 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2N2V2: Multi-Modal Unsupervised and Training-free Interactive Segmentation
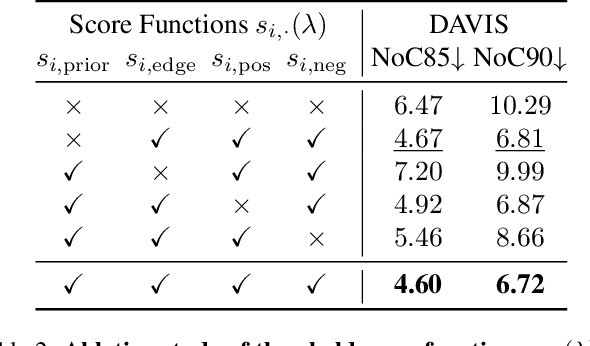
Mar 20, 2025We present Markov Map Nearest Neighbor V2 (M2N2V2), a novel and simple, yet effective approach which leverages depth guidance and attention maps for unsupervised and training-free point-prompt-based interactive segmentation. Following recent trends in supervised multimodal approaches, we carefully integrate depth as an additional modality to create novel depth-guided Markov-maps. Furthermore, we observe occasional segment size fluctuations in M2N2 during the interactive process, which can decrease the overall mIoU's. To mitigate this problem, we model the prompting as a sequential process and propose a novel adaptive score function which considers the previous segmentation and the current prompt point in order to prevent unreasonable segment size changes. Using Stable Diffusion 2 and Depth Anything V2 as backbones, we empirically show that our proposed M2N2V2 significantly improves the Number of Clicks (NoC) and mIoU compared to M2N2 in all datasets except those from the medical domain. Interestingly, our unsupervised approach achieves competitive results compared to supervised methods like SAM and SimpleClick in the more challenging DAVIS and HQSeg44K datasets in the NoC metric, reducing the gap between supervised and unsupervised methods.
Repurposing Stable Diffusion Attention for Training-Free Unsupervised Interactive Segmentation
Nov 15, 2024


Recent progress in interactive point prompt based Image Segmentation allows to significantly reduce the manual effort to obtain high quality semantic labels. State-of-the-art unsupervised methods use self-supervised pre-trained models to obtain pseudo-labels which are used in training a prompt-based segmentation model. In this paper, we propose a novel unsupervised and training-free approach based solely on the self-attention of Stable Diffusion. We interpret the self-attention tensor as a Markov transition operator, which enables us to iteratively construct a Markov chain. Pixel-wise counting of the required number of iterations along the Markov-chain to reach a relative probability threshold yields a Markov-iteration-map, which we simply call a Markov-map. Compared to the raw attention maps, we show that our proposed Markov-map has less noise, sharper semantic boundaries and more uniform values within semantically similar regions. We integrate the Markov-map in a simple yet effective truncated nearest neighbor framework to obtain interactive point prompt based segmentation. Despite being training-free, we experimentally show that our approach yields excellent results in terms of Number of Clicks (NoC), even outperforming state-of-the-art training based unsupervised methods in most of the datasets.
Looking Beyond Corners: Contrastive Learning of Visual Representations for Keypoint Detection and Description Extraction
Dec 22, 2021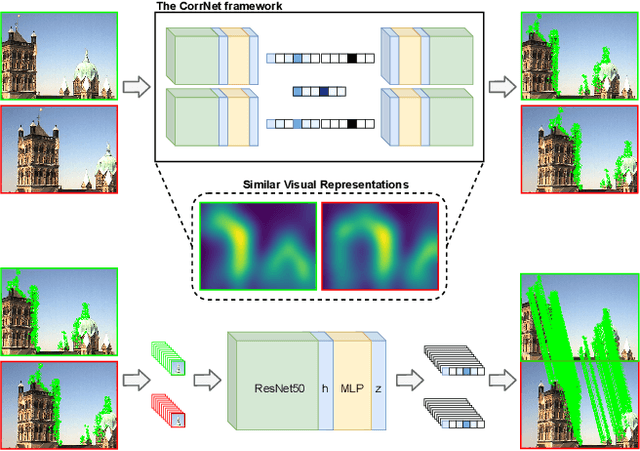
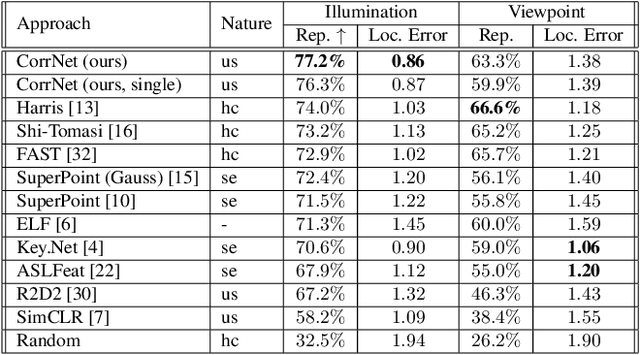

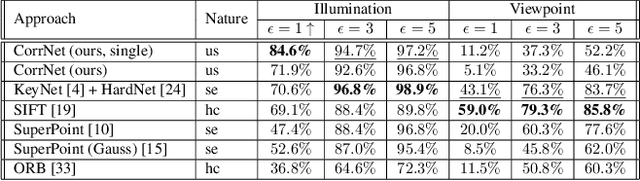
Learnable keypoint detectors and descriptors are beginning to outperform classical hand-crafted feature extraction methods. Recent studies on self-supervised learning of visual representations have driven the increasing performance of learnable models based on deep networks. By leveraging traditional data augmentations and homography transformations, these networks learn to detect corners under adverse conditions such as extreme illumination changes. However, their generalization capabilities are limited to corner-like features detected a priori by classical methods or synthetically generated data. In this paper, we propose the Correspondence Network (CorrNet) that learns to detect repeatable keypoints and to extract discriminative descriptions via unsupervised contrastive learning under spatial constraints. Our experiments show that CorrNet is not only able to detect low-level features such as corners, but also high-level features that represent similar objects present in a pair of input images through our proposed joint guided backpropagation of their latent space. Our approach obtains competitive results under viewpoint changes and achieves state-of-the-art performance under illumination changes.
TridentAdapt: Learning Domain-invariance via Source-Target Confrontation and Self-induced Cross-domain Augmentation
Nov 30, 2021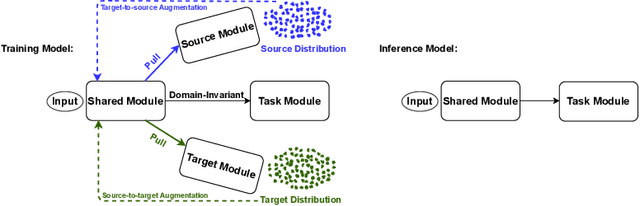
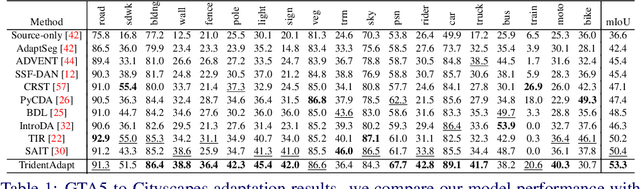
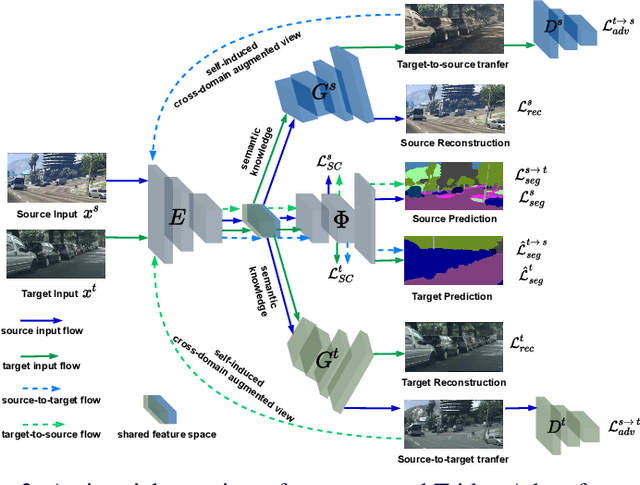
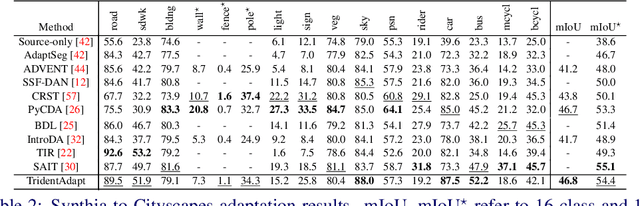
Due to the difficulty of obtaining ground-truth labels, learning from virtual-world datasets is of great interest for real-world applications like semantic segmentation. From domain adaptation perspective, the key challenge is to learn domain-agnostic representation of the inputs in order to benefit from virtual data. In this paper, we propose a novel trident-like architecture that enforces a shared feature encoder to satisfy confrontational source and target constraints simultaneously, thus learning a domain-invariant feature space. Moreover, we also introduce a novel training pipeline enabling self-induced cross-domain data augmentation during the forward pass. This contributes to a further reduction of the domain gap. Combined with a self-training process, we obtain state-of-the-art results on benchmark datasets (e.g. GTA5 or Synthia to Cityscapes adaptation). Code and pre-trained models are available at https://github.com/HMRC-AEL/TridentAdapt
Monocular Depth Estimation through Virtual-world Supervision and Real-world SfM Self-Supervision
Mar 22, 2021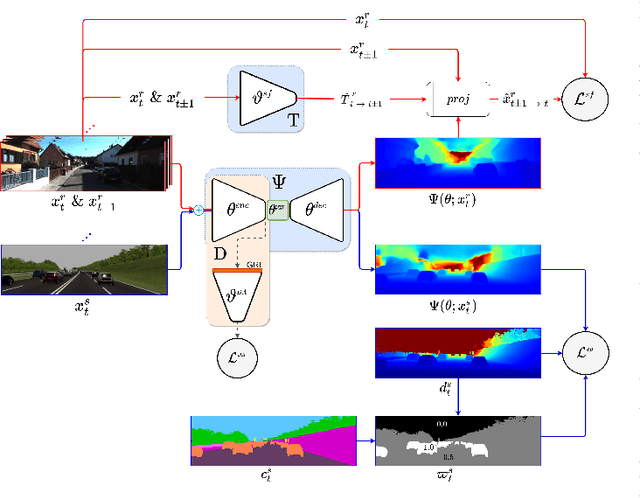
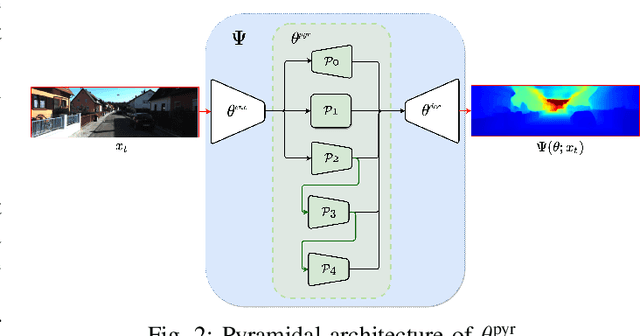
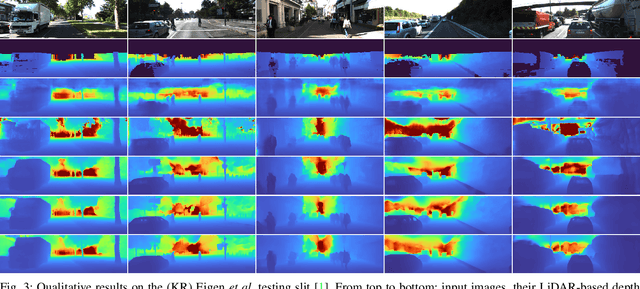
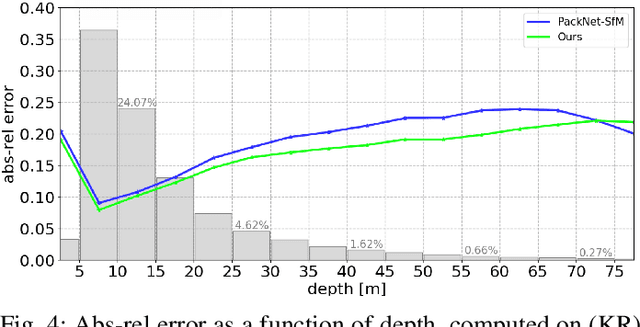
Depth information is essential for on-board perception in autonomous driving and driver assistance. Monocular depth estimation (MDE) is very appealing since it allows for appearance and depth being on direct pixelwise correspondence without further calibration. Best MDE models are based on Convolutional Neural Networks (CNNs) trained in a supervised manner, i.e., assuming pixelwise ground truth (GT). Usually, this GT is acquired at training time through a calibrated multi-modal suite of sensors. However, also using only a monocular system at training time is cheaper and more scalable. This is possible by relying on structure-from-motion (SfM) principles to generate self-supervision. Nevertheless, problems of camouflaged objects, visibility changes, static-camera intervals, textureless areas, and scale ambiguity, diminish the usefulness of such self-supervision. In this paper, we perform monocular depth estimation by virtual-world supervision (MonoDEVS) and real-world SfM self-supervision. We compensate the SfM self-supervision limitations by leveraging virtual-world images with accurate semantic and depth supervision and addressing the virtual-to-real domain gap. Our MonoDEVSNet outperforms previous MDE CNNs trained on monocular and even stereo sequences.
Real-Time Lane ID Estimation Using Recurrent Neural Networks With Dual Convention
Jan 14, 2020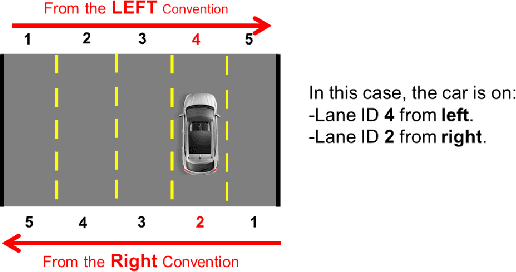
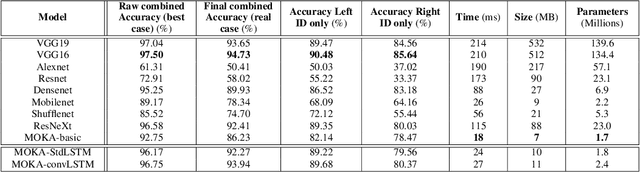
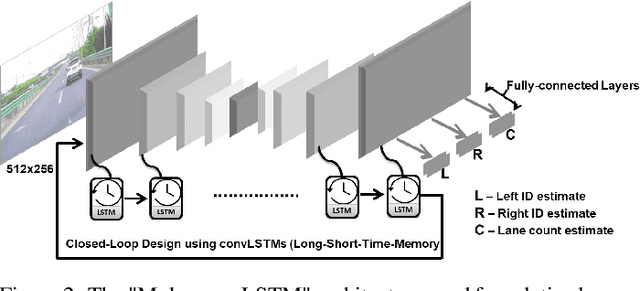
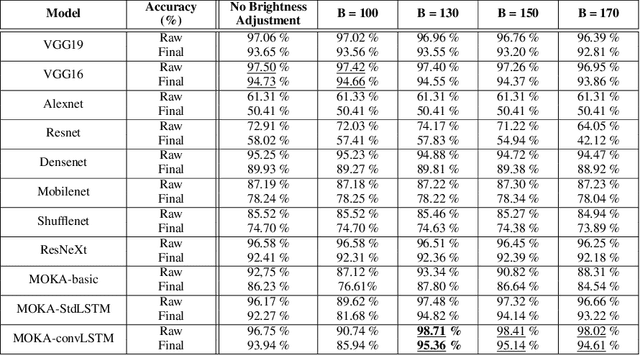
Acquiring information about the road lane structure is a crucial step for autonomous navigation. To this end, several approaches tackle this task from different perspectives such as lane marking detection or semantic lane segmentation. However, to the best of our knowledge, there is yet no purely vision based end-to-end solution to answer the precise question: How to estimate the relative number or "ID" of the current driven lane within a multi-lane road or a highway? In this work, we propose a real-time, vision-only (i.e. monocular camera) solution to the problem based on a dual left-right convention. We interpret this task as a classification problem by limiting the maximum number of lane candidates to eight. Our approach is designed to meet low-complexity specifications and limited runtime requirements. It harnesses the temporal dimension inherent to the input sequences to improve upon high-complexity state-of-the-art models. We achieve more than 95% accuracy on a challenging test set with extreme conditions and different routes.
Multimodal End-to-End Autonomous Driving
Jun 07, 2019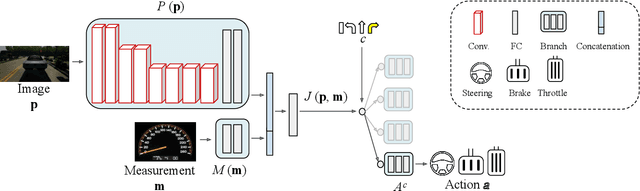
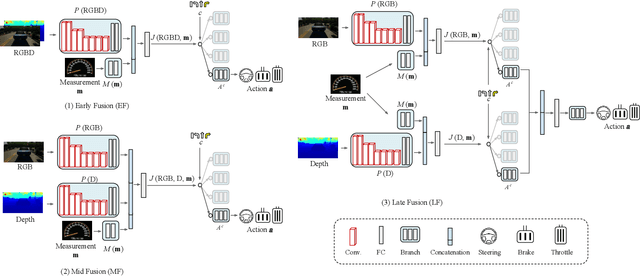

Autonomous vehicles (AVs) are key for the intelligent mobility of the future. A crucial component of an AV is the artificial intelligence (AI) able to drive towards a desired destination. Today, there are different paradigms addressing the development of AI drivers. On the one hand, we find modular pipelines, which divide the driving task into sub-tasks such as perception (object detection, semantic segmentation, depth estimation, tracking) and maneuver control (local path planing and control). On the other hand, we find end-to-end driving approaches that try to learn a direct mapping from input raw sensor data to vehicle control signals (the steering angle). The later are relatively less studied, but are gaining popularity since they are less demanding in terms of sensor data annotation. This paper focuses on end-to-end autonomous driving. So far, most proposals relying on this paradigm assume RGB images as input sensor data. However, AVs will not be equipped only with cameras, but also with active sensors providing accurate depth information (traditional LiDARs, or new solid state ones). Accordingly, this paper analyses if RGB and depth data, RGBD data, can actually act as complementary information in a multimodal end-to-end driving approach, producing a better AI driver. Using the CARLA simulator functionalities, its standard benchmark, and conditional imitation learning (CIL), we will show how, indeed, RGBD gives rise to more successful end-to-end AI drivers. We will compare the use of RGBD information by means of early, mid and late fusion schemes, both in multisensory and single-sensor (monocular depth estimation) settings.
Monocular Depth Estimation by Learning from Heterogeneous Datasets
Sep 12, 2018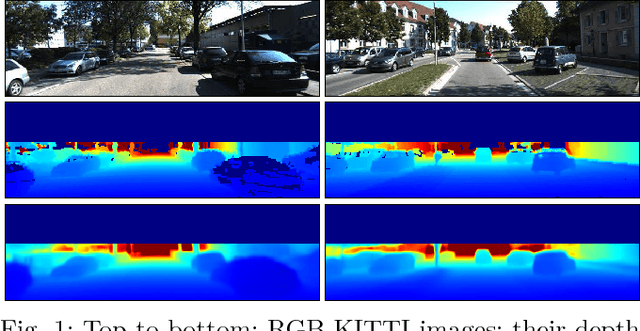
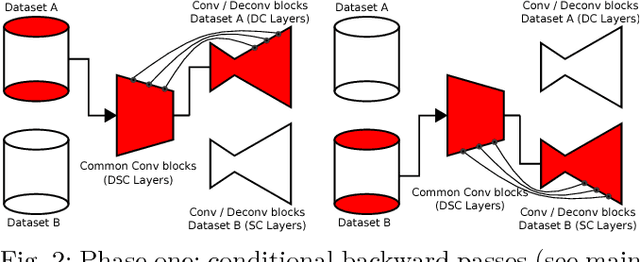
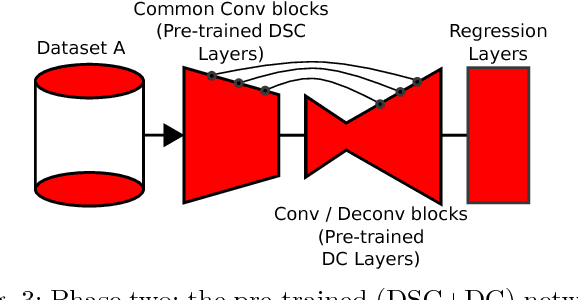
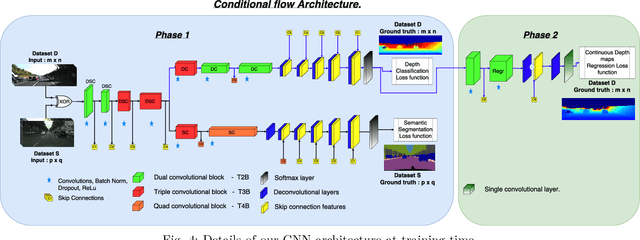
Depth estimation provides essential information to perform autonomous driving and driver assistance. Especially, Monocular Depth Estimation is interesting from a practical point of view, since using a single camera is cheaper than many other options and avoids the need for continuous calibration strategies as required by stereo-vision approaches. State-of-the-art methods for Monocular Depth Estimation are based on Convolutional Neural Networks (CNNs). A promising line of work consists of introducing additional semantic information about the traffic scene when training CNNs for depth estimation. In practice, this means that the depth data used for CNN training is complemented with images having pixel-wise semantic labels, which usually are difficult to annotate (e.g. crowded urban images). Moreover, so far it is common practice to assume that the same raw training data is associated with both types of ground truth, i.e., depth and semantic labels. The main contribution of this paper is to show that this hard constraint can be circumvented, i.e., that we can train CNNs for depth estimation by leveraging the depth and semantic information coming from heterogeneous datasets. In order to illustrate the benefits of our approach, we combine KITTI depth and Cityscapes semantic segmentation datasets, outperforming state-of-the-art results on Monocular Depth Estimation.
Learnable Exposure Fusion for Dynamic Scenes
Apr 04, 2018
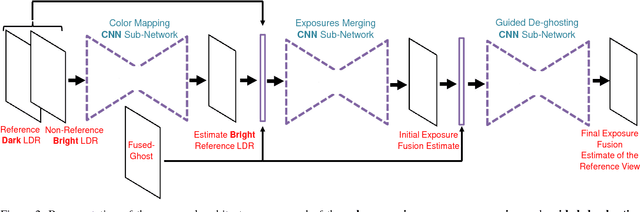


In this paper, we focus on Exposure Fusion (EF) [ExposFusi2] for dynamic scenes. The task is to fuse multiple images obtained by exposure bracketing to create an image which comprises a high level of details. Typically, such images are not possible to obtain directly from a camera due to hardware limitations, e.g., a limited dynamic range of the sensor. A major problem of such tasks is that the images may not be spatially aligned due to scene motion or camera motion. It is known that the required alignment by image registration problems is ill-posed. In this case, the images to be aligned vary in their intensity range, which makes the problem even more difficult. To address the mentioned problems, we propose an end-to-end \emph{Convolutional Neural Network} (CNN) based approach to learn to estimate exposure fusion from $2$ and $3$ Low Dynamic Range (LDR) images depicting different scene contents. To the best of our knowledge, no efficient and robust CNN-based end-to-end approach can be found in the literature for this kind of problem. The idea is to create a dataset with perfectly aligned LDR images to obtain ground-truth exposure fusion images. At the same time, we obtain additional LDR images with some motion, having the same exposure fusion ground-truth as the perfectly aligned LDR images. This way, we can train an end-to-end CNN having misaligned LDR input images, but with a proper ground truth exposure fusion image. We propose a specific CNN-architecture to solve this problem. In various experiments, we show that the proposed approach yields excellent results.
Symmetry Breaking in Neuroevolution: A Technical Report
Jul 22, 2011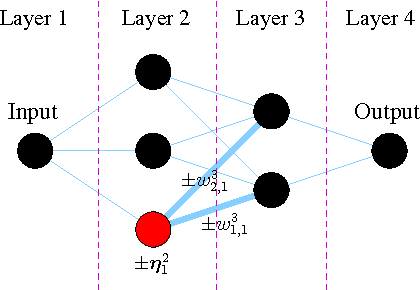
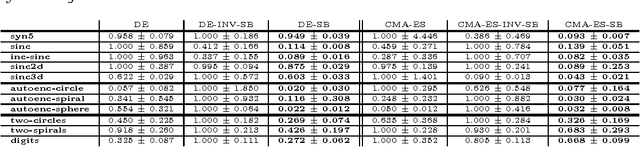
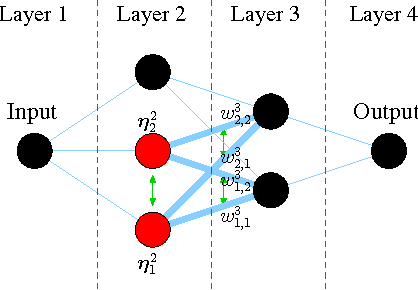
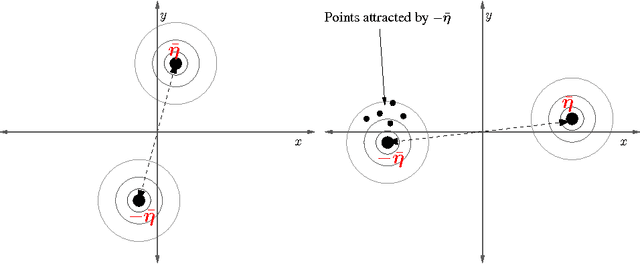
Artificial Neural Networks (ANN) comprise important symmetry properties, which can influence the performance of Monte Carlo methods in Neuroevolution. The problem of the symmetries is also known as the competing conventions problem or simply as the permutation problem. In the literature, symmetries are mainly addressed in Genetic Algoritm based approaches. However, investigations in this direction based on other Evolutionary Algorithms (EA) are rare or missing. Furthermore, there are different and contradictionary reports on the efficacy of symmetry breaking. By using a novel viewpoint, we offer a possible explanation for this issue. As a result, we show that a strategy which is invariant to the global optimum can only be successfull on certain problems, whereas it must fail to improve the global convergence on others. We introduce the \emph{Minimum Global Optimum Proximity} principle as a generalized and adaptive strategy to symmetry breaking, which depends on the location of the global optimum. We apply the proposed principle to Differential Evolution (DE) and Covariance Matrix Adaptation Evolution Strategies (CMA-ES), which are two popular and conceptually different global optimization methods. Using a wide range of feedforward ANN problems, we experimentally illustrate significant improvements in the global search efficiency by the proposed symmetry breaking technique.