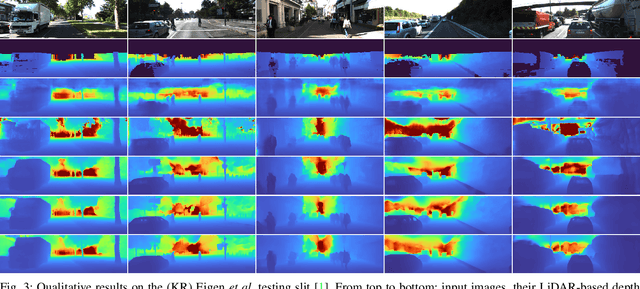
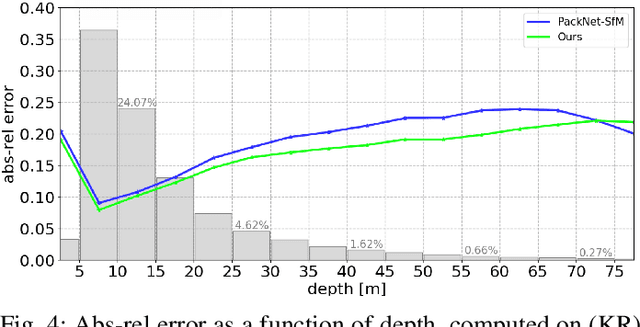
Depth information is essential for on-board perception in autonomous driving and driver assistance. Monocular depth estimation (MDE) is very appealing since it allows for appearance and depth being on direct pixelwise correspondence without further calibration. Best MDE models are based on Convolutional Neural Networks (CNNs) trained in a supervised manner, i.e., assuming pixelwise ground truth (GT). Usually, this GT is acquired at training time through a calibrated multi-modal suite of sensors. However, also using only a monocular system at training time is cheaper and more scalable. This is possible by relying on structure-from-motion (SfM) principles to generate self-supervision. Nevertheless, problems of camouflaged objects, visibility changes, static-camera intervals, textureless areas, and scale ambiguity, diminish the usefulness of such self-supervision. In this paper, we perform monocular depth estimation by virtual-world supervision (MonoDEVS) and real-world SfM self-supervision. We compensate the SfM self-supervision limitations by leveraging virtual-world images with accurate semantic and depth supervision and addressing the virtual-to-real domain gap. Our MonoDEVSNet outperforms previous MDE CNNs trained on monocular and even stereo sequences.
Multimodal End-to-End Autonomous Driving
Jun 07, 2019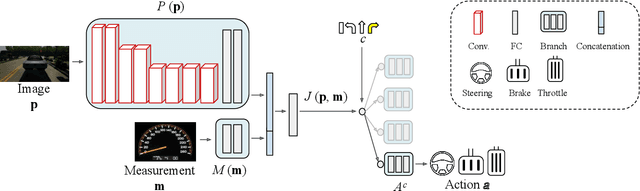
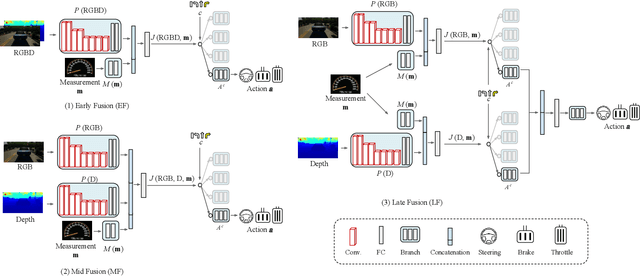

Autonomous vehicles (AVs) are key for the intelligent mobility of the future. A crucial component of an AV is the artificial intelligence (AI) able to drive towards a desired destination. Today, there are different paradigms addressing the development of AI drivers. On the one hand, we find modular pipelines, which divide the driving task into sub-tasks such as perception (object detection, semantic segmentation, depth estimation, tracking) and maneuver control (local path planing and control). On the other hand, we find end-to-end driving approaches that try to learn a direct mapping from input raw sensor data to vehicle control signals (the steering angle). The later are relatively less studied, but are gaining popularity since they are less demanding in terms of sensor data annotation. This paper focuses on end-to-end autonomous driving. So far, most proposals relying on this paradigm assume RGB images as input sensor data. However, AVs will not be equipped only with cameras, but also with active sensors providing accurate depth information (traditional LiDARs, or new solid state ones). Accordingly, this paper analyses if RGB and depth data, RGBD data, can actually act as complementary information in a multimodal end-to-end driving approach, producing a better AI driver. Using the CARLA simulator functionalities, its standard benchmark, and conditional imitation learning (CIL), we will show how, indeed, RGBD gives rise to more successful end-to-end AI drivers. We will compare the use of RGBD information by means of early, mid and late fusion schemes, both in multisensory and single-sensor (monocular depth estimation) settings.
Monocular Depth Estimation by Learning from Heterogeneous Datasets
Sep 12, 2018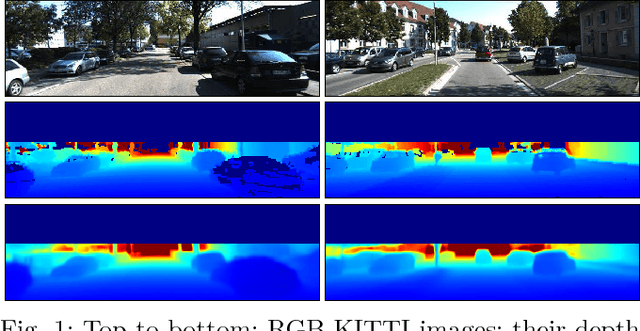
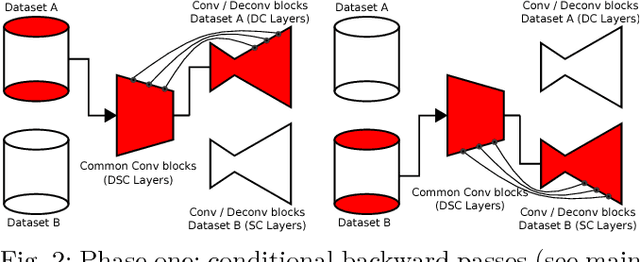
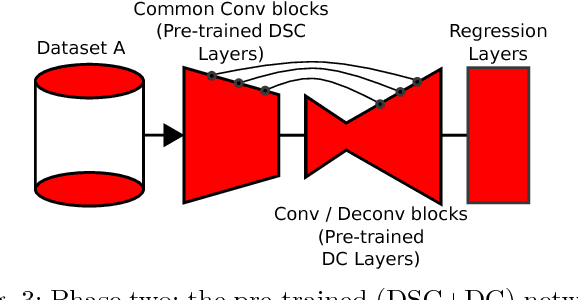
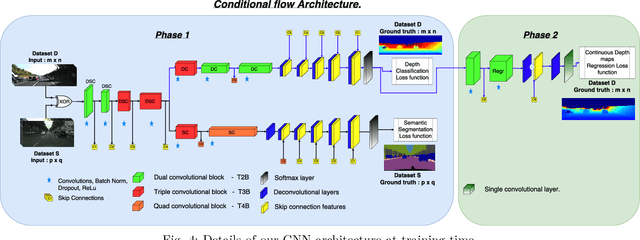
Depth estimation provides essential information to perform autonomous driving and driver assistance. Especially, Monocular Depth Estimation is interesting from a practical point of view, since using a single camera is cheaper than many other options and avoids the need for continuous calibration strategies as required by stereo-vision approaches. State-of-the-art methods for Monocular Depth Estimation are based on Convolutional Neural Networks (CNNs). A promising line of work consists of introducing additional semantic information about the traffic scene when training CNNs for depth estimation. In practice, this means that the depth data used for CNN training is complemented with images having pixel-wise semantic labels, which usually are difficult to annotate (e.g. crowded urban images). Moreover, so far it is common practice to assume that the same raw training data is associated with both types of ground truth, i.e., depth and semantic labels. The main contribution of this paper is to show that this hard constraint can be circumvented, i.e., that we can train CNNs for depth estimation by leveraging the depth and semantic information coming from heterogeneous datasets. In order to illustrate the benefits of our approach, we combine KITTI depth and Cityscapes semantic segmentation datasets, outperforming state-of-the-art results on Monocular Depth Estimation.