 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Beyond Corners: Contrastive Learning of Visual Representations for Keypoint Detection and Description Extraction
Dec 22, 2021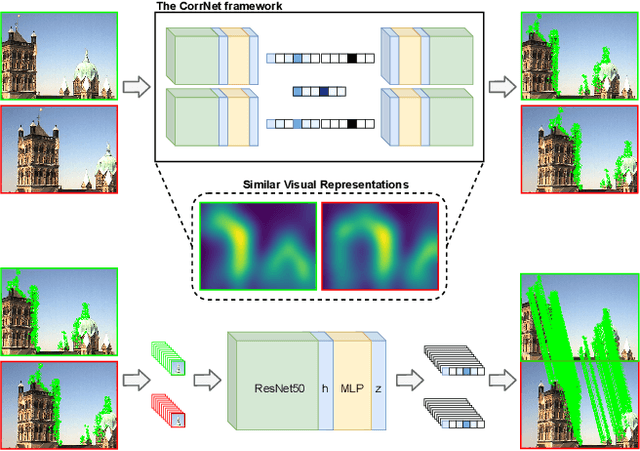
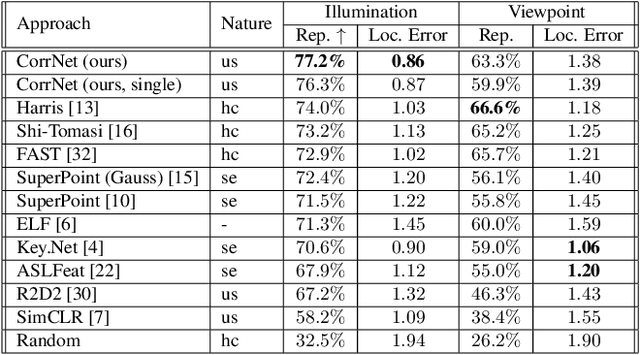

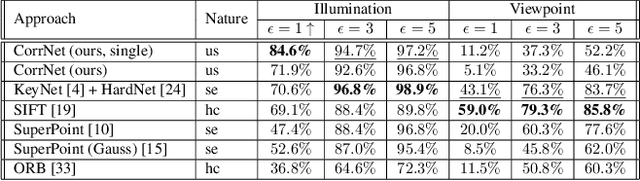
Learnable keypoint detectors and descriptors are beginning to outperform classical hand-crafted feature extraction methods. Recent studies on self-supervised learning of visual representations have driven the increasing performance of learnable models based on deep networks. By leveraging traditional data augmentations and homography transformations, these networks learn to detect corners under adverse conditions such as extreme illumination changes. However, their generalization capabilities are limited to corner-like features detected a priori by classical methods or synthetically generated data. In this paper, we propose the Correspondence Network (CorrNet) that learns to detect repeatable keypoints and to extract discriminative descriptions via unsupervised contrastive learning under spatial constraints. Our experiments show that CorrNet is not only able to detect low-level features such as corners, but also high-level features that represent similar objects present in a pair of input images through our proposed joint guided backpropagation of their latent space. Our approach obtains competitive results under viewpoint changes and achieves state-of-the-art performance under illumination changes.
Real-Time Lane ID Estimation Using Recurrent Neural Networks With Dual Convention
Jan 14, 2020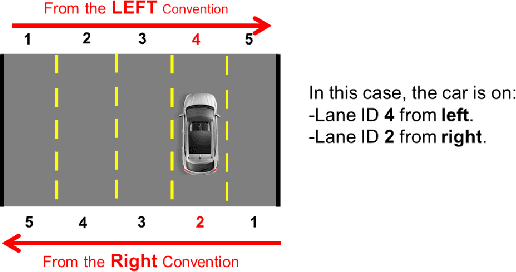
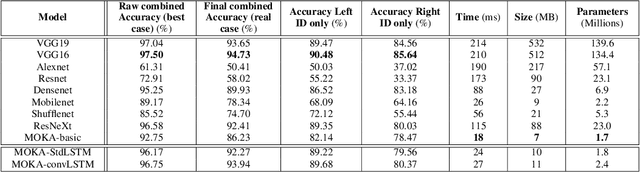
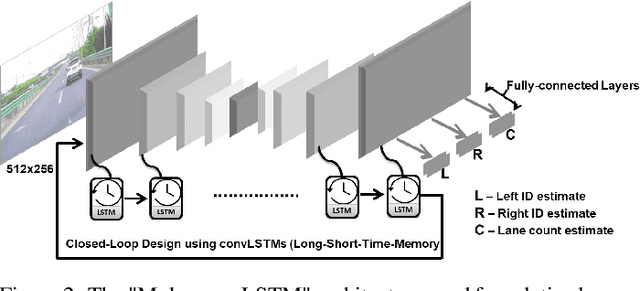
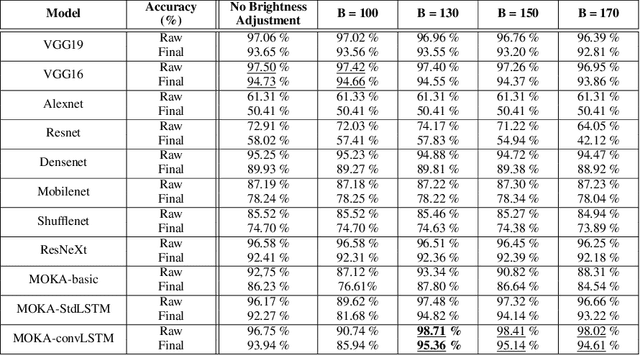
Acquiring information about the road lane structure is a crucial step for autonomous navigation. To this end, several approaches tackle this task from different perspectives such as lane marking detection or semantic lane segmentation. However, to the best of our knowledge, there is yet no purely vision based end-to-end solution to answer the precise question: How to estimate the relative number or "ID" of the current driven lane within a multi-lane road or a highway? In this work, we propose a real-time, vision-only (i.e. monocular camera) solution to the problem based on a dual left-right convention. We interpret this task as a classification problem by limiting the maximum number of lane candidates to eight. Our approach is designed to meet low-complexity specifications and limited runtime requirements. It harnesses the temporal dimension inherent to the input sequences to improve upon high-complexity state-of-the-art models. We achieve more than 95% accuracy on a challenging test set with extreme conditions and different routes.
Monocular Depth Estimation by Learning from Heterogeneous Datasets
Sep 12, 2018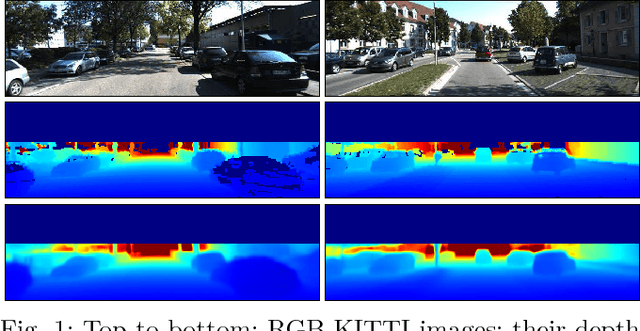
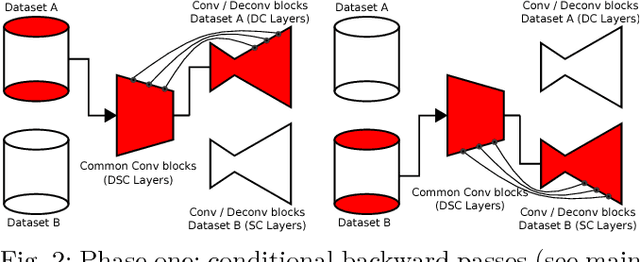
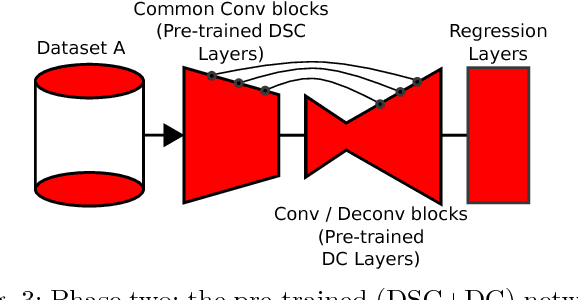
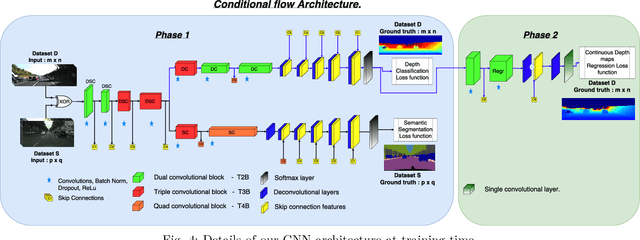
Depth estimation provides essential information to perform autonomous driving and driver assistance. Especially, Monocular Depth Estimation is interesting from a practical point of view, since using a single camera is cheaper than many other options and avoids the need for continuous calibration strategies as required by stereo-vision approaches. State-of-the-art methods for Monocular Depth Estimation are based on Convolutional Neural Networks (CNNs). A promising line of work consists of introducing additional semantic information about the traffic scene when training CNNs for depth estimation. In practice, this means that the depth data used for CNN training is complemented with images having pixel-wise semantic labels, which usually are difficult to annotate (e.g. crowded urban images). Moreover, so far it is common practice to assume that the same raw training data is associated with both types of ground truth, i.e., depth and semantic labels. The main contribution of this paper is to show that this hard constraint can be circumvented, i.e., that we can train CNNs for depth estimation by leveraging the depth and semantic information coming from heterogeneous datasets. In order to illustrate the benefits of our approach, we combine KITTI depth and Cityscapes semantic segmentation datasets, outperforming state-of-the-art results on Monocular Depth Estimation.
Learnable Exposure Fusion for Dynamic Scenes
Apr 04, 2018
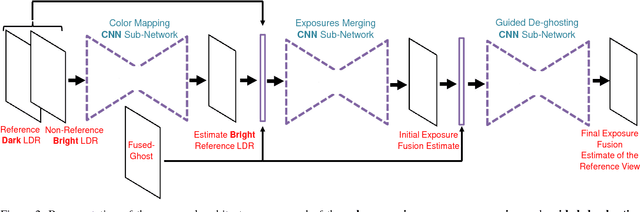


In this paper, we focus on Exposure Fusion (EF) [ExposFusi2] for dynamic scenes. The task is to fuse multiple images obtained by exposure bracketing to create an image which comprises a high level of details. Typically, such images are not possible to obtain directly from a camera due to hardware limitations, e.g., a limited dynamic range of the sensor. A major problem of such tasks is that the images may not be spatially aligned due to scene motion or camera motion. It is known that the required alignment by image registration problems is ill-posed. In this case, the images to be aligned vary in their intensity range, which makes the problem even more difficult. To address the mentioned problems, we propose an end-to-end \emph{Convolutional Neural Network} (CNN) based approach to learn to estimate exposure fusion from $2$ and $3$ Low Dynamic Range (LDR) images depicting different scene contents. To the best of our knowledge, no efficient and robust CNN-based end-to-end approach can be found in the literature for this kind of problem. The idea is to create a dataset with perfectly aligned LDR images to obtain ground-truth exposure fusion images. At the same time, we obtain additional LDR images with some motion, having the same exposure fusion ground-truth as the perfectly aligned LDR images. This way, we can train an end-to-end CNN having misaligned LDR input images, but with a proper ground truth exposure fusion image. We propose a specific CNN-architecture to solve this problem. In various experiments, we show that the proposed approach yields excellent results.