 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Depth Estimation by Learning from Heterogeneous Datasets
Paper and Code
Sep 12, 2018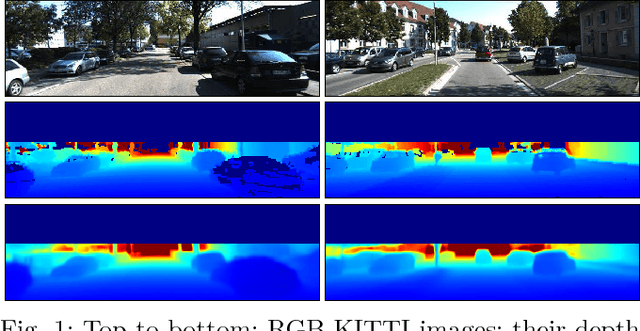
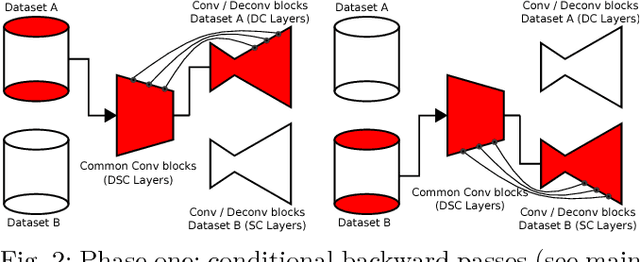
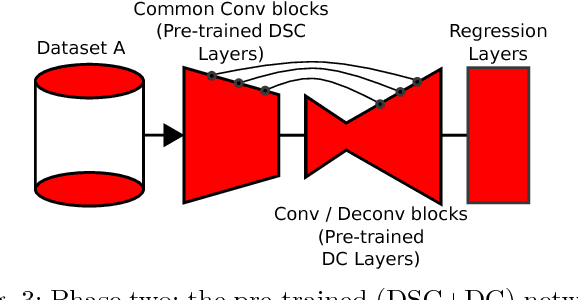
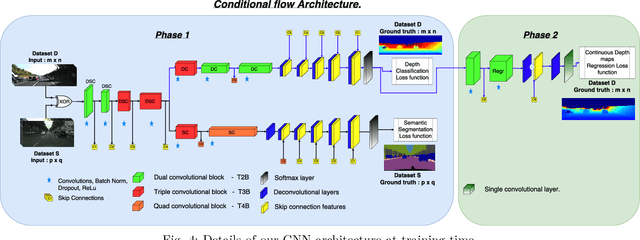
Depth estimation provides essential information to perform autonomous driving and driver assistance. Especially, Monocular Depth Estimation is interesting from a practical point of view, since using a single camera is cheaper than many other options and avoids the need for continuous calibration strategies as required by stereo-vision approaches. State-of-the-art methods for Monocular Depth Estimation are based on Convolutional Neural Networks (CNNs). A promising line of work consists of introducing additional semantic information about the traffic scene when training CNNs for depth estimation. In practice, this means that the depth data used for CNN training is complemented with images having pixel-wise semantic labels, which usually are difficult to annotate (e.g. crowded urban images). Moreover, so far it is common practice to assume that the same raw training data is associated with both types of ground truth, i.e., depth and semantic labels. The main contribution of this paper is to show that this hard constraint can be circumvented, i.e., that we can train CNNs for depth estimation by leveraging the depth and semantic information coming from heterogeneous datasets. In order to illustrate the benefits of our approach, we combine KITTI depth and Cityscapes semantic segmentation datasets, outperforming state-of-the-art results on Monocular Depth Estimation.