 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distilled Representation Learning for Time Series
Nov 19, 2023



Self-supervised learning for time-series data holds potential similar to that recently unleashed in Natural Language Processing and Computer Vision. While most existing works in this area focus on contrastive learning, we propose a conceptually simple yet powerful non-contrastive approach, based on the data2vec self-distillation framework. The core of our method is a student-teacher scheme that predicts the latent representation of an input time series from masked views of the same time series. This strategy avoids strong modality-specific assumptions and biases typically introduced by the design of contrastive sample pairs. We demonstrate the competitiveness of our approach for classification and forecasting as downstream tasks, comparing with state-of-the-art self-supervised learning methods on the UCR and UEA archives as well as the ETT and Electricity datasets.
Discrete Denoising Flows
Jul 24, 2021

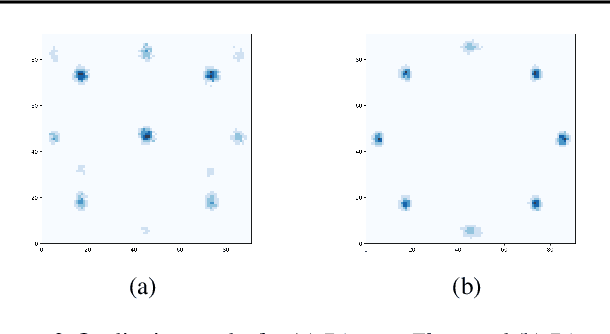
Discrete flow-based models are a recently proposed class of generative models that learn invertible transformations for discrete random variables. Since they do not require data dequantization and maximize an exact likelihood objective, they can be used in a straight-forward manner for lossless compression. In this paper, we introduce a new discrete flow-based model for categorical random variables: Discrete Denoising Flows (DDFs). In contrast with other discrete flow-based models, our model can be locally trained without introducing gradient bias. We show that DDFs outperform Discrete Flows on modeling a toy example, binary MNIST and Cityscapes segmentation maps, measured in log-likelihood.
Facial Expression Editing with Continuous Emotion Labels
Jun 22, 2020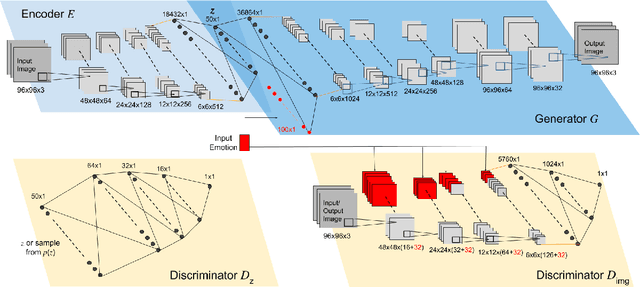



Recently deep generative models have achieved impressive results in the field of automated facial expression editing. However, the approaches presented so far presume a discrete representation of human emotions and are therefore limited in the modelling of non-discrete emotional expressions. To overcome this limitation, we explore how continuous emotion representations can be used to control automated expression editing. We propose a deep generative model that can be used to manipulate facial expressions in facial images according to continuous two-dimensional emotion labels. One dimension represents an emotion's valence, the other represents its degree of arousal. We demonstrate the functionality of our model with a quantitative analysis using classifier networks as well as with a qualitative analysis.