 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTactile Grasp Refinement using Deep Reinforcement Learning and Analytic Grasp Stability Metrics
Paper and Code
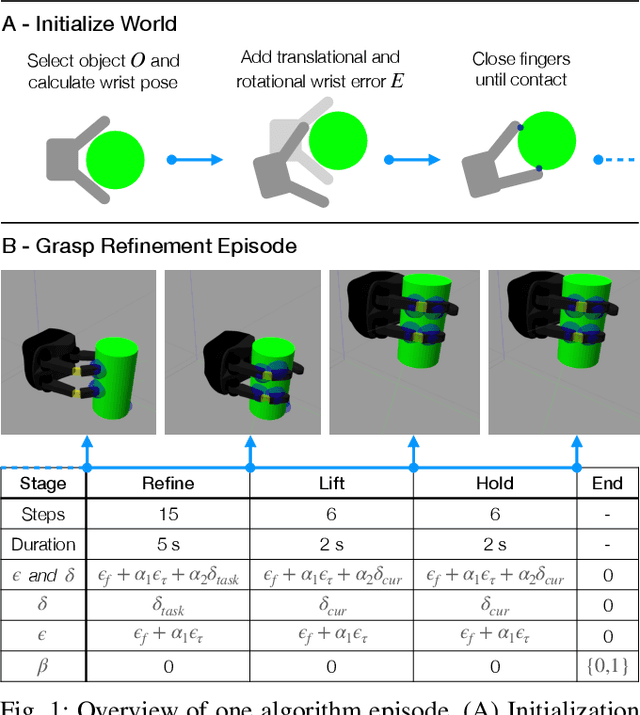
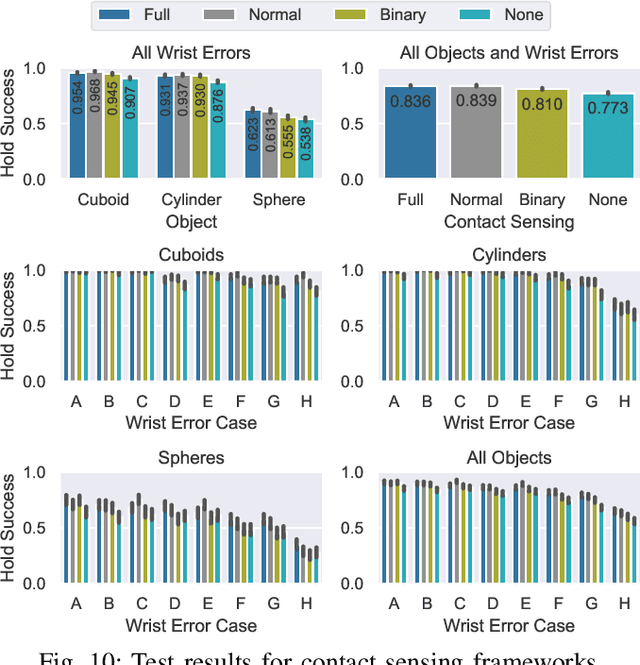
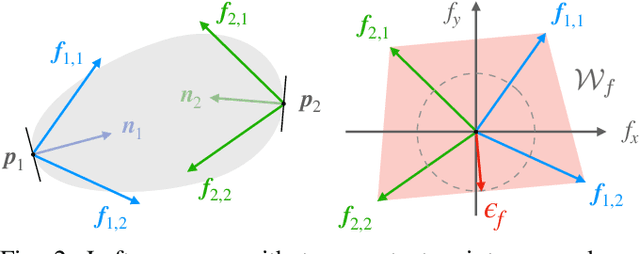
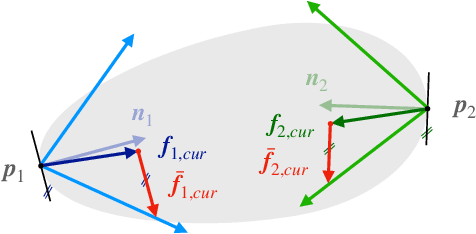
Reward functions are at the heart of every reinforcement learning (RL) algorithm. In robotic grasping, rewards are often complex and manually engineered functions that do not rely on well-justified physical models from grasp analysis. This work demonstrates that analytic grasp stability metrics constitute powerful optimization objectives for RL algorithms that refine grasps on a three-fingered hand using only tactile and joint position information. We outperform a binary-reward baseline by 42.9% and find that a combination of geometric and force-agnostic grasp stability metrics yields the highest average success rates of 95.4% for cuboids, 93.1% for cylinders, and 62.3% for spheres across wrist position errors between 0 and 7 centimeters and rotational errors between 0 and 14 degrees. In a second experiment, we show that grasp refinement algorithms trained with contact feedback (contact positions, normals, and forces) perform up to 6.6% better than a baseline that receives no tactile information.