 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal German Dataset for Automatic Lip Reading Systems and Transfer Learning
Feb 27, 2022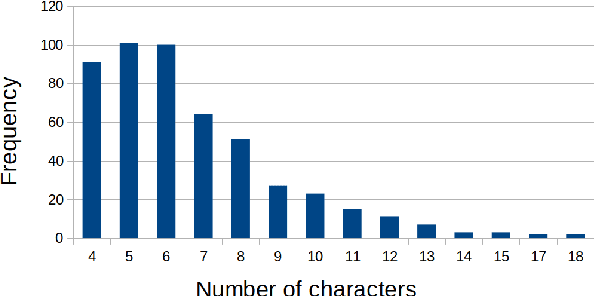
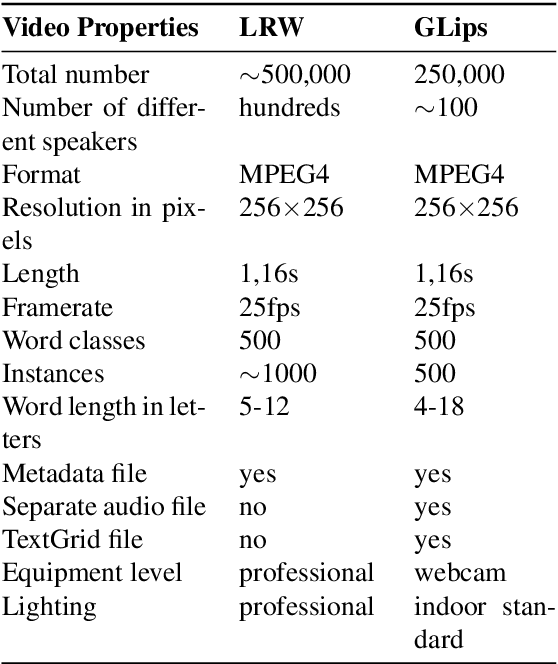
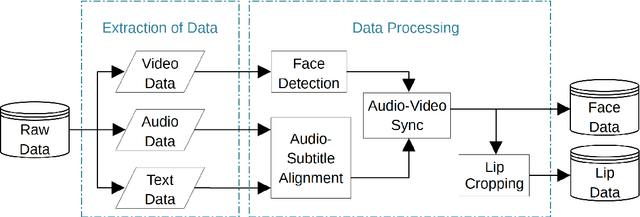

Large datasets as required for deep learning of lip reading do not exist in many languages. In this paper we present the dataset GLips (German Lips) consisting of 250,000 publicly available videos of the faces of speakers of the Hessian Parliament, which was processed for word-level lip reading using an automatic pipeline. The format is similar to that of the English language LRW (Lip Reading in the Wild) dataset, with each video encoding one word of interest in a context of 1.16 seconds duration, which yields compatibility for studying transfer learning between both datasets. By training a deep neural network, we investigate whether lip reading has language-independent features, so that datasets of different languages can be used to improve lip reading models. We demonstrate learning from scratch and show that transfer learning from LRW to GLips and vice versa improves learning speed and performance, in particular for the validation set.
Looking Beyond Corners: Contrastive Learning of Visual Representations for Keypoint Detection and Description Extraction
Dec 22, 2021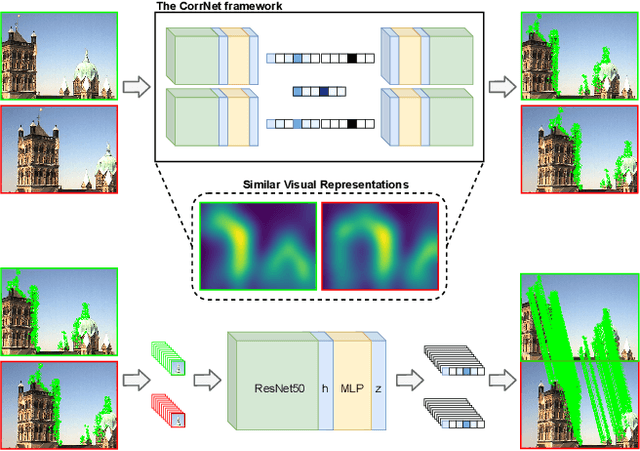
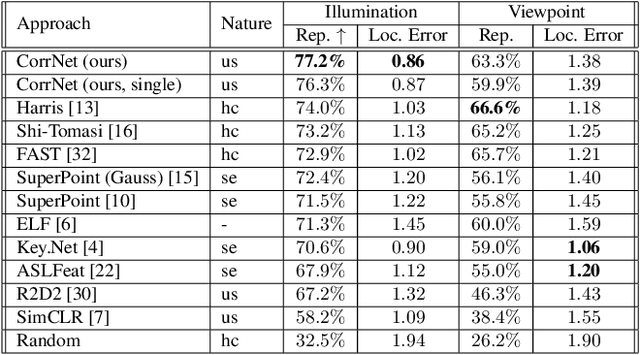

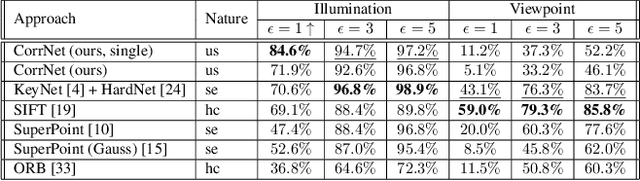
Learnable keypoint detectors and descriptors are beginning to outperform classical hand-crafted feature extraction methods. Recent studies on self-supervised learning of visual representations have driven the increasing performance of learnable models based on deep networks. By leveraging traditional data augmentations and homography transformations, these networks learn to detect corners under adverse conditions such as extreme illumination changes. However, their generalization capabilities are limited to corner-like features detected a priori by classical methods or synthetically generated data. In this paper, we propose the Correspondence Network (CorrNet) that learns to detect repeatable keypoints and to extract discriminative descriptions via unsupervised contrastive learning under spatial constraints. Our experiments show that CorrNet is not only able to detect low-level features such as corners, but also high-level features that represent similar objects present in a pair of input images through our proposed joint guided backpropagation of their latent space. Our approach obtains competitive results under viewpoint changes and achieves state-of-the-art performance under illumination changes.
A Sub-Layered Hierarchical Pyramidal Neural Architecture for Facial Expression Recognition
Mar 23, 2021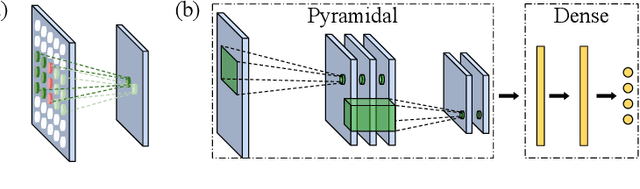

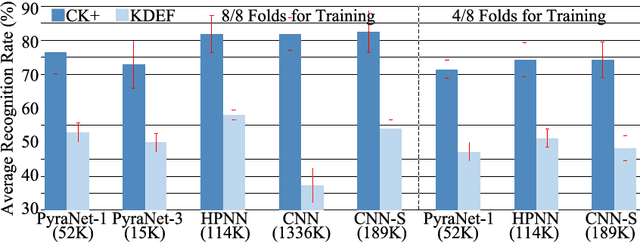

In domains where computational resources and labeled data are limited, such as in robotics, deep networks with millions of weights might not be the optimal solution. In this paper, we introduce a connectivity scheme for pyramidal architectures to increase their capacity for learning features. Experiments on facial expression recognition of unseen people demonstrate that our approach is a potential candidate for applications with restricted resources, due to good generalization performance and low computational cost. We show that our approach generalizes as well as convolutional architectures in this task but uses fewer trainable parameters and is more robust for low-resolution faces.
Disambiguating Affective Stimulus Associations for Robot Perception and Dialogue
Mar 05, 2021

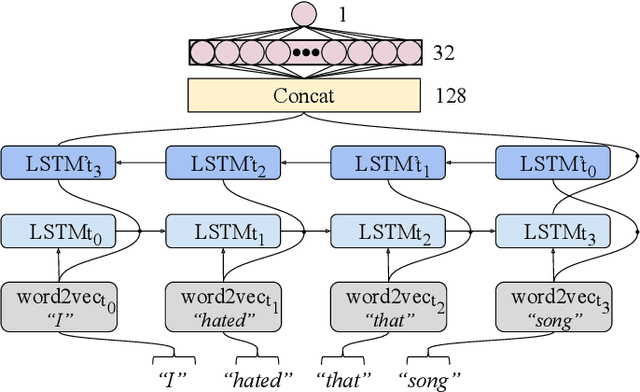
Effectively recognising and applying emotions to interactions is a highly desirable trait for social robots. Implicitly understanding how subjects experience different kinds of actions and objects in the world is crucial for natural HRI interactions, with the possibility to perform positive actions and avoid negative actions. In this paper, we utilize the NICO robot's appearance and capabilities to give the NICO the ability to model a coherent affective association between a perceived auditory stimulus and a temporally asynchronous emotion expression. This is done by combining evaluations of emotional valence from vision and language. NICO uses this information to make decisions about when to extend conversations in order to accrue more affective information if the representation of the association is not coherent. Our primary contribution is providing a NICO robot with the ability to learn the affective associations between a perceived auditory stimulus and an emotional expression. NICO is able to do this for both individual subjects and specific stimuli, with the aid of an emotion-driven dialogue system that rectifies emotional expression incoherences. The robot is then able to use this information to determine a subject's enjoyment of perceived auditory stimuli in a real HRI scenario.
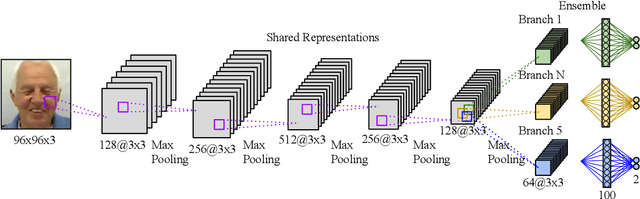
An Ensemble with Shared Representations Based on Convolutional Networks for Continually Learning Facial Expressions
Mar 05, 2021
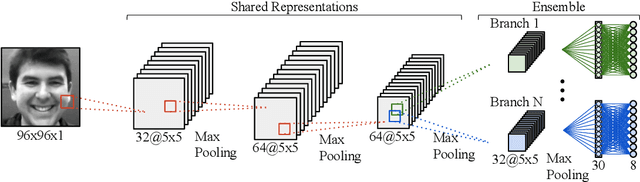

Social robots able to continually learn facial expressions could progressively improve their emotion recognition capability towards people interacting with them. Semi-supervised learning through ensemble predictions is an efficient strategy to leverage the high exposure of unlabelled facial expressions during human-robot interactions. Traditional ensemble-based systems, however, are composed of several independent classifiers leading to a high degree of redundancy, and unnecessary allocation of computational resources. In this paper, we proposed an ensemble based on convolutional networks where the early layers are strong low-level feature extractors, and their representations shared with an ensemble of convolutional branches. This results in a significant drop in redundancy of low-level features processing. Training in a semi-supervised setting, we show that our approach is able to continually learn facial expressions through ensemble predictions using unlabelled samples from different data distributions.
Facial Expression Editing with Continuous Emotion Labels
Jun 22, 2020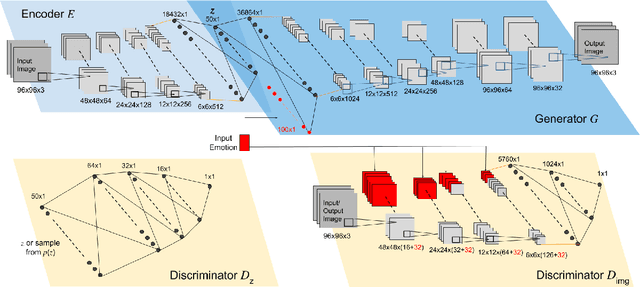



Recently deep generative models have achieved impressive results in the field of automated facial expression editing. However, the approaches presented so far presume a discrete representation of human emotions and are therefore limited in the modelling of non-discrete emotional expressions. To overcome this limitation, we explore how continuous emotion representations can be used to control automated expression editing. We propose a deep generative model that can be used to manipulate facial expressions in facial images according to continuous two-dimensional emotion labels. One dimension represents an emotion's valence, the other represents its degree of arousal. We demonstrate the functionality of our model with a quantitative analysis using classifier networks as well as with a qualitative analysis.
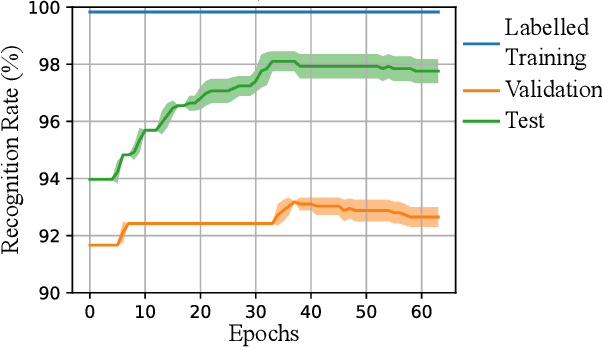
Efficient Facial Feature Learning with Wide Ensemble-based Convolutional Neural Networks
Jan 17, 2020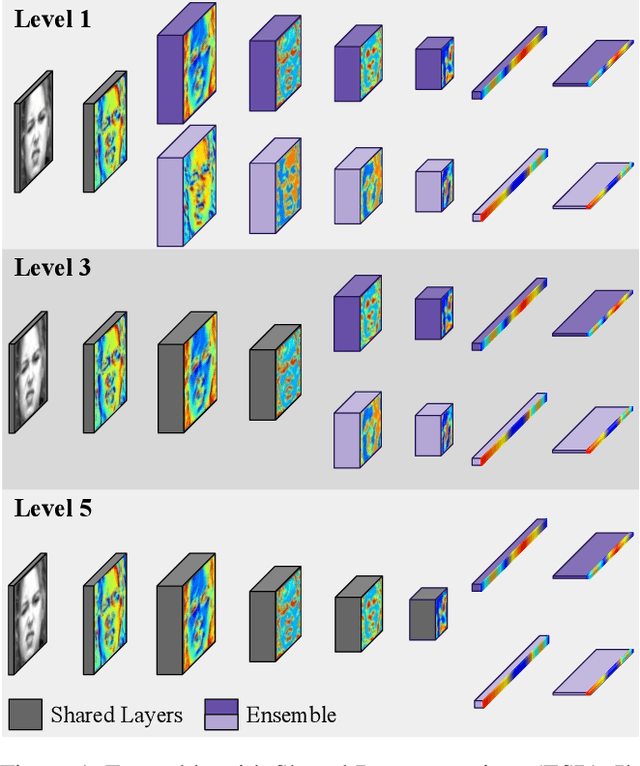
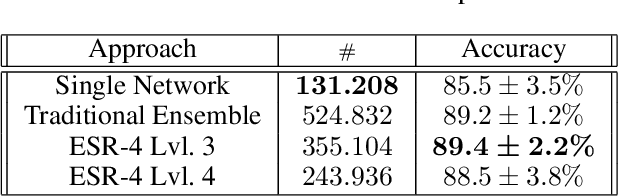
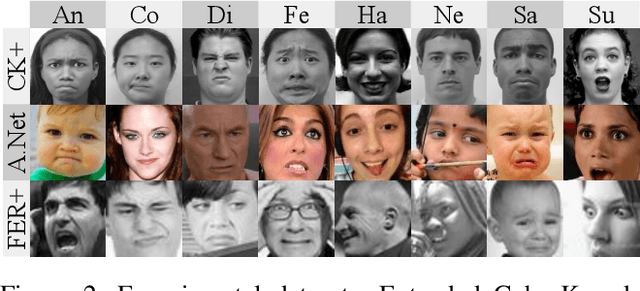
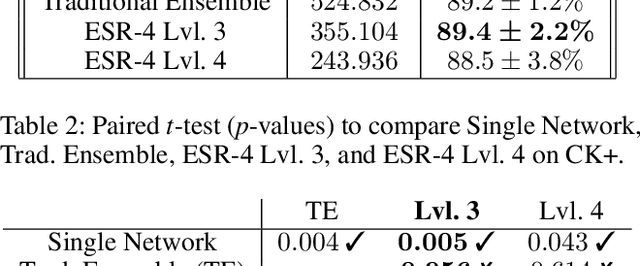
Ensemble methods, traditionally built with independently trained de-correlated models, have proven to be efficient methods for reducing the remaining residual generalization error, which results in robust and accurate methods for real-world applications. In the context of deep learning, however, training an ensemble of deep networks is costly and generates high redundancy which is inefficient. In this paper, we present experiments on Ensembles with Shared Representations (ESRs) based on convolutional networks to demonstrate, quantitatively and qualitatively, their data processing efficiency and scalability to large-scale datasets of facial expressions. We show that redundancy and computational load can be dramatically reduced by varying the branching level of the ESR without loss of diversity and generalization power, which are both important for ensemble performance. Experiments on large-scale datasets suggest that ESRs reduce the remaining residual generalization error on the AffectNet and FER+ datasets, reach human-level performance, and outperform state-of-the-art methods on facial expression recognition in the wild using emotion and affect concepts.