 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabGemma: Text-Based Tabular ICL via LLM using Continued Pretraining and Retrieval
Nov 05, 2025We study LLMs for tabular prediction with mixed text, numeric, and categorical fields. We introduce TabGemma, a schema-agnostic in-context learner that treats rows as sequences and tackles two practical hurdles when adapting pretrained LLMs for tabular predictions: unstable numeric tokenization and limited context size. We propose to canonicalize numbers via signed scientific notation and continue pretraining of a 12B Gemma 3 model with a target imputation objective using a large-scale real world dataset. For inference, we use a compact n-gram-based retrieval to select informative exemplars that fit within a 128k-token window. On semantically rich benchmarks, TabGemma establishes a new state of the art on classification across low- and high-data regimes and improves monotonically with more context rows. For regression, it is competitive at small sample sizes but trails conventional approaches as data grows. Our results show that LLMs can be effective tabular in-context learners on highly semantic tasks when paired with dedicated numeric handling and context retrieval, while motivating further advances in numeric modeling and long-context scaling.
ConTextTab: A Semantics-Aware Tabular In-Context Learner
Jun 12, 2025Tabular in-context learning (ICL) has recently achieved state-of-the-art (SOTA) performance on several tabular prediction tasks. Previously restricted to classification problems on small tables, recent advances such as TabPFN and TabICL have extended its use to larger datasets. While being architecturally efficient and well-adapted to tabular data structures, current table-native ICL architectures, being trained exclusively on synthetic data, do not fully leverage the rich semantics and world knowledge contained in real-world tabular data. On another end of this spectrum, tabular ICL models based on pretrained large language models such as TabuLa-8B integrate deep semantic understanding and world knowledge but are only able to make use of a small amount of context due to inherent architectural limitations. With the aim to combine the best of both these worlds, we introduce ConTextTab, integrating semantic understanding and alignment into a table-native ICL framework. By employing specialized embeddings for different data modalities and by training on large-scale real-world tabular data, our model is competitive with SOTA across a broad set of benchmarks while setting a new standard on the semantically rich CARTE benchmark.
Scaling Experiments in Self-Supervised Cross-Table Representation Learning
Sep 29, 2023



To analyze the scaling potential of deep tabular representation learning models, we introduce a novel Transformer-based architecture specifically tailored to tabular data and cross-table representation learning by utilizing table-specific tokenizers and a shared Transformer backbone. Our training approach encompasses both single-table and cross-table models, trained via missing value imputation through a self-supervised masked cell recovery objective. To understand the scaling behavior of our method, we train models of varying sizes, ranging from approximately $10^4$ to $10^7$ parameters. These models are trained on a carefully curated pretraining dataset, consisting of 135M training tokens sourced from 76 diverse datasets. We assess the scaling of our architecture in both single-table and cross-table pretraining setups by evaluating the pretrained models using linear probing on a curated set of benchmark datasets and comparing the results with conventional baselines.
Curve Your Enthusiasm: Concurvity Regularization in Differentiable Generalized Additive Models
May 19, 2023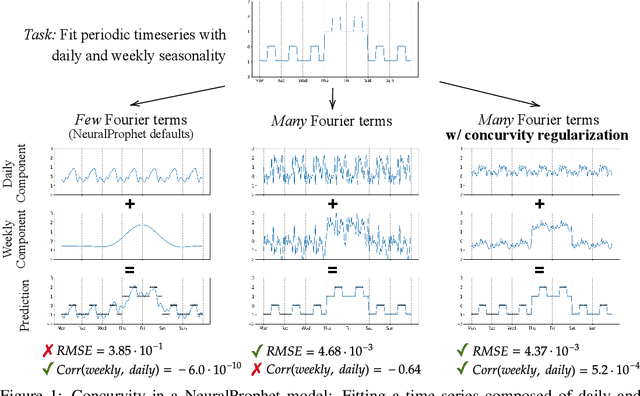

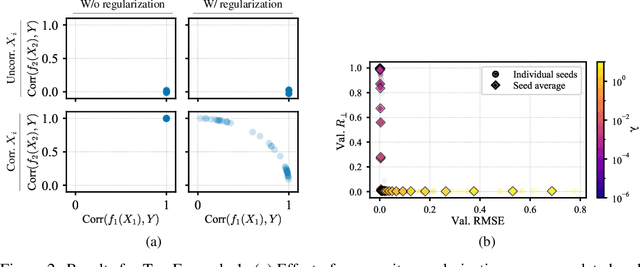
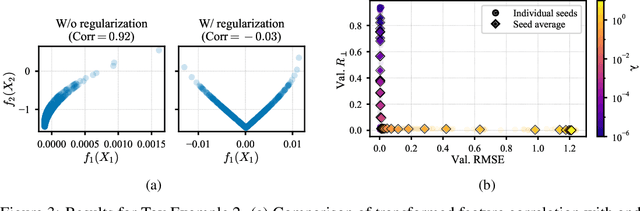
Generalized Additive Models (GAMs) have recently experienced a resurgence in popularity due to their interpretability, which arises from expressing the target value as a sum of non-linear transformations of the features. Despite the current enthusiasm for GAMs, their susceptibility to concurvity - i.e., (possibly non-linear) dependencies between the features - has hitherto been largely overlooked. Here, we demonstrate how concurvity can severly impair the interpretability of GAMs and propose a remedy: a conceptually simple, yet effective regularizer which penalizes pairwise correlations of the non-linearly transformed feature variables. This procedure is applicable to any differentiable additive model, such as Neural Additive Models or NeuralProphet, and enhances interpretability by eliminating ambiguities due to self-canceling feature contributions. We validate the effectiveness of our regularizer in experiments on synthetic as well as real-world datasets for time-series and tabular data. Our experiments show that concurvity in GAMs can be reduced without significantly compromising prediction quality, improving interpretability and reducing variance in the feature importances.
Uncovering the Inner Workings of STEGO for Safe Unsupervised Semantic Segmentation
Apr 14, 2023

Self-supervised pre-training strategies have recently shown impressive results for training general-purpose feature extraction backbones in computer vision. In combination with the Vision Transformer architecture, the DINO self-distillation technique has interesting emerging properties, such as unsupervised clustering in the latent space and semantic correspondences of the produced features without using explicit human-annotated labels. The STEGO method for unsupervised semantic segmentation contrastively distills feature correspondences of a DINO-pre-trained Vision Transformer and recently set a new state of the art. However, the detailed workings of STEGO have yet to be disentangled, preventing its usage in safety-critical applications. This paper provides a deeper understanding of the STEGO architecture and training strategy by conducting studies that uncover the working mechanisms behind STEGO, reproduce and extend its experimental validation, and investigate the ability of STEGO to transfer to different datasets. Results demonstrate that the STEGO architecture can be interpreted as a semantics-preserving dimensionality reduction technique.
Interpretable Reinforcement Learning via Neural Additive Models for Inventory Management
Mar 22, 2023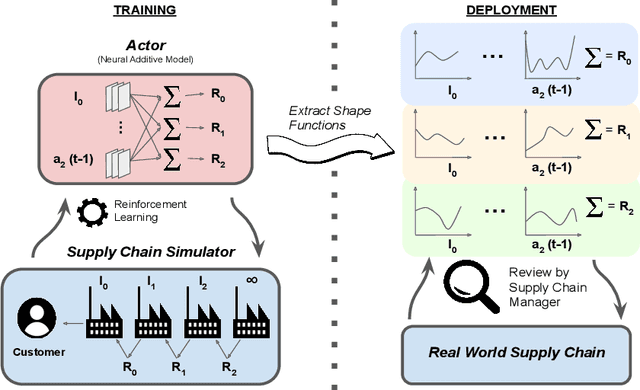
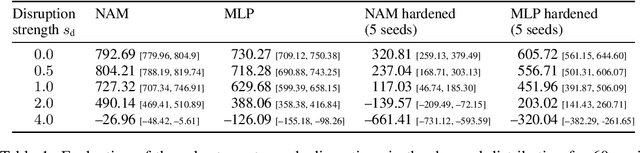
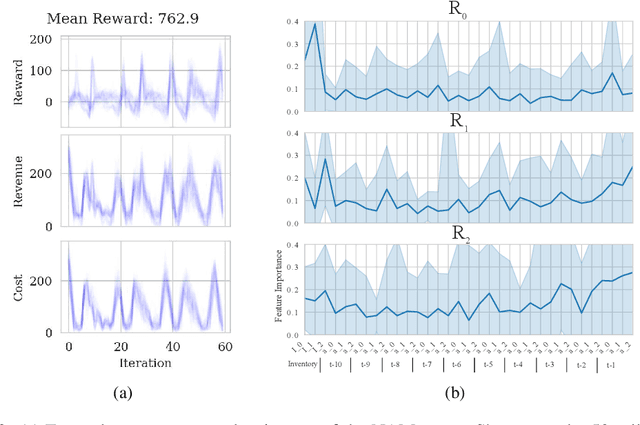
The COVID-19 pandemic has highlighted the importance of supply chains and the role of digital management to react to dynamic changes in the environment. In this work, we focus on developing dynamic inventory ordering policies for a multi-echelon, i.e. multi-stage, supply chain. Traditional inventory optimization methods aim to determine a static reordering policy. Thus, these policies are not able to adjust to dynamic changes such as those observed during the COVID-19 crisis. On the other hand, conventional strategies offer the advantage of being interpretable, which is a crucial feature for supply chain managers in order to communicate decisions to their stakeholders. To address this limitation, we propose an interpretable reinforcement learning approach that aims to be as interpretable as the traditional static policies while being as flexible and environment-agnostic as other deep learning-based reinforcement learning solutions. We propose to use Neural Additive Models as an interpretable dynamic policy of a reinforcement learning agent, showing that this approach is competitive with a standard full connected policy. Finally, we use the interpretability property to gain insights into a complex ordering strategy for a simple, linear three-echelon inventory supply chain.
Spectral Reconstruction and Disparity from Spatio-Spectrally Coded Light Fields via Multi-Task Deep Learning
Mar 18, 2021
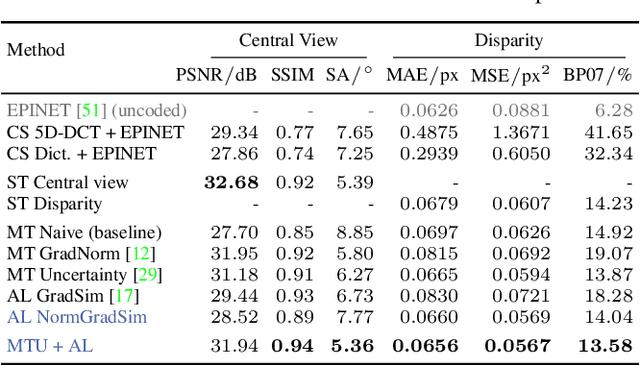
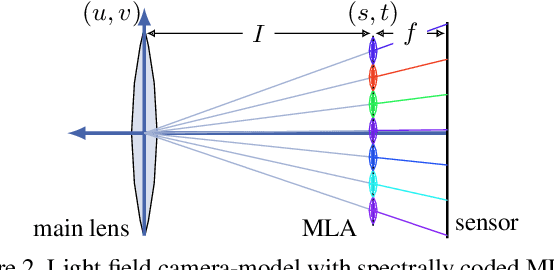
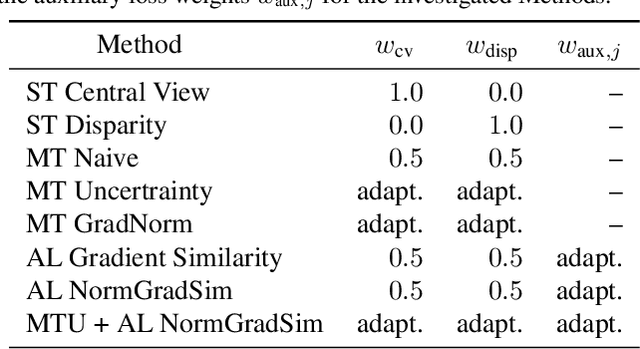
We present a novel method to reconstruct a spectral central view and its aligned disparity map from spatio-spectrally coded light fields. Since we do not reconstruct an intermediate full light field from the coded measurement, we refer to this as principal reconstruction. The coded light fields correspond to those captured by a light field camera in the unfocused design with a spectrally coded microlens array. In this application, the spectrally coded light field camera can be interpreted as a single-shot spectral depth camera. We investigate several multi-task deep learning methods and propose a new auxiliary loss-based training strategy to enhance the reconstruction performance. The results are evaluated using a synthetic as well as a new real-world spectral light field dataset that we captured using a custom-built camera. The results are compared to state-of-the art compressed sensing reconstruction and disparity estimation. We achieve a high reconstruction quality for both synthetic and real-world coded light fields. The disparity estimation quality is on par with or even outperforms state-of-the-art disparity estimation from uncoded RGB light fields.
Microlens array grid estimation, light field decoding, and calibration
Dec 31, 2019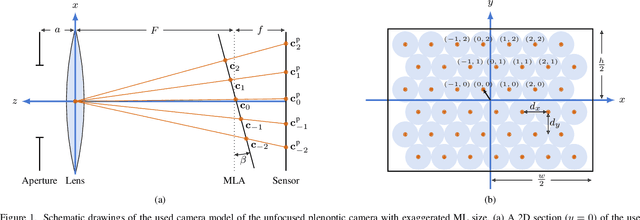

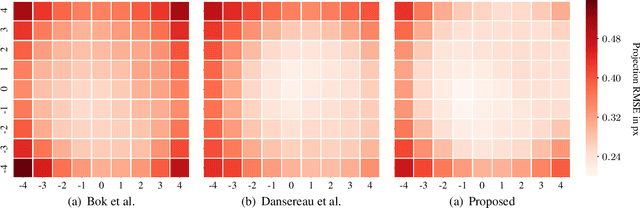

We quantitatively investigate multiple algorithms for microlens array grid estimation for microlens array-based light field cameras. Explicitly taking into account natural and mechanical vignetting effects, we propose a new method for microlens array grid estimation that outperforms the ones previously discussed in the literature. To quantify the performance of the algorithms, we propose an evaluation pipeline utilizing application-specific ray-traced white images with known microlens positions. Using a large dataset of synthesized white images, we thoroughly compare the performance of the different estimation algorithms. As an example, we apply our results to the decoding and calibration of light fields taken with a Lytro Illum camera. We observe that decoding as well as calibration benefit from a more accurate, vignetting-aware grid estimation, especially in peripheral subapertures of the light field.