 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distilled Representation Learning for Time Series
Nov 19, 2023



Self-supervised learning for time-series data holds potential similar to that recently unleashed in Natural Language Processing and Computer Vision. While most existing works in this area focus on contrastive learning, we propose a conceptually simple yet powerful non-contrastive approach, based on the data2vec self-distillation framework. The core of our method is a student-teacher scheme that predicts the latent representation of an input time series from masked views of the same time series. This strategy avoids strong modality-specific assumptions and biases typically introduced by the design of contrastive sample pairs. We demonstrate the competitiveness of our approach for classification and forecasting as downstream tasks, comparing with state-of-the-art self-supervised learning methods on the UCR and UEA archives as well as the ETT and Electricity datasets.
Uncovering the Inner Workings of STEGO for Safe Unsupervised Semantic Segmentation
Apr 14, 2023

Self-supervised pre-training strategies have recently shown impressive results for training general-purpose feature extraction backbones in computer vision. In combination with the Vision Transformer architecture, the DINO self-distillation technique has interesting emerging properties, such as unsupervised clustering in the latent space and semantic correspondences of the produced features without using explicit human-annotated labels. The STEGO method for unsupervised semantic segmentation contrastively distills feature correspondences of a DINO-pre-trained Vision Transformer and recently set a new state of the art. However, the detailed workings of STEGO have yet to be disentangled, preventing its usage in safety-critical applications. This paper provides a deeper understanding of the STEGO architecture and training strategy by conducting studies that uncover the working mechanisms behind STEGO, reproduce and extend its experimental validation, and investigate the ability of STEGO to transfer to different datasets. Results demonstrate that the STEGO architecture can be interpreted as a semantics-preserving dimensionality reduction technique.
MEAL: Manifold Embedding-based Active Learning
Jul 20, 2021

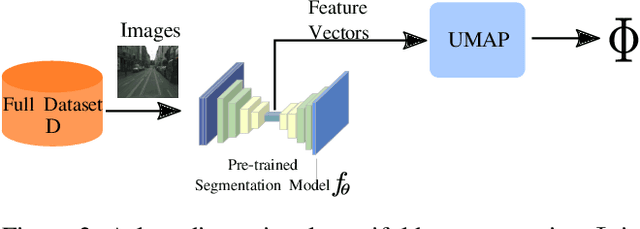
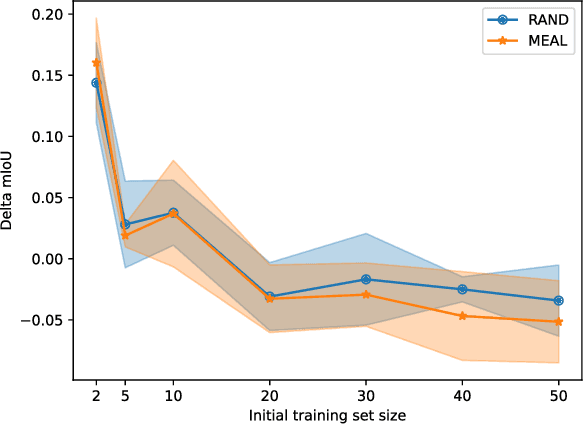
Image segmentation is a common and challenging task in autonomous driving. Availability of sufficient pixel-level annotations for the training data is a hurdle. Active learning helps learning from small amounts of data by suggesting the most promising samples for labeling. In this work, we propose a new pool-based method for active learning, which proposes promising patches extracted from full image, in each acquisition step. The problem is framed in an exploration-exploitation framework by combining an embedding based on Uniform Manifold Approximation to model representativeness with entropy as uncertainty measure to model informativeness. We applied our proposed method to the autonomous driving datasets CamVid and Cityscapes and performed a quantitative comparison with state-of-the-art baselines. We find that our active learning method achieves better performance compared to previous methods.
DAAIN: Detection of Anomalous and Adversarial Input using Normalizing Flows
May 30, 2021

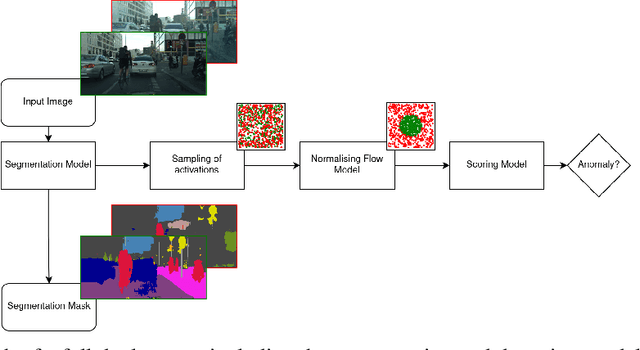
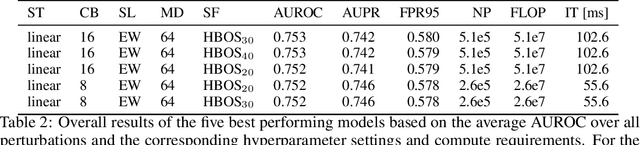
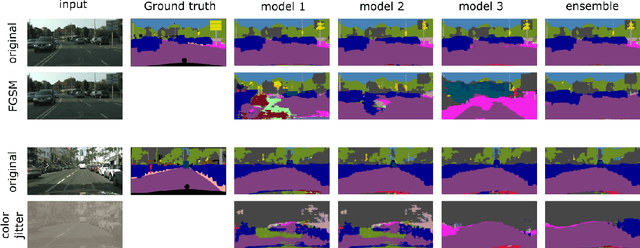
Despite much recent work, detecting out-of-distribution (OOD) inputs and adversarial attacks (AA) for computer vision models remains a challenge. In this work, we introduce a novel technique, DAAIN, to detect OOD inputs and AA for image segmentation in a unified setting. Our approach monitors the inner workings of a neural network and learns a density estimator of the activation distribution. We equip the density estimator with a classification head to discriminate between regular and anomalous inputs. To deal with the high-dimensional activation-space of typical segmentation networks, we subsample them to obtain a homogeneous spatial and layer-wise coverage. The subsampling pattern is chosen once per monitored model and kept fixed for all inputs. Since the attacker has access to neither the detection model nor the sampling key, it becomes harder for them to attack the segmentation network, as the attack cannot be backpropagated through the detector. We demonstrate the effectiveness of our approach using an ESPNet trained on the Cityscapes dataset as segmentation model, an affine Normalizing Flow as density estimator and use blue noise to ensure homogeneous sampling. Our model can be trained on a single GPU making it compute efficient and deployable without requiring specialized accelerators.
Chameleon: A Semi-AutoML framework targeting quick and scalable development and deployment of production-ready ML systems for SMEs
May 08, 2021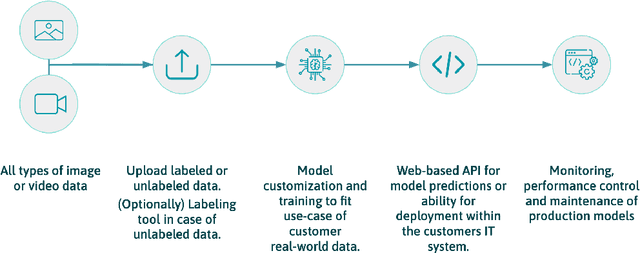

Developing, scaling, and deploying modern Machine Learning solutions remains challenging for small- and middle-sized enterprises (SMEs). This is due to a high entry barrier of building and maintaining a dedicated IT team as well as the difficulties of real-world data (RWD) compared to standard benchmark data. To address this challenge, we discuss the implementation and concepts of Chameleon, a semi-AutoML framework. The goal of Chameleon is fast and scalable development and deployment of production-ready machine learning systems into the workflow of SMEs. We first discuss the RWD challenges faced by SMEs. After, we outline the central part of the framework which is a model and loss-function zoo with RWD-relevant defaults. Subsequently, we present how one can use a templatable framework in order to automate the experiment iteration cycle, as well as close the gap between development and deployment. Finally, we touch on our testing framework component allowing us to investigate common model failure modes and support best practices of model deployment governance.