 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Sensing for Universal Jamming Grippers
Feb 27, 2026Universal jamming grippers excel at grasping unknown objects due to their compliant bodies. Traditional tactile sensors can compromise this compliance, reducing grasping performance. We present acoustic sensing as a form of morphological sensing, where the gripper's soft body itself becomes the sensor. A speaker and microphone are placed inside the gripper cavity, away from the deformable membrane, fully preserving compliance. Sound propagates through the gripper and object, encoding object properties, which are then reconstructed via machine learning. Our sensor achieves high spatial resolution in sensing object size (2.6 mm error) and orientation (0.6 deg error), remains robust to external noise levels of 80 dBA, and discriminates object materials (up to 100% accuracy) and 16 everyday objects (85.6% accuracy). We validate the sensor in a realistic tactile object sorting task, achieving 53 minutes of uninterrupted grasping and sensing, confirming the preserved grasping performance. Finally, we demonstrate that disentangled acoustic representations can be learned, improving robustness to irrelevant acoustic variations.
* Accepted at ICRA 2026, supplementary material under https://rbo.gitlab-pages.tu-berlin.de/papers/acoustic-jamming-icra26/
Uncovering the Inner Workings of STEGO for Safe Unsupervised Semantic Segmentation
Apr 14, 2023

Self-supervised pre-training strategies have recently shown impressive results for training general-purpose feature extraction backbones in computer vision. In combination with the Vision Transformer architecture, the DINO self-distillation technique has interesting emerging properties, such as unsupervised clustering in the latent space and semantic correspondences of the produced features without using explicit human-annotated labels. The STEGO method for unsupervised semantic segmentation contrastively distills feature correspondences of a DINO-pre-trained Vision Transformer and recently set a new state of the art. However, the detailed workings of STEGO have yet to be disentangled, preventing its usage in safety-critical applications. This paper provides a deeper understanding of the STEGO architecture and training strategy by conducting studies that uncover the working mechanisms behind STEGO, reproduce and extend its experimental validation, and investigate the ability of STEGO to transfer to different datasets. Results demonstrate that the STEGO architecture can be interpreted as a semantics-preserving dimensionality reduction technique.
Tactile Grasp Refinement using Deep Reinforcement Learning and Analytic Grasp Stability Metrics
Sep 23, 2021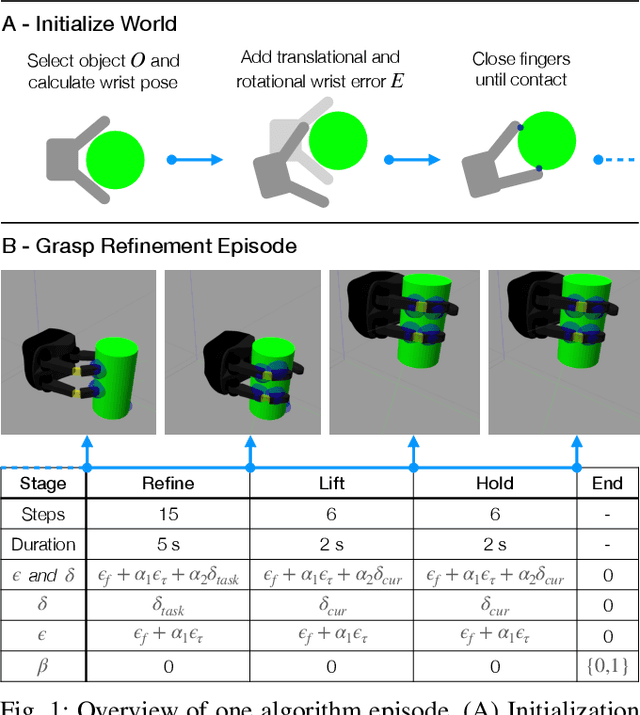
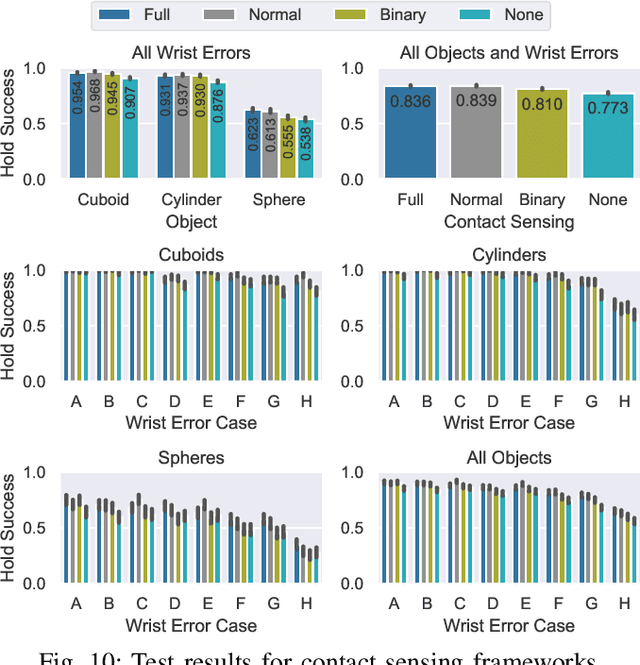
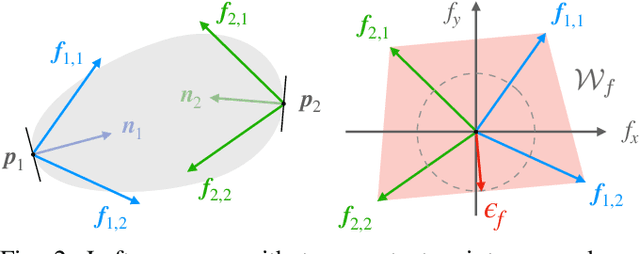
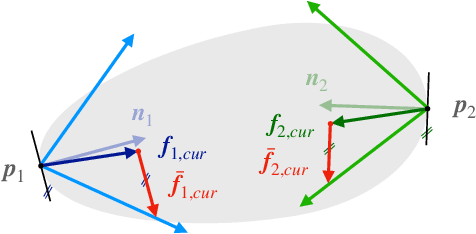
Reward functions are at the heart of every reinforcement learning (RL) algorithm. In robotic grasping, rewards are often complex and manually engineered functions that do not rely on well-justified physical models from grasp analysis. This work demonstrates that analytic grasp stability metrics constitute powerful optimization objectives for RL algorithms that refine grasps on a three-fingered hand using only tactile and joint position information. We outperform a binary-reward baseline by 42.9% and find that a combination of geometric and force-agnostic grasp stability metrics yields the highest average success rates of 95.4% for cuboids, 93.1% for cylinders, and 62.3% for spheres across wrist position errors between 0 and 7 centimeters and rotational errors between 0 and 14 degrees. In a second experiment, we show that grasp refinement algorithms trained with contact feedback (contact positions, normals, and forces) perform up to 6.6% better than a baseline that receives no tactile information.